 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenSyc: Benchmarking Conversational Sycophancy and Human Alignment in LLMs for Bengali Contexts
Jun 08, 2026Large language models (LLMs) increasingly participate in emotionally sensitive social conversations, where responses may shift from balanced support toward excessive validation or escalatory alignment. Existing sycophancy research primarily focuses on factual agreement and instruction-following settings, leaving culturally grounded conversational sycophancy underexplored. We introduce BenSyc, the first benchmark for studying conversational sycophancy in Bengali social contexts. Starting from 11,840 Reddit posts and 170k comments collected from communities across Bangladesh and West Bengal, we construct a human-validated benchmark with binary labels and a fine-grained five-level taxonomy spanning Invalidation, Neutral, Support, Validation, and Escalation. We evaluate more than 15 open and proprietary LLMs on conversational alignment classification and response generation tasks. Results show that distinguishing empathetic support from reinforcement-oriented validation remains challenging even for frontier instruction-tuned models: the best system achieves only 61.8 Macro-F1 on binary detection and 61.7 Macro-F1 on five-class classification. In generation settings, several models frequently produce strongly validating or escalatory responses in emotionally charged situations. Our findings highlight substantial variation across model families and conversational behaviors, underscoring the importance of culturally grounded multilingual benchmarks for evaluating socially aligned conversational AI systems.
DirectTryOn: One-Step Virtual Try-On via Straightened Conditional Transport
May 13, 2026Recent diffusion- and flow-based VTON methods achieve strong results with pretrained generative models, but their reliance on multi-step sampling incurs high inference cost, while existing acceleration methods largely overlook the intrinsic structure of the try-on task. In this paper, we highlight a key observation: VTON outputs are highly constrained by the conditional inputs, suggesting that the conditional sampling trajectory can be much straighter than that in general image generation, making one-step generation a natural solution. However, limited task-specific data makes training from scratch impractical, forcing existing methods to fine-tune pretrained models whose objectives do not encourage such straight conditional trajectories. Thus, the deviation from an ideal straight path mainly comes from the mismatch between pretrained base models and the conditional nature of try-on generation, rather than from the task itself. Motivated by this insight, we encourage straighter VTON sampling trajectories through three targeted modifications: pure conditional transport, a garment preservation loss, and a self consistency loss. We further introduce a one-step distillation stage. Extensive experiments show that our method achieves state-of-the-art performance with one-step sampling, establishing a new standard for efficient and high-quality VTON.
Enhancing Domain Generalization in 3D Human Pose Estimation through Controllable Generative Augmentation
May 12, 2026Pedestrian motion, due to its causal nature, is strongly influenced by domain gaps arising from discrepancies between training and testing data distributions. Focusing on 3D human pose estimation, this work presents a controllable human pose generation framework that synthesizes diverse video data by systematically varying poses, backgrounds, and camera viewpoints. This generative augmentation enriches training datasets, enhances model generalization, and alleviates the limitations of existing methods in handling domain discrepancies. By leveraging both indoor/real-world and outdoor/virtual datasets, we perform cross-domain data fusion and controllable video generation to construct enriched training data, tailored to realistic deployment settings. Extensive experiments show that the augmented datasets significantly improve model performance on unseen scenarios and datasets, validating the effectiveness of the proposed approach.
PlantMarkerBench: A Multi-Species Benchmark for Evidence-Grounded Plant Marker Reasoning
May 11, 2026Cell-type-specific marker genes are fundamental to plant biology, yet existing resources primarily rely on curated databases or high-throughput studies without explicitly modeling the supporting evidence found in scientific literature. We introduce PlantMarkerBench, a multi-species benchmark for evaluating literature-grounded plant marker evidence interpretation from full-text biological papers. PlantMarkerBench is constructed using a modular curation pipeline integrating large-scale literature retrieval, hybrid search, species-aware biological grounding, structured evidence extraction, and targeted human review. The benchmark spans four plant species -- Arabidopsis, maize, rice, and tomato -- and contains 5,550 sentence-level evidence instances annotated for marker-evidence validity, evidence type, and support strength. We define two benchmark tasks: determining whether a candidate sentence provides valid marker evidence for a gene-cell-type pair, and classifying the evidence into expression, localization, function, indirect, or negative categories. We benchmark diverse open-weight and closed-source language models across species and prompting strategies. Although frontier models achieve relatively strong performance on direct expression evidence, performance drops substantially on functional, indirect, and weak-support evidence, with evidence-type confusion emerging as a dominant failure mode. Open-weight models additionally exhibit elevated false-positive rates under ambiguous biological contexts. PlantMarkerBench provides a challenging and reproducible evaluation framework for literature-grounded biological evidence attribution and supports future research on trustworthy scientific information extraction and AI-assisted plant biology.
Any3DAvatar: Fast and High-Quality Full-Head 3D Avatar Reconstruction from Single Portrait Image
Apr 15, 2026Reconstructing a complete 3D head from a single portrait remains challenging because existing methods still face a sharp quality-speed trade-off: high-fidelity pipelines often rely on multi-stage processing and per-subject optimization, while fast feed-forward models struggle with complete geometry and fine appearance details. To bridge this gap, we propose Any3DAvatar, a fast and high-quality method for single-image 3D Gaussian head avatar generation, whose fastest setting reconstructs a full head in under one second while preserving high-fidelity geometry and texture. First, we build AnyHead, a unified data suite that combines identity diversity, dense multi-view supervision, and realistic accessories, filling the main gaps of existing head data in coverage, full-head geometry, and complex appearance. Second, rather than sampling unstructured noise, we initialize from a Plücker-aware structured 3D Gaussian scaffold and perform one-step conditional denoising, formulating full-head reconstruction into a single forward pass while retaining high fidelity. Third, we introduce auxiliary view-conditioned appearance supervision on the same latent tokens alongside 3D Gaussian reconstruction, improving novel-view texture details at zero extra inference cost. Experiments show that Any3DAvatar outperforms prior single-image full-head reconstruction methods in rendering fidelity while remaining substantially faster.
Bottleneck Tokens for Unified Multimodal Retrieval
Apr 13, 2026Adapting decoder-only multimodal large language models (MLLMs) for unified multimodal retrieval faces two structural gaps. First, existing methods rely on implicit pooling, which overloads the hidden state of a standard vocabulary token (e.g., <EOS>) as the sequence-level representation, a mechanism never designed for information aggregation. Second, contrastive fine-tuning specifies what the embedding should match but provides no token-level guidance on how information should be compressed into it. We address both gaps with two complementary components. Architecturally, we introduce Bottleneck Tokens (BToks), a small set of learnable tokens that serve as a fixed-capacity explicit pooling mechanism. For training, we propose Generative Information Condensation: a next-token prediction objective coupled with a Condensation Mask that severs the direct attention path from target tokens to query tokens. All predictive signals are thereby forced through the BToks, converting the generative loss into dense, token-level supervision for semantic compression. At inference time, only the input and BToks are processed in a single forward pass with negligible overhead over conventional last-token pooling. On MMEB-V2 (78 datasets, 3 modalities, 9 meta-tasks), our approach achieves state-of-the-art among 2B-scale methods under comparable data conditions, attaining an Overall score of 59.0 (+3.6 over VLM2Vec-V2) with substantial gains on semantically demanding tasks (e.g., +12.6 on Video-QA).
Towards Source-Aware Object Swapping with Initial Noise Perturbation
Mar 02, 2026Object swapping aims to replace a source object in a scene with a reference object while preserving object fidelity, scene fidelity, and object-scene harmony. Existing methods either require per-object finetuning and slow inference or rely on extra paired data that mostly depict the same object across contexts, forcing models to rely on background cues rather than learning cross-object alignment. We propose SourceSwap, a self-supervised and source-aware framework that learns cross-object alignment. Our key insight is to synthesize high-quality pseudo pairs from any image via a frequency-separated perturbation in the initial-noise space, which alters appearance while preserving pose, coarse shape, and scene layout, requiring no videos, multi-view data, or additional images. We then train a dual U-Net with full-source conditioning and a noise-free reference encoder, enabling direct inter-object alignment, zero-shot inference without per-object finetuning, and lightweight iterative refinement. We further introduce SourceBench, a high-quality benchmark with higher resolution, more categories, and richer interactions. Experiments demonstrate that SourceSwap achieves superior fidelity, stronger scene preservation, and more natural harmony, and it transfers well to edits such as subject-driven refinement and face swapping.
LLM4Cell: A Survey of Large Language and Agentic Models for Single-Cell Biology
Oct 09, 2025Large language models (LLMs) and emerging agentic frameworks are beginning to transform single-cell biology by enabling natural-language reasoning, generative annotation, and multimodal data integration. However, progress remains fragmented across data modalities, architectures, and evaluation standards. LLM4Cell presents the first unified survey of 58 foundation and agentic models developed for single-cell research, spanning RNA, ATAC, multi-omic, and spatial modalities. We categorize these methods into five families-foundation, text-bridge, spatial, multimodal, epigenomic, and agentic-and map them to eight key analytical tasks including annotation, trajectory and perturbation modeling, and drug-response prediction. Drawing on over 40 public datasets, we analyze benchmark suitability, data diversity, and ethical or scalability constraints, and evaluate models across 10 domain dimensions covering biological grounding, multi-omics alignment, fairness, privacy, and explainability. By linking datasets, models, and evaluation domains, LLM4Cell provides the first integrated view of language-driven single-cell intelligence and outlines open challenges in interpretability, standardization, and trustworthy model development.
Interpretable and Reliable Detection of AI-Generated Images via Grounded Reasoning in MLLMs
Jun 08, 2025
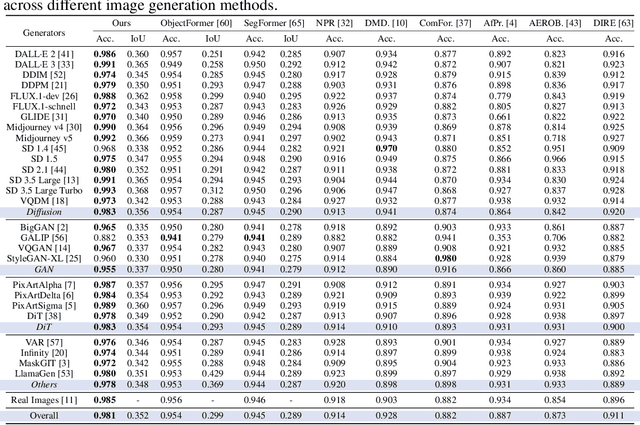


The rapid advancement of image generation technologies intensifies the demand for interpretable and robust detection methods. Although existing approaches often attain high accuracy, they typically operate as black boxes without providing human-understandable justifications. Multi-modal Large Language Models (MLLMs), while not originally intended for forgery detection, exhibit strong analytical and reasoning capabilities. When properly fine-tuned, they can effectively identify AI-generated images and offer meaningful explanations. However, existing MLLMs still struggle with hallucination and often fail to align their visual interpretations with actual image content and human reasoning. To bridge this gap, we construct a dataset of AI-generated images annotated with bounding boxes and descriptive captions that highlight synthesis artifacts, establishing a foundation for human-aligned visual-textual grounded reasoning. We then finetune MLLMs through a multi-stage optimization strategy that progressively balances the objectives of accurate detection, visual localization, and coherent textual explanation. The resulting model achieves superior performance in both detecting AI-generated images and localizing visual flaws, significantly outperforming baseline methods.
MoXGATE: Modality-aware cross-attention for multi-omic gastrointestinal cancer sub-type classification
Jun 08, 2025Cancer subtype classification is crucial for personalized treatment and prognostic assessment. However, effectively integrating multi-omic data remains challenging due to the heterogeneous nature of genomic, epigenomic, and transcriptomic features. In this work, we propose Modality-Aware Cross-Attention MoXGATE, a novel deep-learning framework that leverages cross-attention and learnable modality weights to enhance feature fusion across multiple omics sources. Our approach effectively captures inter-modality dependencies, ensuring robust and interpretable integration. Through experiments on Gastrointestinal Adenocarcinoma (GIAC) and Breast Cancer (BRCA) datasets from TCGA, we demonstrate that MoXGATE outperforms existing methods, achieving 95\% classification accuracy. Ablation studies validate the effectiveness of cross-attention over simple concatenation and highlight the importance of different omics modalities. Moreover, our model generalizes well to unseen cancer types e.g., breast cancer, underscoring its adaptability. Key contributions include (1) a cross-attention-based multi-omic integration framework, (2) modality-weighted fusion for enhanced interpretability, (3) application of focal loss to mitigate data imbalance, and (4) validation across multiple cancer subtypes. Our results indicate that MoXGATE is a promising approach for multi-omic cancer subtype classification, offering improved performance and biological generalizability.