 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Fake Image Detection with Multi-Modal Large Language Models
Apr 19, 2025
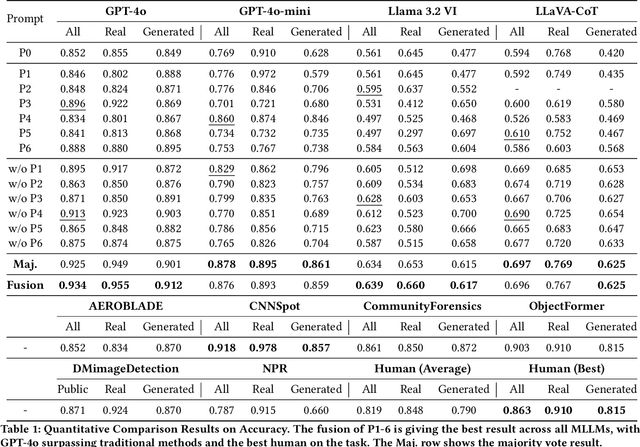

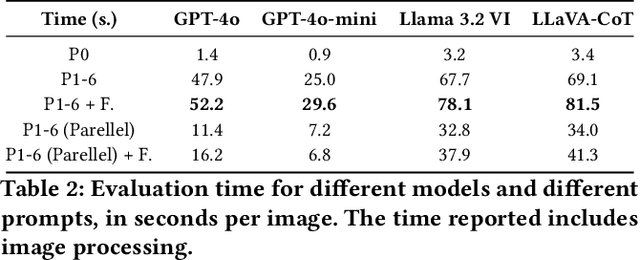
Progress in image generation raises significant public security concerns. We argue that fake image detection should not operate as a "black box". Instead, an ideal approach must ensure both strong generalization and transparency. Recent progress in Multi-modal Large Language Models (MLLMs) offers new opportunities for reasoning-based AI-generated image detection. In this work, we evaluate the capabilities of MLLMs in comparison to traditional detection methods and human evaluators, highlighting their strengths and limitations. Furthermore, we design six distinct prompts and propose a framework that integrates these prompts to develop a more robust, explainable, and reasoning-driven detection system. The code is available at https://github.com/Gennadiyev/mllm-defake.