 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTONGuard: Automatic Detection and Authentication of AI-Generated Virtual Try-On Content
Jan 20, 2026With the rapid advancement of generative AI, virtual try-on (VTON) systems are becoming increasingly common in e-commerce and digital entertainment. However, the growing realism of AI-generated try-on content raises pressing concerns about authenticity and responsible use. To address this, we present VTONGuard, a large-scale benchmark dataset containing over 775,000 real and synthetic try-on images. The dataset covers diverse real-world conditions, including variations in pose, background, and garment styles, and provides both authentic and manipulated examples. Based on this benchmark, we conduct a systematic evaluation of multiple detection paradigms under unified training and testing protocols. Our results reveal each method's strengths and weaknesses and highlight the persistent challenge of cross-paradigm generalization. To further advance detection, we design a multi-task framework that integrates auxiliary segmentation to enhance boundary-aware feature learning, achieving the best overall performance on VTONGuard. We expect this benchmark to enable fair comparisons, facilitate the development of more robust detection models, and promote the safe and responsible deployment of VTON technologies in practice.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Benchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
COCO-Inpaint: A Benchmark for Image Inpainting Detection and Manipulation Localization
Apr 25, 2025
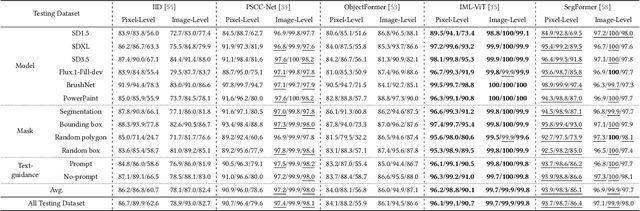


Recent advancements in image manipulation have achieved unprecedented progress in generating photorealistic content, but also simultaneously eliminating barriers to arbitrary manipulation and editing, raising concerns about multimedia authenticity and cybersecurity. However, existing Image Manipulation Detection and Localization (IMDL) methodologies predominantly focus on splicing or copy-move forgeries, lacking dedicated benchmarks for inpainting-based manipulations. To bridge this gap, we present COCOInpaint, a comprehensive benchmark specifically designed for inpainting detection, with three key contributions: 1) High-quality inpainting samples generated by six state-of-the-art inpainting models, 2) Diverse generation scenarios enabled by four mask generation strategies with optional text guidance, and 3) Large-scale coverage with 258,266 inpainted images with rich semantic diversity. Our benchmark is constructed to emphasize intrinsic inconsistencies between inpainted and authentic regions, rather than superficial semantic artifacts such as object shapes. We establish a rigorous evaluation protocol using three standard metrics to assess existing IMDL approaches. The dataset will be made publicly available to facilitate future research in this area.
Towards Explainable Fake Image Detection with Multi-Modal Large Language Models
Apr 19, 2025
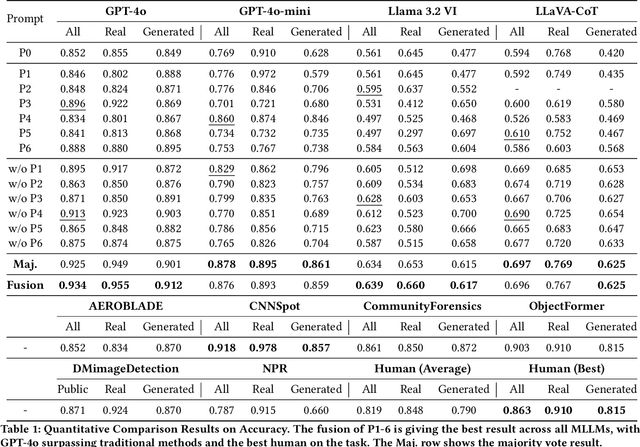

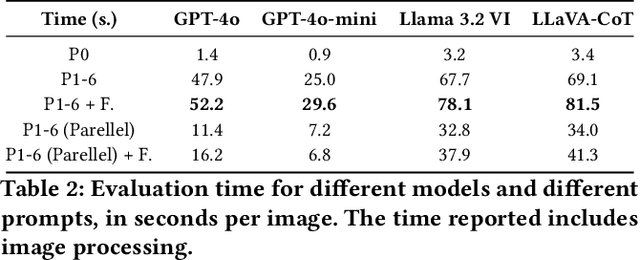
Progress in image generation raises significant public security concerns. We argue that fake image detection should not operate as a "black box". Instead, an ideal approach must ensure both strong generalization and transparency. Recent progress in Multi-modal Large Language Models (MLLMs) offers new opportunities for reasoning-based AI-generated image detection. In this work, we evaluate the capabilities of MLLMs in comparison to traditional detection methods and human evaluators, highlighting their strengths and limitations. Furthermore, we design six distinct prompts and propose a framework that integrates these prompts to develop a more robust, explainable, and reasoning-driven detection system. The code is available at https://github.com/Gennadiyev/mllm-defake.
InterAnimate: Taming Region-aware Diffusion Model for Realistic Human Interaction Animation
Apr 15, 2025Recent video generation research has focused heavily on isolated actions, leaving interactive motions-such as hand-face interactions-largely unexamined. These interactions are essential for emerging biometric authentication systems, which rely on interactive motion-based anti-spoofing approaches. From a security perspective, there is a growing need for large-scale, high-quality interactive videos to train and strengthen authentication models. In this work, we introduce a novel paradigm for animating realistic hand-face interactions. Our approach simultaneously learns spatio-temporal contact dynamics and biomechanically plausible deformation effects, enabling natural interactions where hand movements induce anatomically accurate facial deformations while maintaining collision-free contact. To facilitate this research, we present InterHF, a large-scale hand-face interaction dataset featuring 18 interaction patterns and 90,000 annotated videos. Additionally, we propose InterAnimate, a region-aware diffusion model designed specifically for interaction animation. InterAnimate leverages learnable spatial and temporal latents to effectively capture dynamic interaction priors and integrates a region-aware interaction mechanism that injects these priors into the denoising process. To the best of our knowledge, this work represents the first large-scale effort to systematically study human hand-face interactions. Qualitative and quantitative results show InterAnimate produces highly realistic animations, setting a new benchmark. Code and data will be made public to advance research.
Efficient Transfer Learning for Video-language Foundation Models
Nov 18, 2024



Pre-trained vision-language models provide a robust foundation for efficient transfer learning across various downstream tasks. In the field of video action recognition, mainstream approaches often introduce additional parameter modules to capture temporal information. While the increased model capacity brought by these additional parameters helps better fit the video-specific inductive biases, existing methods require learning a large number of parameters and are prone to catastrophic forgetting of the original generalizable knowledge. In this paper, we propose a simple yet effective Multi-modal Spatio-Temporal Adapter (MSTA) to improve the alignment between representations in the text and vision branches, achieving a balance between general knowledge and task-specific knowledge. Furthermore, to mitigate over-fitting and enhance generalizability, we introduce a spatio-temporal description-guided consistency constraint. This constraint involves feeding template inputs (i.e., ``a video of $\{\textbf{cls}\}$'') into the trainable language branch, while LLM-generated spatio-temporal descriptions are input into the pre-trained language branch, enforcing consistency between the outputs of the two branches. This mechanism prevents over-fitting to downstream tasks and improves the distinguishability of the trainable branch within the spatio-temporal semantic space. We evaluate the effectiveness of our approach across four tasks: zero-shot transfer, few-shot learning, base-to-novel generalization, and fully-supervised learning. Compared to many state-of-the-art methods, our MSTA achieves outstanding performance across all evaluations, while using only 2-7\% of the trainable parameters in the original model. Code will be avaliable at https://github.com/chenhaoxing/ETL4Video.
DomainGallery: Few-shot Domain-driven Image Generation by Attribute-centric Finetuning
Nov 07, 2024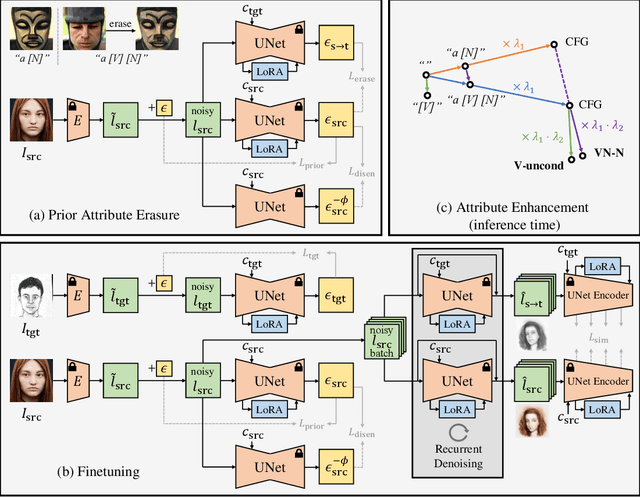
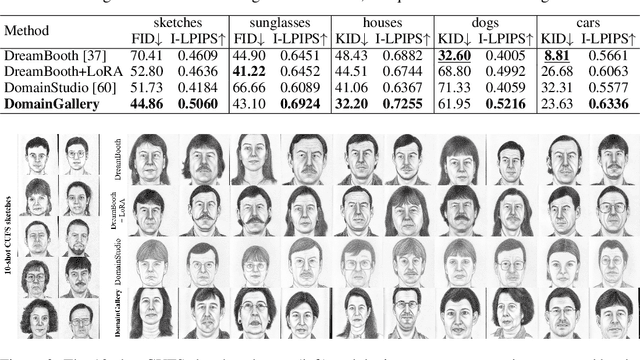


The recent progress in text-to-image models pretrained on large-scale datasets has enabled us to generate various images as long as we provide a text prompt describing what we want. Nevertheless, the availability of these models is still limited when we expect to generate images that fall into a specific domain either hard to describe or just unseen to the models. In this work, we propose DomainGallery, a few-shot domain-driven image generation method which aims at finetuning pretrained Stable Diffusion on few-shot target datasets in an attribute-centric manner. Specifically, DomainGallery features prior attribute erasure, attribute disentanglement, regularization and enhancement. These techniques are tailored to few-shot domain-driven generation in order to solve key issues that previous works have failed to settle. Extensive experiments are given to validate the superior performance of DomainGallery on a variety of domain-driven generation scenarios. Codes are available at https://github.com/Ldhlwh/DomainGallery.
DeMamba: AI-Generated Video Detection on Million-Scale GenVideo Benchmark
May 30, 2024
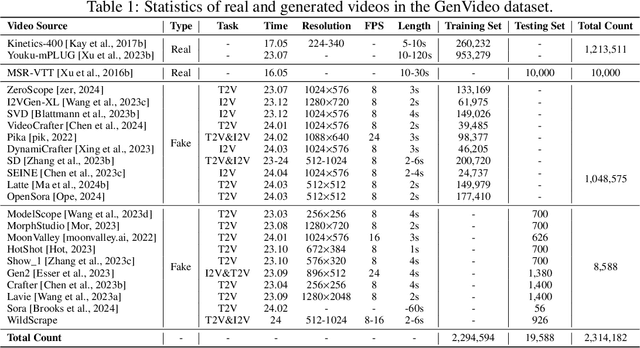
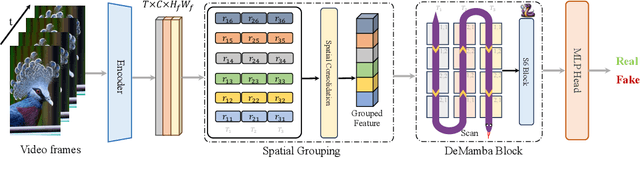
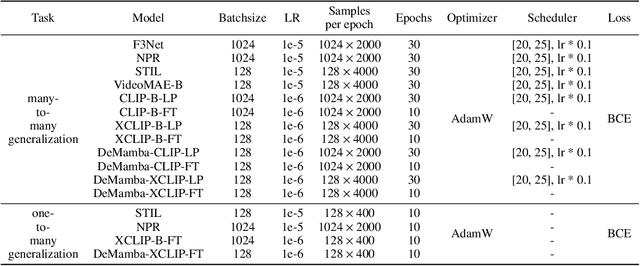
Recently, video generation techniques have advanced rapidly. Given the popularity of video content on social media platforms, these models intensify concerns about the spread of fake information. Therefore, there is a growing demand for detectors capable of distinguishing between fake AI-generated videos and mitigating the potential harm caused by fake information. However, the lack of large-scale datasets from the most advanced video generators poses a barrier to the development of such detectors. To address this gap, we introduce the first AI-generated video detection dataset, GenVideo. It features the following characteristics: (1) a large volume of videos, including over one million AI-generated and real videos collected; (2) a rich diversity of generated content and methodologies, covering a broad spectrum of video categories and generation techniques. We conducted extensive studies of the dataset and proposed two evaluation methods tailored for real-world-like scenarios to assess the detectors' performance: the cross-generator video classification task assesses the generalizability of trained detectors on generators; the degraded video classification task evaluates the robustness of detectors to handle videos that have degraded in quality during dissemination. Moreover, we introduced a plug-and-play module, named Detail Mamba (DeMamba), designed to enhance the detectors by identifying AI-generated videos through the analysis of inconsistencies in temporal and spatial dimensions. Our extensive experiments demonstrate DeMamba's superior generalizability and robustness on GenVideo compared to existing detectors. We believe that the GenVideo dataset and the DeMamba module will significantly advance the field of AI-generated video detection. Our code and dataset will be aviliable at \url{https://github.com/chenhaoxing/DeMamba}.
Supervised Contrastive Learning for Snapshot Spectral Imaging Face Anti-Spoofing
May 29, 2024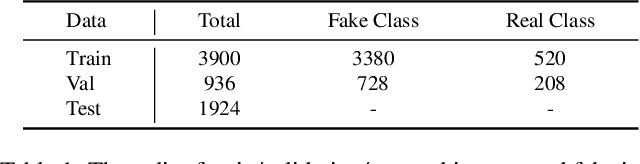

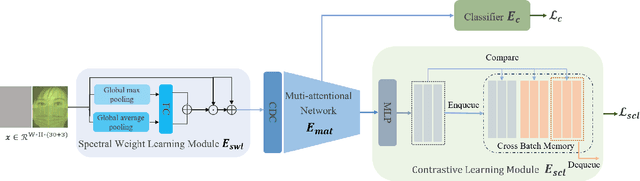
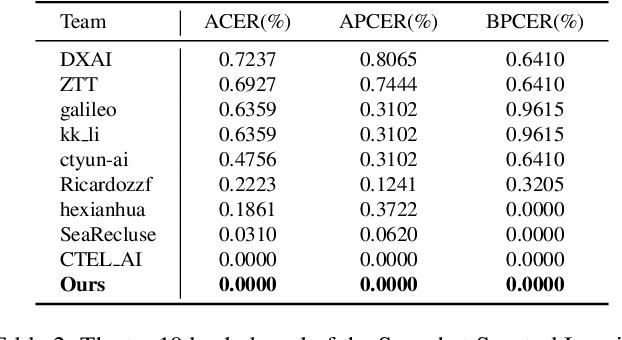
This study reveals a cutting-edge re-balanced contrastive learning strategy aimed at strengthening face anti-spoofing capabilities within facial recognition systems, with a focus on countering the challenges posed by printed photos, and highly realistic silicone or latex masks. Leveraging the HySpeFAS dataset, which benefits from Snapshot Spectral Imaging technology to provide hyperspectral images, our approach harmonizes class-level contrastive learning with data resampling and an innovative real-face oriented reweighting technique. This method effectively mitigates dataset imbalances and reduces identity-related biases. Notably, our strategy achieved an unprecedented 0.0000\% Average Classification Error Rate (ACER) on the HySpeFAS dataset, ranking first at the Chalearn Snapshot Spectral Imaging Face Anti-spoofing Challenge on CVPR 2024.