 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Black Box of Latent Reasoning: An Interpretability-Guided Approach to Intervention
May 31, 2026Latent reasoning enables Large Language Models (LLMs) to perform multi-step inference within continuous hidden states, offering efficiency gains over explicit Chain-of-Thought (CoT). However, the opacity of these continuous thought vectors hinders their reliability and controllability. This paper bridges the gap between mechanistic interpretability and actionable control. We first present a systematic analysis using structural, causal, and geometric probes, revealing that latent vectors encode compressed, faithful representations of reasoning steps, with early vectors acting as critical causal hubs. Building on this, we operationalize these interpretability insights into a suite of training-free, decode-time interventions that refine the latent reasoning process by imposing the identified geometric and semantic priors. Extensive experiments across multiple model scales and diverse task domains demonstrate that our approaches consistently improve reasoning accuracy. Our interpretability-guided interventions consistently unlock latent capabilities and improve reasoning accuracy without any parameter updates.
Breaking Dual Bottlenecks: Evolving Unified Multimodal Models into Self-Adaptive Interleaved Visual Reasoners
May 14, 2026Recent unified models integrate multimodal understanding and generation within a single framework. However, an "understanding-generation gap" persists, where models can capture user intent but often fail to translate this semantic knowledge into precise pixel-level manipulation. This gap results in two bottlenecks in anything-to-image task (X2I): the attention entanglement bottleneck, where blind planning struggles with complex prompts, and the visual refinement bottleneck, where unstructured feedback fails to correct imperfections efficiently. In this paper, we propose a novel framework that empowers unified models to autonomously switch between generation strategies based on instruction complexity and model capability. To achieve this, we construct a hierarchical data pipeline that constructs execution paths across three adaptive modes: direct generation for simple cases, self-reflection for quality refinement, and multi-step planning for decomposing complex scenarios. Building on this pipeline, we contribute a high-quality dataset with over 50,000 samples and implement a two-stage training strategy comprising SFT and RL. Specifically, we design step-wise reasoning rewards to ensure logical consistency and intra-group complexity penalty to prevent redundant computational overhead. Extensive experiments demonstrate that our method outperforms existing baselines on X2I, achieving superior generation fidelity among simple-to-complex instructions. The code is released at https://github.com/WeChatCV/Interleaved_Visual_Reasoner.
Reflection Generation for Composite Image Using Diffusion Model
Apr 02, 2026Image composition involves inserting a foreground object into the background while synthesizing environment-consistent effects such as shadows and reflections. Although shadow generation has been extensively studied, reflection generation remains largely underexplored. In this work, we focus on reflection generation. We inject the prior information of reflection placement and reflection appearance into foundation diffusion model. We also divide reflections into two types and adopt type-aware model design. To support training, we construct the first large-scale object reflection dataset DEROBA. Experiments demonstrate that our method generates reflections that are physically coherent and visually realistic, establishing a new benchmark for reflection generation.
Uni-Classifier: Leveraging Video Diffusion Priors for Universal Guidance Classifier
Mar 20, 2026In practical AI workflows, complex tasks often involve chaining multiple generative models, such as using a video or 3D generation model after a 2D image generator. However, distributional mismatches between the output of upstream models and the expected input of downstream models frequently degrade overall generation quality. To address this issue, we propose Uni-Classifier (Uni-C), a simple yet effective plug-and-play module that leverages video diffusion priors to guide the denoising process of preceding models, thereby aligning their outputs with downstream requirements. Uni-C can also be applied independently to enhance the output quality of individual generative models. Extensive experiments across video and 3D generation tasks demonstrate that Uni-C consistently improves generation quality in both workflow-based and standalone settings, highlighting its versatility and strong generalization capability.
OSInsert: Towards High-authenticity and High-fidelity Image Composition
Feb 23, 2026Generative image composition aims to regenerate the given foreground object in the background image to produce a realistic composite image. Some high-authenticity methods can adjust foreground pose/view to be compatible with background, while some high-fidelity methods can preserve the foreground details accurately. However, existing methods can hardly achieve both goals at the same time. In this work, we propose a two-stage strategy to achieve both goals. In the first stage, we use high-authenticity method to generate reasonable foreground shape, serving as the condition of high-fidelity method in the second stage. The experiments on MureCOM dataset verify the effectiveness of our two-stage strategy. The code and model have been released at https://github.com/bcmi/OSInsert-Image-Composition.
DynaDrag: Dynamic Drag-Style Image Editing by Motion Prediction
Jan 02, 2026To achieve pixel-level image manipulation, drag-style image editing which edits images using points or trajectories as conditions is attracting widespread attention. Most previous methods follow move-and-track framework, in which miss tracking and ambiguous tracking are unavoidable challenging issues. Other methods under different frameworks suffer from various problems like the huge gap between source image and target edited image as well as unreasonable intermediate point which can lead to low editability. To avoid these problems, we propose DynaDrag, the first dragging method under predict-and-move framework. In DynaDrag, Motion Prediction and Motion Supervision are performed iteratively. In each iteration, Motion Prediction first predicts where the handle points should move, and then Motion Supervision drags them accordingly. We also propose to dynamically adjust the valid handle points to further improve the performance. Experiments on face and human datasets showcase the superiority over previous works.
D$^{3}$ToM: Decider-Guided Dynamic Token Merging for Accelerating Diffusion MLLMs
Nov 15, 2025Diffusion-based multimodal large language models (Diffusion MLLMs) have recently demonstrated impressive non-autoregressive generative capabilities across vision-and-language tasks. However, Diffusion MLLMs exhibit substantially slower inference than autoregressive models: Each denoising step employs full bidirectional self-attention over the entire sequence, resulting in cubic decoding complexity that becomes computationally impractical with thousands of visual tokens. To address this challenge, we propose D$^{3}$ToM, a Decider-guided dynamic token merging method that dynamically merges redundant visual tokens at different denoising steps to accelerate inference in Diffusion MLLMs. At each denoising step, D$^{3}$ToM uses decider tokens-the tokens generated in the previous denoising step-to build an importance map over all visual tokens. Then it maintains a proportion of the most salient tokens and merges the remainder through similarity-based aggregation. This plug-and-play module integrates into a single transformer layer, physically shortening the visual token sequence for all subsequent layers without altering model parameters. Moreover, D$^{3}$ToM employs a merge ratio that dynamically varies with each denoising step, aligns with the native decoding process of Diffusion MLLMs, achieving superior performance under equivalent computational budgets. Extensive experiments show that D$^{3}$ToM accelerates inference while preserving competitive performance. The code is released at https://github.com/bcmi/D3ToM-Diffusion-MLLM.
CareCom: Generative Image Composition with Calibrated Reference Features
Nov 14, 2025Image composition aims to seamlessly insert foreground object into background. Despite the huge progress in generative image composition, the existing methods are still struggling with simultaneous detail preservation and foreground pose/view adjustment. To address this issue, we extend the existing generative composition model to multi-reference version, which allows using arbitrary number of foreground reference images. Furthermore, we propose to calibrate the global and local features of foreground reference images to make them compatible with the background information. The calibrated reference features can supplement the original reference features with useful global and local information of proper pose/view. Extensive experiments on MVImgNet and MureCom demonstrate that the generative model can greatly benefit from the calibrated reference features.
$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025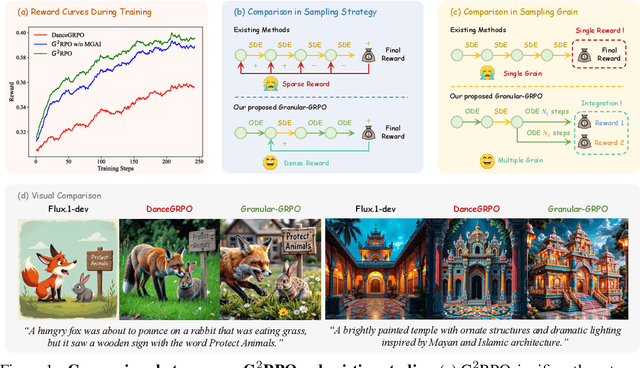
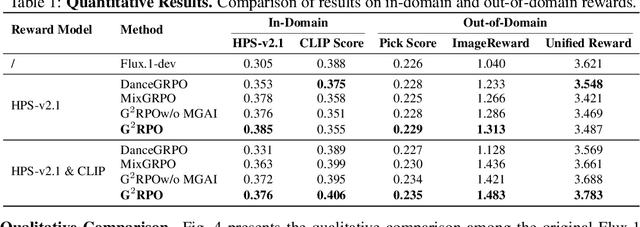
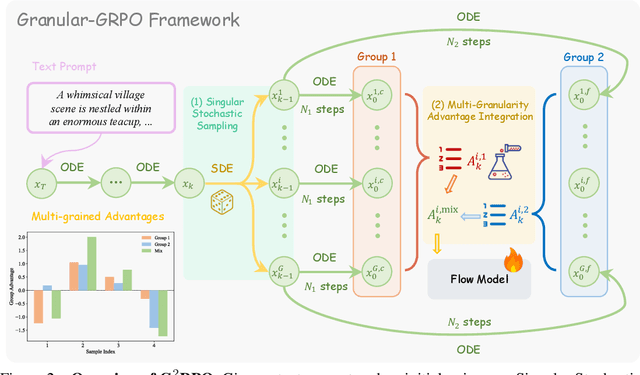
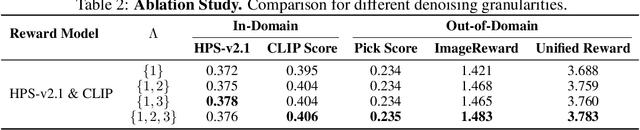
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.
Unsupervised Exposure Correction
Jul 23, 2025Current exposure correction methods have three challenges, labor-intensive paired data annotation, limited generalizability, and performance degradation in low-level computer vision tasks. In this work, we introduce an innovative Unsupervised Exposure Correction (UEC) method that eliminates the need for manual annotations, offers improved generalizability, and enhances performance in low-level downstream tasks. Our model is trained using freely available paired data from an emulated Image Signal Processing (ISP) pipeline. This approach does not need expensive manual annotations, thereby minimizing individual style biases from the annotation and consequently improving its generalizability. Furthermore, we present a large-scale Radiometry Correction Dataset, specifically designed to emphasize exposure variations, to facilitate unsupervised learning. In addition, we develop a transformation function that preserves image details and outperforms state-of-the-art supervised methods [12], while utilizing only 0.01% of their parameters. Our work further investigates the broader impact of exposure correction on downstream tasks, including edge detection, demonstrating its effectiveness in mitigating the adverse effects of poor exposure on low-level features. The source code and dataset are publicly available at https://github.com/BeyondHeaven/uec_code.