 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflection Generation for Composite Image Using Diffusion Model
Apr 02, 2026Image composition involves inserting a foreground object into the background while synthesizing environment-consistent effects such as shadows and reflections. Although shadow generation has been extensively studied, reflection generation remains largely underexplored. In this work, we focus on reflection generation. We inject the prior information of reflection placement and reflection appearance into foundation diffusion model. We also divide reflections into two types and adopt type-aware model design. To support training, we construct the first large-scale object reflection dataset DEROBA. Experiments demonstrate that our method generates reflections that are physically coherent and visually realistic, establishing a new benchmark for reflection generation.
LifeBench: A Benchmark for Long-Horizon Multi-Source Memory
Mar 04, 2026Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2\% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
LLM-based Embeddings: Attention Values Encode Sentence Semantics Better Than Hidden States
Feb 02, 2026Sentence representations are foundational to many Natural Language Processing (NLP) applications. While recent methods leverage Large Language Models (LLMs) to derive sentence representations, most rely on final-layer hidden states, which are optimized for next-token prediction and thus often fail to capture global, sentence-level semantics. This paper introduces a novel perspective, demonstrating that attention value vectors capture sentence semantics more effectively than hidden states. We propose Value Aggregation (VA), a simple method that pools token values across multiple layers and token indices. In a training-free setting, VA outperforms other LLM-based embeddings, even matches or surpasses the ensemble-based MetaEOL. Furthermore, we demonstrate that when paired with suitable prompts, the layer attention outputs can be interpreted as aligned weighted value vectors. Specifically, the attention scores of the last token function as the weights, while the output projection matrix ($W_O$) aligns these weighted value vectors with the common space of the LLM residual stream. This refined method, termed Aligned Weighted VA (AlignedWVA), achieves state-of-the-art performance among training-free LLM-based embeddings, outperforming the high-cost MetaEOL by a substantial margin. Finally, we highlight the potential of obtaining strong LLM embedding models through fine-tuning Value Aggregation.
CareCom: Generative Image Composition with Calibrated Reference Features
Nov 14, 2025Image composition aims to seamlessly insert foreground object into background. Despite the huge progress in generative image composition, the existing methods are still struggling with simultaneous detail preservation and foreground pose/view adjustment. To address this issue, we extend the existing generative composition model to multi-reference version, which allows using arbitrary number of foreground reference images. Furthermore, we propose to calibrate the global and local features of foreground reference images to make them compatible with the background information. The calibrated reference features can supplement the original reference features with useful global and local information of proper pose/view. Extensive experiments on MVImgNet and MureCom demonstrate that the generative model can greatly benefit from the calibrated reference features.
Human-like Cognitive Generalization for Large Models via Brain-in-the-loop Supervision
May 14, 2025Recent advancements in deep neural networks (DNNs), particularly large-scale language models, have demonstrated remarkable capabilities in image and natural language understanding. Although scaling up model parameters with increasing volume of training data has progressively improved DNN capabilities, achieving complex cognitive abilities - such as understanding abstract concepts, reasoning, and adapting to novel scenarios, which are intrinsic to human cognition - remains a major challenge. In this study, we show that brain-in-the-loop supervised learning, utilizing a small set of brain signals, can effectively transfer human conceptual structures to DNNs, significantly enhancing their comprehension of abstract and even unseen concepts. Experimental results further indicate that the enhanced cognitive capabilities lead to substantial performance gains in challenging tasks, including few-shot/zero-shot learning and out-of-distribution recognition, while also yielding highly interpretable concept representations. These findings highlight that human-in-the-loop supervision can effectively augment the complex cognitive abilities of large models, offering a promising pathway toward developing more human-like cognitive abilities in artificial systems.
MureObjectStitch: Multi-reference Image Composition
Nov 12, 2024



Generative image composition aims to regenerate the given foreground object in the background image to produce a realistic composite image. In this work, we propose an effective finetuning strategy for generative image composition model, in which we finetune a pretrained model using one or more images containing the same foreground object. Moreover, we propose a multi-reference strategy, which allows the model to take in multiple reference images of the foreground object. The experiments on MureCOM dataset verify the effectiveness of our method.
A Single Simple Patch is All You Need for AI-generated Image Detection
Feb 02, 2024



The recent development of generative models unleashes the potential of generating hyper-realistic fake images. To prevent the malicious usage of fake images, AI-generated image detection aims to distinguish fake images from real images. Nevertheless, existing methods usually suffer from poor generalizability across different generators. In this work, we propose an embarrassingly simple approach named SSP, i.e., feeding the noise pattern of a Single Simple Patch (SSP) to a binary classifier, which could achieve 14.6% relative improvement over the recent method on GenImage dataset. Our SSP method is very robust and generalizable, which could serve as a simple and competitive baseline for the future methods.
MindGPT: Interpreting What You See with Non-invasive Brain Recordings
Sep 27, 2023



Decoding of seen visual contents with non-invasive brain recordings has important scientific and practical values. Efforts have been made to recover the seen images from brain signals. However, most existing approaches cannot faithfully reflect the visual contents due to insufficient image quality or semantic mismatches. Compared with reconstructing pixel-level visual images, speaking is a more efficient and effective way to explain visual information. Here we introduce a non-invasive neural decoder, termed as MindGPT, which interprets perceived visual stimuli into natural languages from fMRI signals. Specifically, our model builds upon a visually guided neural encoder with a cross-attention mechanism, which permits us to guide latent neural representations towards a desired language semantic direction in an end-to-end manner by the collaborative use of the large language model GPT. By doing so, we found that the neural representations of the MindGPT are explainable, which can be used to evaluate the contributions of visual properties to language semantics. Our experiments show that the generated word sequences truthfully represented the visual information (with essential details) conveyed in the seen stimuli. The results also suggested that with respect to language decoding tasks, the higher visual cortex (HVC) is more semantically informative than the lower visual cortex (LVC), and using only the HVC can recover most of the semantic information. The code of the MindGPT model will be publicly available at https://github.com/JxuanC/MindGPT.
InterFace:Adjustable Angular Margin Inter-class Loss for Deep Face Recognition
Oct 09, 2022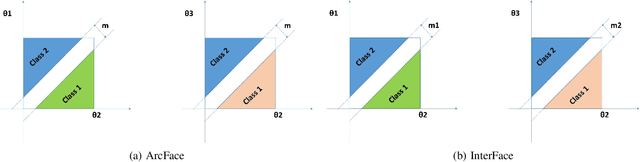
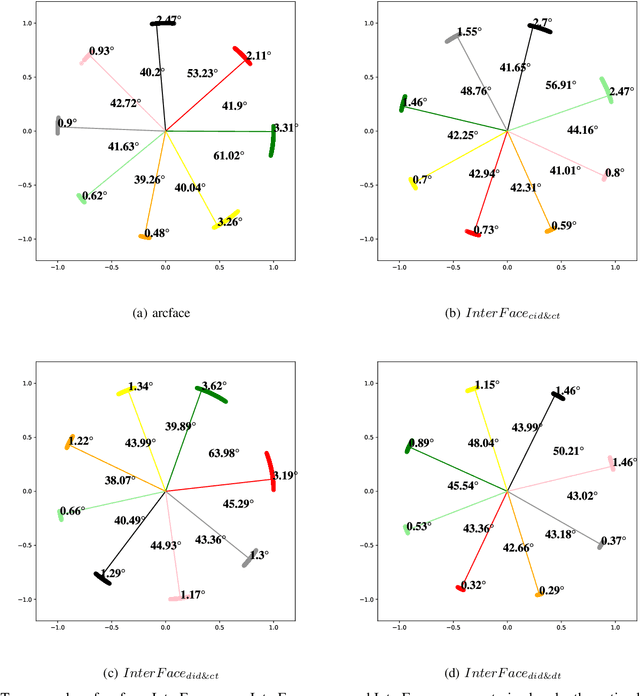

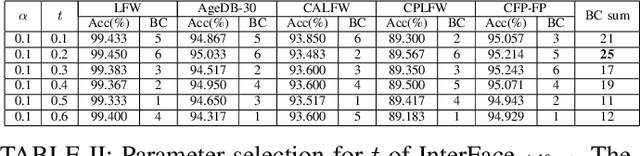
In the field of face recognition, it is always a hot research topic to improve the loss solution to make the face features extracted by the network have greater discriminative power. Research works in recent years has improved the discriminative power of the face model by normalizing softmax to the cosine space step by step and then adding a fixed penalty margin to reduce the intra-class distance to increase the inter-class distance. Although a great deal of previous work has been done to optimize the boundary penalty to improve the discriminative power of the model, adding a fixed margin penalty to the depth feature and the corresponding weight is not consistent with the pattern of data in the real scenario. To address this issue, in this paper, we propose a novel loss function, InterFace, releasing the constraint of adding a margin penalty only between the depth feature and the corresponding weight to push the separability of classes by adding corresponding margin penalties between the depth features and all weights. To illustrate the advantages of InterFace over a fixed penalty margin, we explained geometrically and comparisons on a set of mainstream benchmarks. From a wider perspective, our InterFace has advanced the state-of-the-art face recognition performance on five out of thirteen mainstream benchmarks. All training codes, pre-trained models, and training logs, are publicly released \footnote{$https://github.com/iamsangmeng/InterFace$}.
Hybrid Multisource Feature Fusion for the Text Clustering
Aug 24, 2021
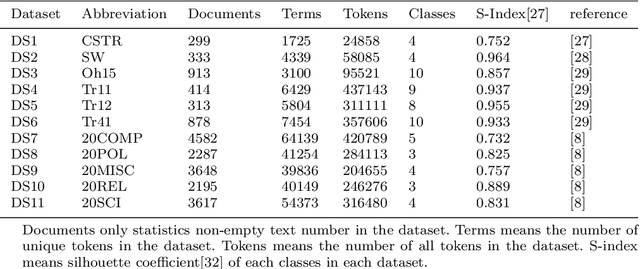
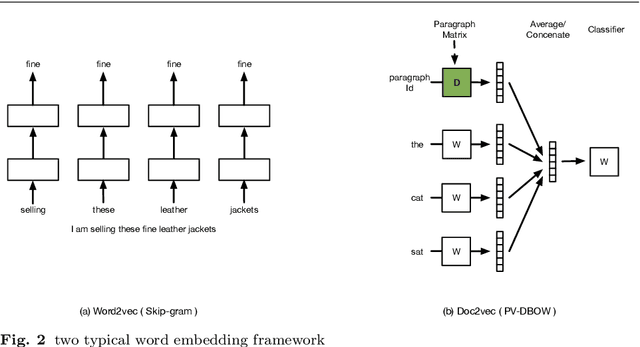

The text clustering technique is an unsupervised text mining method which are used to partition a huge amount of text documents into groups. It has been reported that text clustering algorithms are hard to achieve better performance than supervised methods and their clustering performance is highly dependent on the picked text features. Currently, there are many different types of text feature generation algorithms, each of which extracts text features from some specific aspects, such as VSM and distributed word embedding, thus seeking a new way of obtaining features as complete as possible from the corpus is the key to enhance the clustering effects. In this paper, we present a hybrid multisource feature fusion (HMFF) framework comprising three components, feature representation of multimodel, mutual similarity matrices and feature fusion, in which we construct mutual similarity matrices for each feature source and fuse discriminative features from mutual similarity matrices by reducing dimensionality to generate HMFF features, then k-means clustering algorithm could be configured to partition input samples into groups. The experimental tests show our HMFF framework outperforms other recently published algorithms on 7 of 11 public benchmark datasets and has the leading performance on the rest 4 benchmark datasets as well. At last, we compare HMFF framework with those competitors on a COVID-19 dataset from the wild with the unknown cluster count, which shows the clusters generated by HMFF framework partition those similar samples much closer.