 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-Trans-Enc: A CNN-Enhanced Transformer-Encoder On Top Of Static BERT representations for Document Classification
Sep 13, 2022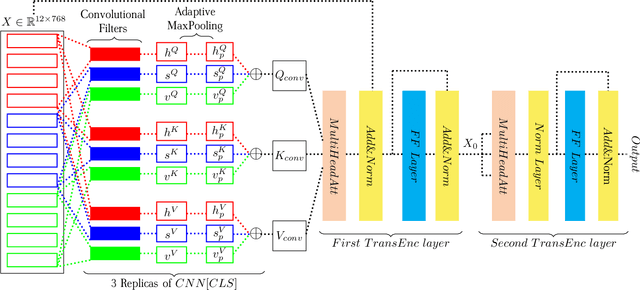

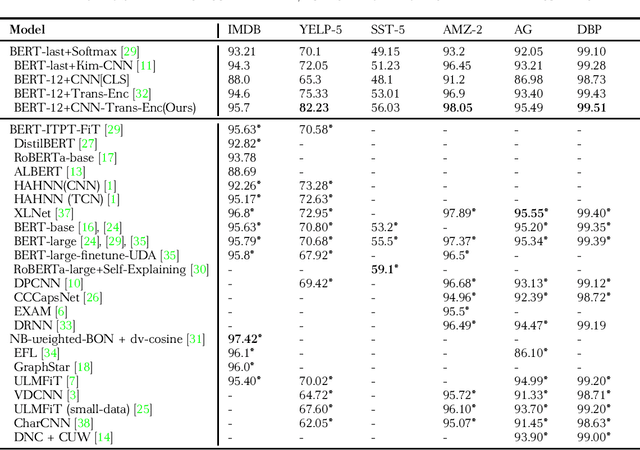
BERT achieves remarkable results in text classification tasks, it is yet not fully exploited, since only the last layer is used as a representation output for downstream classifiers. The most recent studies on the nature of linguistic features learned by BERT, suggest that different layers focus on different kinds of linguistic features. We propose a CNN-Enhanced Transformer-Encoder model which is trained on top of fixed BERT $[CLS]$ representations from all layers, employing Convolutional Neural Networks to generate QKV feature maps inside the Transformer-Encoder, instead of linear projections of the input into the embedding space. CNN-Trans-Enc is relatively small as a downstream classifier and doesn't require any fine-tuning of BERT, as it ensures an optimal use of the $[CLS]$ representations from all layers, leveraging different linguistic features with more meaningful, and generalizable QKV representations of the input. Using BERT with CNN-Trans-Enc keeps $98.9\%$ and $94.8\%$ of current state-of-the-art performance on the IMDB and SST-5 datasets respectably, while obtaining new state-of-the-art on YELP-5 with $82.23$ ($8.9\%$ improvement), and on Amazon-Polarity with $0.98\%$ ($0.2\%$ improvement) (K-fold Cross Validation on a 1M sample subset from both datasets). On the AG news dataset CNN-Trans-Enc achieves $99.94\%$ of the current state-of-the-art, and achieves a new top performance with an average accuracy of $99.51\%$ on DBPedia-14. Index terms: Text Classification, Natural Language Processing, Convolutional Neural Networks, Transformers, BERT
Hybrid Multisource Feature Fusion for the Text Clustering
Aug 24, 2021
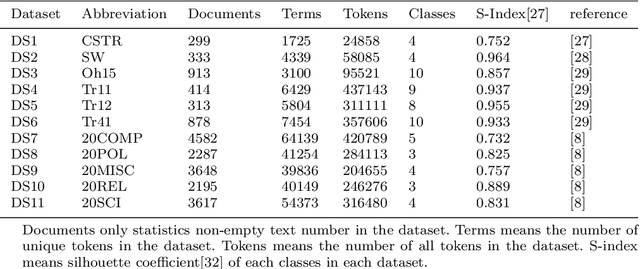
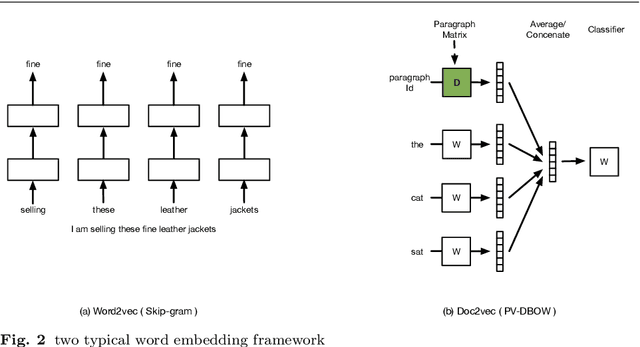

The text clustering technique is an unsupervised text mining method which are used to partition a huge amount of text documents into groups. It has been reported that text clustering algorithms are hard to achieve better performance than supervised methods and their clustering performance is highly dependent on the picked text features. Currently, there are many different types of text feature generation algorithms, each of which extracts text features from some specific aspects, such as VSM and distributed word embedding, thus seeking a new way of obtaining features as complete as possible from the corpus is the key to enhance the clustering effects. In this paper, we present a hybrid multisource feature fusion (HMFF) framework comprising three components, feature representation of multimodel, mutual similarity matrices and feature fusion, in which we construct mutual similarity matrices for each feature source and fuse discriminative features from mutual similarity matrices by reducing dimensionality to generate HMFF features, then k-means clustering algorithm could be configured to partition input samples into groups. The experimental tests show our HMFF framework outperforms other recently published algorithms on 7 of 11 public benchmark datasets and has the leading performance on the rest 4 benchmark datasets as well. At last, we compare HMFF framework with those competitors on a COVID-19 dataset from the wild with the unknown cluster count, which shows the clusters generated by HMFF framework partition those similar samples much closer.