 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-Trans-Enc: A CNN-Enhanced Transformer-Encoder On Top Of Static BERT representations for Document Classification
Sep 13, 2022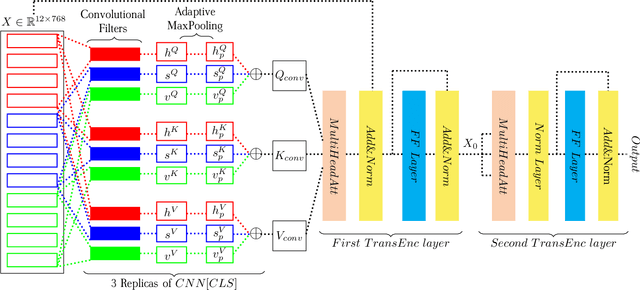
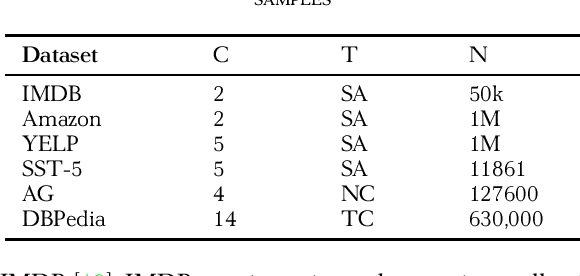

BERT achieves remarkable results in text classification tasks, it is yet not fully exploited, since only the last layer is used as a representation output for downstream classifiers. The most recent studies on the nature of linguistic features learned by BERT, suggest that different layers focus on different kinds of linguistic features. We propose a CNN-Enhanced Transformer-Encoder model which is trained on top of fixed BERT $[CLS]$ representations from all layers, employing Convolutional Neural Networks to generate QKV feature maps inside the Transformer-Encoder, instead of linear projections of the input into the embedding space. CNN-Trans-Enc is relatively small as a downstream classifier and doesn't require any fine-tuning of BERT, as it ensures an optimal use of the $[CLS]$ representations from all layers, leveraging different linguistic features with more meaningful, and generalizable QKV representations of the input. Using BERT with CNN-Trans-Enc keeps $98.9\%$ and $94.8\%$ of current state-of-the-art performance on the IMDB and SST-5 datasets respectably, while obtaining new state-of-the-art on YELP-5 with $82.23$ ($8.9\%$ improvement), and on Amazon-Polarity with $0.98\%$ ($0.2\%$ improvement) (K-fold Cross Validation on a 1M sample subset from both datasets). On the AG news dataset CNN-Trans-Enc achieves $99.94\%$ of the current state-of-the-art, and achieves a new top performance with an average accuracy of $99.51\%$ on DBPedia-14. Index terms: Text Classification, Natural Language Processing, Convolutional Neural Networks, Transformers, BERT
Classifying Textual Data with Pre-trained Vision Models through Transfer Learning and Data Transformations
Jun 23, 2021


Knowledge is acquired by humans through experience, and no boundary is set between the kinds of knowledge or skill levels we can achieve on different tasks at the same time. When it comes to Neural Networks, that is not the case, the major breakthroughs in the field are extremely task and domain specific. Vision and language are dealt with in separate manners, using separate methods and different datasets. In this work, we propose to use knowledge acquired by benchmark Vision Models which are trained on ImageNet to help a much smaller architecture learn to classify text. After transforming the textual data contained in the IMDB dataset to gray scale images. An analysis of different domains and the Transfer Learning method is carried out. Despite the challenge posed by the very different datasets, promising results are achieved. The main contribution of this work is a novel approach which links large pretrained models on both language and vision to achieve state-of-the-art results in different sub-fields from the original task. Without needing high compute capacity resources. Specifically, Sentiment Analysis is achieved after transferring knowledge between vision and language models. BERT embeddings are transformed into grayscale images, these images are then used as training examples for pretrained vision models such as VGG16 and ResNet Index Terms: Natural language, Vision, BERT, Transfer Learning, CNN, Domain Adaptation.