 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Multisource Feature Fusion for the Text Clustering
Paper and Code
Aug 24, 2021
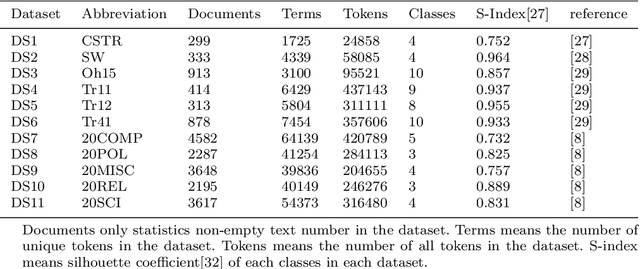

The text clustering technique is an unsupervised text mining method which are used to partition a huge amount of text documents into groups. It has been reported that text clustering algorithms are hard to achieve better performance than supervised methods and their clustering performance is highly dependent on the picked text features. Currently, there are many different types of text feature generation algorithms, each of which extracts text features from some specific aspects, such as VSM and distributed word embedding, thus seeking a new way of obtaining features as complete as possible from the corpus is the key to enhance the clustering effects. In this paper, we present a hybrid multisource feature fusion (HMFF) framework comprising three components, feature representation of multimodel, mutual similarity matrices and feature fusion, in which we construct mutual similarity matrices for each feature source and fuse discriminative features from mutual similarity matrices by reducing dimensionality to generate HMFF features, then k-means clustering algorithm could be configured to partition input samples into groups. The experimental tests show our HMFF framework outperforms other recently published algorithms on 7 of 11 public benchmark datasets and has the leading performance on the rest 4 benchmark datasets as well. At last, we compare HMFF framework with those competitors on a COVID-19 dataset from the wild with the unknown cluster count, which shows the clusters generated by HMFF framework partition those similar samples much closer.