 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParkGaussian: Surround-view 3D Gaussian Splatting for Autonomous Parking
Jan 04, 2026Parking is a critical task for autonomous driving systems (ADS), with unique challenges in crowded parking slots and GPS-denied environments. However, existing works focus on 2D parking slot perception, mapping, and localization, 3D reconstruction remains underexplored, which is crucial for capturing complex spatial geometry in parking scenarios. Naively improving the visual quality of reconstructed parking scenes does not directly benefit autonomous parking, as the key entry point for parking is the slots perception module. To address these limitations, we curate the first benchmark named ParkRecon3D, specifically designed for parking scene reconstruction. It includes sensor data from four surround-view fisheye cameras with calibrated extrinsics and dense parking slot annotations. We then propose ParkGaussian, the first framework that integrates 3D Gaussian Splatting (3DGS) for parking scene reconstruction. To further improve the alignment between reconstruction and downstream parking slot detection, we introduce a slot-aware reconstruction strategy that leverages existing parking perception methods to enhance the synthesis quality of slot regions. Experiments on ParkRecon3D demonstrate that ParkGaussian achieves state-of-the-art reconstruction quality and better preserves perception consistency for downstream tasks. The code and dataset will be released at: https://github.com/wm-research/ParkGaussian
ExEBench: Benchmarking Foundation Models on Extreme Earth Events
May 13, 2025Our planet is facing increasingly frequent extreme events, which pose major risks to human lives and ecosystems. Recent advances in machine learning (ML), especially with foundation models (FMs) trained on extensive datasets, excel in extracting features and show promise in disaster management. Nevertheless, these models often inherit biases from training data, challenging their performance over extreme values. To explore the reliability of FM in the context of extreme events, we introduce \textbf{ExE}Bench (\textbf{Ex}treme \textbf{E}arth Benchmark), a collection of seven extreme event categories across floods, wildfires, storms, tropical cyclones, extreme precipitation, heatwaves, and cold waves. The dataset features global coverage, varying data volumes, and diverse data sources with different spatial, temporal, and spectral characteristics. To broaden the real-world impact of FMs, we include multiple challenging ML tasks that are closely aligned with operational needs in extreme events detection, monitoring, and forecasting. ExEBench aims to (1) assess FM generalizability across diverse, high-impact tasks and domains, (2) promote the development of novel ML methods that benefit disaster management, and (3) offer a platform for analyzing the interactions and cascading effects of extreme events to advance our understanding of Earth system, especially under the climate change expected in the decades to come. The dataset and code are public https://github.com/zhaoshan2/EarthExtreme-Bench.
MOSABench: Multi-Object Sentiment Analysis Benchmark for Evaluating Multimodal Large Language Models Understanding of Complex Image
Nov 25, 2024



Multimodal large language models (MLLMs) have shown remarkable progress in high-level semantic tasks such as visual question answering, image captioning, and emotion recognition. However, despite advancements, there remains a lack of standardized benchmarks for evaluating MLLMs performance in multi-object sentiment analysis, a key task in semantic understanding. To address this gap, we introduce MOSABench, a novel evaluation dataset designed specifically for multi-object sentiment analysis. MOSABench includes approximately 1,000 images with multiple objects, requiring MLLMs to independently assess the sentiment of each object, thereby reflecting real-world complexities. Key innovations in MOSABench include distance-based target annotation, post-processing for evaluation to standardize outputs, and an improved scoring mechanism. Our experiments reveal notable limitations in current MLLMs: while some models, like mPLUG-owl and Qwen-VL2, demonstrate effective attention to sentiment-relevant features, others exhibit scattered focus and performance declines, especially as the spatial distance between objects increases. This research underscores the need for MLLMs to enhance accuracy in complex, multi-object sentiment analysis tasks and establishes MOSABench as a foundational tool for advancing sentiment analysis capabilities in MLLMs.
Beyond Grid Data: Exploring Graph Neural Networks for Earth Observation
Nov 05, 2024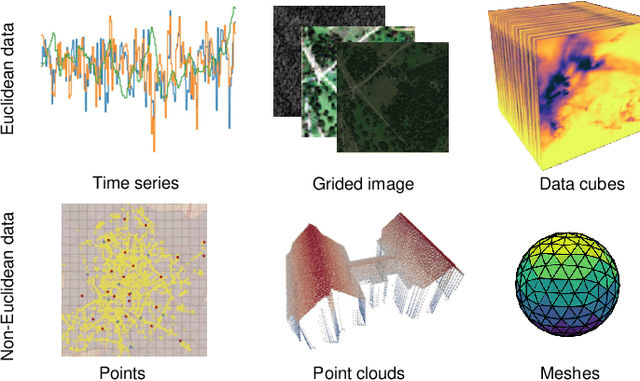
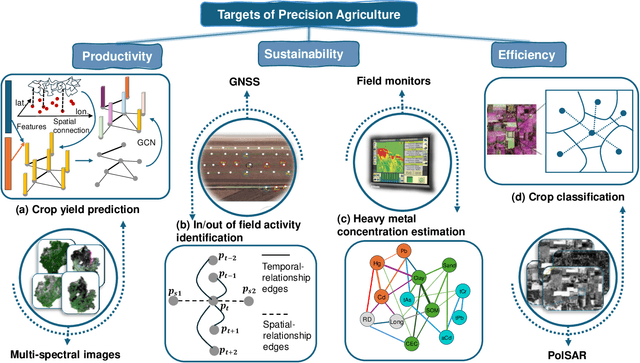

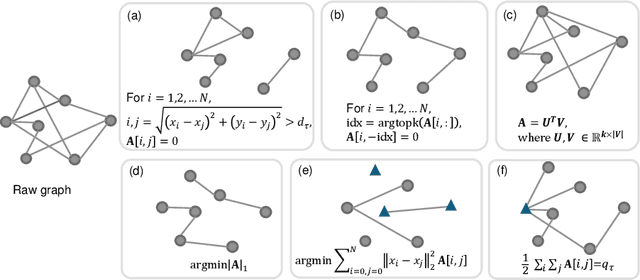
Earth Observation (EO) data analysis has been significantly revolutionized by deep learning (DL), with applications typically limited to grid-like data structures. Graph Neural Networks (GNNs) emerge as an important innovation, propelling DL into the non-Euclidean domain. Naturally, GNNs can effectively tackle the challenges posed by diverse modalities, multiple sensors, and the heterogeneous nature of EO data. To introduce GNNs in the related domains, our review begins by offering fundamental knowledge on GNNs. Then, we summarize the generic problems in EO, to which GNNs can offer potential solutions. Following this, we explore a broad spectrum of GNNs' applications to scientific problems in Earth systems, covering areas such as weather and climate analysis, disaster management, air quality monitoring, agriculture, land cover classification, hydrological process modeling, and urban modeling. The rationale behind adopting GNNs in these fields is explained, alongside methodologies for organizing graphs and designing favorable architectures for various tasks. Furthermore, we highlight methodological challenges of implementing GNNs in these domains and possible solutions that could guide future research. While acknowledging that GNNs are not a universal solution, we conclude the paper by comparing them with other popular architectures like transformers and analyzing their potential synergies.
PTA: Enhancing Multimodal Sentiment Analysis through Pipelined Prediction and Translation-based Alignment
May 23, 2024
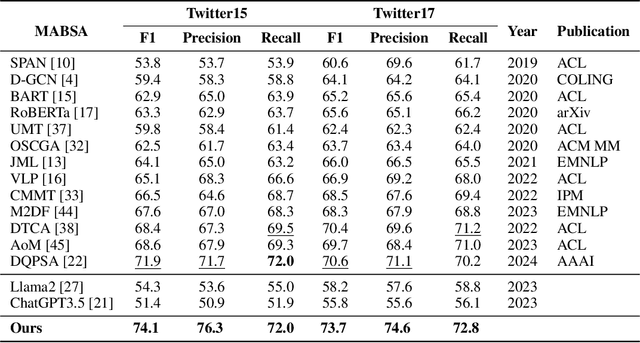


Multimodal aspect-based sentiment analysis (MABSA) aims to understand opinions in a granular manner, advancing human-computer interaction and other fields. Traditionally, MABSA methods use a joint prediction approach to identify aspects and sentiments simultaneously. However, we argue that joint models are not always superior. Our analysis shows that joint models struggle to align relevant text tokens with image patches, leading to misalignment and ineffective image utilization. In contrast, a pipeline framework first identifies aspects through MATE (Multimodal Aspect Term Extraction) and then aligns these aspects with image patches for sentiment classification (MASC: Multimodal Aspect-Oriented Sentiment Classification). This method is better suited for multimodal scenarios where effective image use is crucial. We present three key observations: (a) MATE and MASC have different feature requirements, with MATE focusing on token-level features and MASC on sequence-level features; (b) the aspect identified by MATE is crucial for effective image utilization; and (c) images play a trivial role in previous MABSA methods due to high noise. Based on these observations, we propose a pipeline framework that first predicts the aspect and then uses translation-based alignment (TBA) to enhance multimodal semantic consistency for better image utilization. Our method achieves state-of-the-art (SOTA) performance on widely used MABSA datasets Twitter-15 and Twitter-17. This demonstrates the effectiveness of the pipeline approach and its potential to provide valuable insights for future MABSA research. For reproducibility, the code and checkpoint will be released.
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
Causal Graph Neural Networks for Wildfire Danger Prediction
Mar 13, 2024



Wildfire forecasting is notoriously hard due to the complex interplay of different factors such as weather conditions, vegetation types and human activities. Deep learning models show promise in dealing with this complexity by learning directly from data. However, to inform critical decision making, we argue that we need models that are right for the right reasons; that is, the implicit rules learned should be grounded by the underlying processes driving wildfires. In that direction, we propose integrating causality with Graph Neural Networks (GNNs) that explicitly model the causal mechanism among complex variables via graph learning. The causal adjacency matrix considers the synergistic effect among variables and removes the spurious links from highly correlated impacts. Our methodology's effectiveness is demonstrated through superior performance forecasting wildfire patterns in the European boreal and mediterranean biome. The gain is especially prominent in a highly imbalanced dataset, showcasing an enhanced robustness of the model to adapt to regime shifts in functional relationships. Furthermore, SHAP values from our trained model further enhance our understanding of the model's inner workings.
Efficient Subseasonal Weather Forecast using Teleconnection-informed Transformers
Feb 05, 2024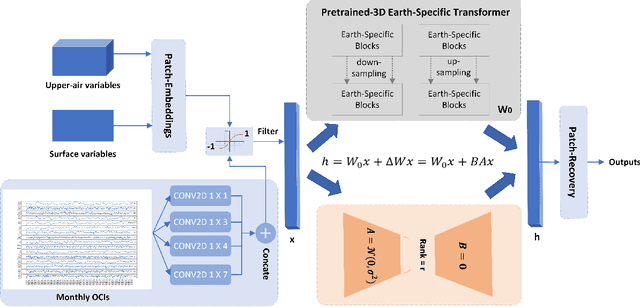
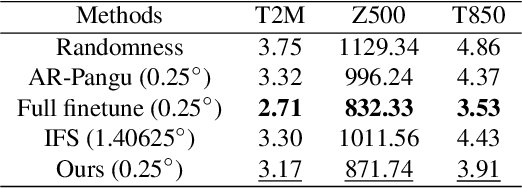
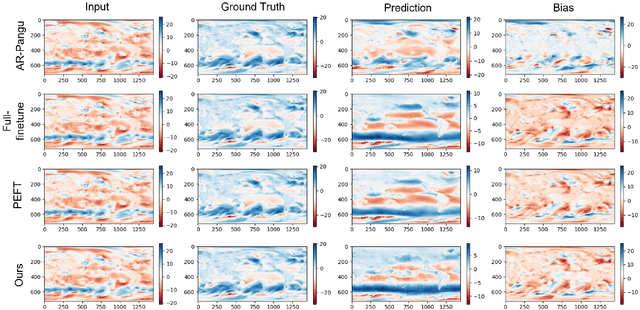
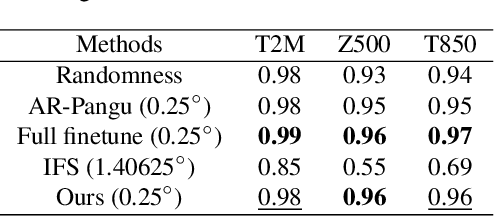
Subseasonal forecasting, which is pivotal for agriculture, water resource management, and early warning of disasters, faces challenges due to the chaotic nature of the atmosphere. Recent advances in machine learning (ML) have revolutionized weather forecasting by achieving competitive predictive skills to numerical models. However, training such foundation models requires thousands of GPU days, which causes substantial carbon emissions and limits their broader applicability. Moreover, ML models tend to fool the pixel-wise error scores by producing smoothed results which lack physical consistency and meteorological meaning. To deal with the aforementioned problems, we propose a teleconnection-informed transformer. Our architecture leverages the pretrained Pangu model to achieve good initial weights and integrates a teleconnection-informed temporal module to improve predictability in an extended temporal range. Remarkably, by adjusting 1.1% of the Pangu model's parameters, our method enhances predictability on four surface and five upper-level atmospheric variables at a two-week lead time. Furthermore, the teleconnection-filtered features improve the spatial granularity of outputs significantly, indicating their potential physical consistency. Our research underscores the importance of atmospheric and oceanic teleconnections in driving future weather conditions. Besides, it presents a resource-efficient pathway for researchers to leverage existing foundation models on versatile downstream tasks.
A Dual-way Enhanced Framework from Text Matching Point of View for Multimodal Entity Linking
Dec 19, 2023



Multimodal Entity Linking (MEL) aims at linking ambiguous mentions with multimodal information to entity in Knowledge Graph (KG) such as Wikipedia, which plays a key role in many applications. However, existing methods suffer from shortcomings, including modality impurity such as noise in raw image and ambiguous textual entity representation, which puts obstacles to MEL. We formulate multimodal entity linking as a neural text matching problem where each multimodal information (text and image) is treated as a query, and the model learns the mapping from each query to the relevant entity from candidate entities. This paper introduces a dual-way enhanced (DWE) framework for MEL: (1) our model refines queries with multimodal data and addresses semantic gaps using cross-modal enhancers between text and image information. Besides, DWE innovatively leverages fine-grained image attributes, including facial characteristic and scene feature, to enhance and refine visual features. (2)By using Wikipedia descriptions, DWE enriches entity semantics and obtains more comprehensive textual representation, which reduces between textual representation and the entities in KG. Extensive experiments on three public benchmarks demonstrate that our method achieves state-of-the-art (SOTA) performance, indicating the superiority of our model. The code is released on https://github.com/season1blue/DWE
Exploring Geometric Deep Learning For Precipitation Nowcasting
Sep 11, 2023

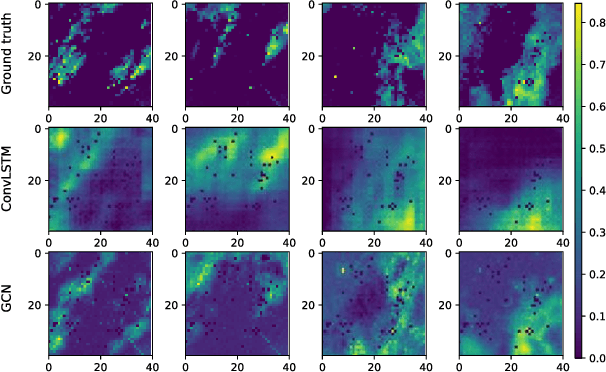

Precipitation nowcasting (up to a few hours) remains a challenge due to the highly complex local interactions that need to be captured accurately. Convolutional Neural Networks rely on convolutional kernels convolving with grid data and the extracted features are trapped by limited receptive field, typically expressed in excessively smooth output compared to ground truth. Thus they lack the capacity to model complex spatial relationships among the grids. Geometric deep learning aims to generalize neural network models to non-Euclidean domains. Such models are more flexible in defining nodes and edges and can effectively capture dynamic spatial relationship among geographical grids. Motivated by this, we explore a geometric deep learning-based temporal Graph Convolutional Network (GCN) for precipitation nowcasting. The adjacency matrix that simulates the interactions among grid cells is learned automatically by minimizing the L1 loss between prediction and ground truth pixel value during the training procedure. Then, the spatial relationship is refined by GCN layers while the temporal information is extracted by 1D convolution with various kernel lengths. The neighboring information is fed as auxiliary input layers to improve the final result. We test the model on sequences of radar reflectivity maps over the Trento/Italy area. The results show that GCNs improves the effectiveness of modeling the local details of the cloud profile as well as the prediction accuracy by achieving decreased error measures.