 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRt-Track: Robust Tricks for Multi-Pedestrian Tracking
Mar 16, 2023



Object tracking is divided into single-object tracking (SOT) and multi-object tracking (MOT). MOT aims to maintain the identities of multiple objects across a series of continuous video sequences. In recent years, MOT has made rapid progress. However, modeling the motion and appearance models of objects in complex scenes still faces various challenging issues. In this paper, we design a novel direction consistency method for smooth trajectory prediction (STP-DC) to increase the modeling of motion information and overcome the lack of robustness in previous methods in complex scenes. Existing methods use pedestrian re-identification (Re-ID) to model appearance, however, they extract more background information which lacks discriminability in occlusion and crowded scenes. We propose a hyper-grain feature embedding network (HG-FEN) to enhance the modeling of appearance models, thus generating robust appearance descriptors. We also proposed other robustness techniques, including CF-ECM for storing robust appearance information and SK-AS for improving association accuracy. To achieve state-of-the-art performance in MOT, we propose a robust tracker named Rt-track, incorporating various tricks and techniques. It achieves 79.5 MOTA, 76.0 IDF1 and 62.1 HOTA on the test set of MOT17.Rt-track also achieves 77.9 MOTA, 78.4 IDF1 and 63.3 HOTA on MOT20, surpassing all published methods.
InterFace:Adjustable Angular Margin Inter-class Loss for Deep Face Recognition
Oct 09, 2022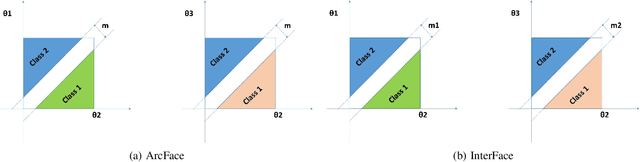
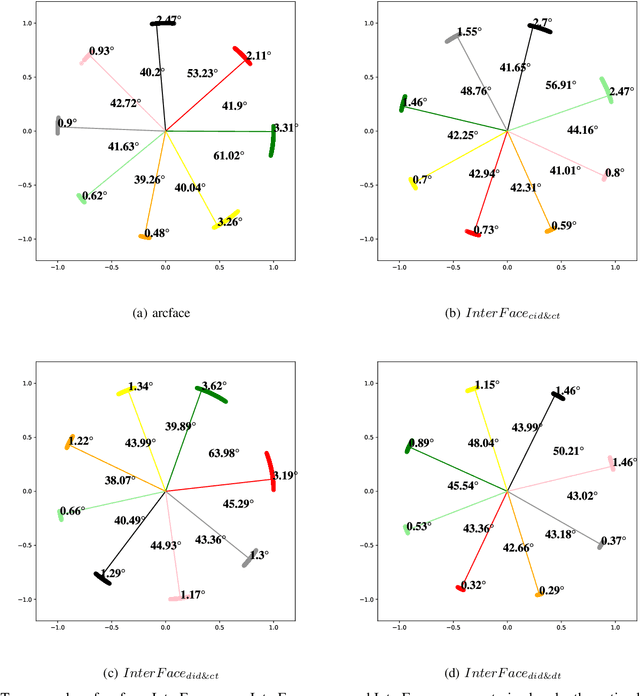

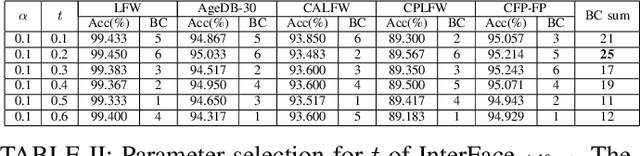
In the field of face recognition, it is always a hot research topic to improve the loss solution to make the face features extracted by the network have greater discriminative power. Research works in recent years has improved the discriminative power of the face model by normalizing softmax to the cosine space step by step and then adding a fixed penalty margin to reduce the intra-class distance to increase the inter-class distance. Although a great deal of previous work has been done to optimize the boundary penalty to improve the discriminative power of the model, adding a fixed margin penalty to the depth feature and the corresponding weight is not consistent with the pattern of data in the real scenario. To address this issue, in this paper, we propose a novel loss function, InterFace, releasing the constraint of adding a margin penalty only between the depth feature and the corresponding weight to push the separability of classes by adding corresponding margin penalties between the depth features and all weights. To illustrate the advantages of InterFace over a fixed penalty margin, we explained geometrically and comparisons on a set of mainstream benchmarks. From a wider perspective, our InterFace has advanced the state-of-the-art face recognition performance on five out of thirteen mainstream benchmarks. All training codes, pre-trained models, and training logs, are publicly released \footnote{$https://github.com/iamsangmeng/InterFace$}.