 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does Vision Meet Language? Understanding and Refining Visual Fusion in MLLMs via Contrastive Attention
Jan 13, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress in vision-language understanding, yet how they internally integrate visual and textual information remains poorly understood. To bridge this gap, we perform a systematic layer-wise masking analysis across multiple architectures, revealing how visual-text fusion evolves within MLLMs. The results show that fusion emerges at several specific layers rather than being uniformly distributed across the network, and certain models exhibit a late-stage "review" phenomenon where visual signals are reactivated before output generation. Besides, we further analyze layer-wise attention evolution and observe persistent high-attention noise on irrelevant regions, along with gradually increasing attention on text-aligned areas. Guided by these insights, we introduce a training-free contrastive attention framework that models the transformation between early fusion and final layers to highlight meaningful attention shifts. Extensive experiments across various MLLMs and benchmarks validate our analysis and demonstrate that the proposed approach improves multimodal reasoning performance. Code will be released.
Seeing Right but Saying Wrong: Inter- and Intra-Layer Refinement in MLLMs without Training
Jan 12, 2026Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities across a variety of vision-language tasks. However, their internal reasoning often exhibits a critical inconsistency: although deeper layers may attend to the correct visual regions, final predictions are frequently misled by noisy attention from earlier layers. This results in a disconnect between what the model internally understands and what it ultimately expresses, a phenomenon we describe as seeing it right but saying it wrong. To address this issue, we propose DualPD, a dual-perspective decoding refinement strategy that enhances the visual understanding without any additional training. DualPD consists of two components. (1) The layer-wise attention-guided contrastive logits module captures how the belief in the correct answer evolves by comparing output logits between layers that exhibit the largest attention shift. (2) The head-wise information filtering module suppresses low-contribution attention heads that focus on irrelevant regions, thereby improving attention quality within each layer. Experiments conducted on both the LLaVA and Qwen-VL model families across multiple multimodal benchmarks demonstrate that DualPD consistently improves accuracy without training, confirming its effectiveness and generalizability. The code will be released upon publication.
Step More: Going Beyond Single Backpropagation in Meta Learning Based Model Editing
Aug 06, 2025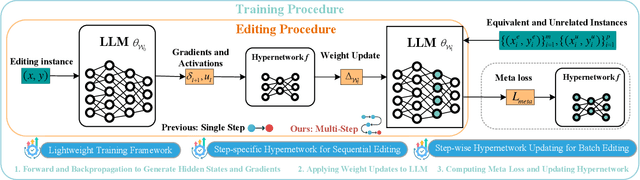

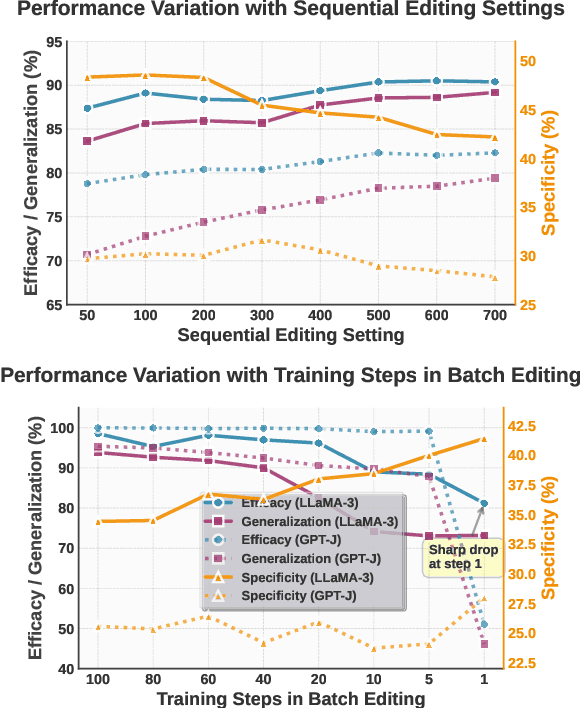

Large Language Models (LLMs) underpin many AI applications, but their static nature makes updating knowledge costly. Model editing offers an efficient alternative by injecting new information through targeted parameter modifications. In particular, meta-learning-based model editing (MLBME) methods have demonstrated notable advantages in both editing effectiveness and efficiency. Despite this, we find that MLBME exhibits suboptimal performance in low-data scenarios, and its training efficiency is bottlenecked by the computation of KL divergence. To address these, we propose $\textbf{S}$tep $\textbf{M}$ore $\textbf{Edit}$ ($\textbf{SMEdit}$), a novel MLBME method that adopts $\textbf{M}$ultiple $\textbf{B}$ackpro$\textbf{P}$agation $\textbf{S}$teps ($\textbf{MBPS}$) to improve editing performance under limited supervision and a norm regularization on weight updates to improve training efficiency. Experimental results on two datasets and two LLMs demonstrate that SMEdit outperforms prior MLBME baselines and the MBPS strategy can be seamlessly integrated into existing methods to further boost their performance. Our code will be released soon.
Rethinking the Residual Distribution of Locate-then-Editing Methods in Model Editing
Feb 06, 2025Model editing is a powerful technique for updating the knowledge of Large Language Models (LLMs). Locate-then-edit methods are a popular class of approaches that first identify the critical layers storing knowledge, then compute the residual of the last critical layer based on the edited knowledge, and finally perform multi-layer updates using a least-squares solution by evenly distributing the residual from the first critical layer to the last. Although these methods achieve promising results, they have been shown to degrade the original knowledge of LLMs. We argue that residual distribution leads to this issue. To explore this, we conduct a comprehensive analysis of residual distribution in locate-then-edit methods from both empirical and theoretical perspectives, revealing that residual distribution introduces editing errors, leading to inaccurate edits. To address this issue, we propose the Boundary Layer UpdatE (BLUE) strategy to enhance locate-then-edit methods. Sequential batch editing experiments on three LLMs and two datasets demonstrate that BLUE not only delivers an average performance improvement of 35.59\%, significantly advancing the state of the art in model editing, but also enhances the preservation of LLMs' general capabilities. Our code is available at https://github.com/xpq-tech/BLUE.
How to Complete Domain Tuning while Keeping General Ability in LLM: Adaptive Layer-wise and Element-wise Regularization
Jan 23, 2025Large Language Models (LLMs) exhibit strong general-purpose language capabilities. However, fine-tuning these models on domain-specific tasks often leads to catastrophic forgetting, where the model overwrites or loses essential knowledge acquired during pretraining. This phenomenon significantly limits the broader applicability of LLMs. To address this challenge, we propose a novel approach to compute the element-wise importance of model parameters crucial for preserving general knowledge during fine-tuning. Our method utilizes a dual-objective optimization strategy: (1) regularization loss to retain the parameter crucial for general knowledge; (2) cross-entropy loss to adapt to domain-specific tasks. Additionally, we introduce layer-wise coefficients to account for the varying contributions of different layers, dynamically balancing the dual-objective optimization. Extensive experiments on scientific, medical, and physical tasks using GPT-J and LLaMA-3 demonstrate that our approach mitigates catastrophic forgetting while enhancing model adaptability. Compared to previous methods, our solution is approximately 20 times faster and requires only 10%-15% of the storage, highlighting the practical efficiency. The code will be released.
MOSABench: Multi-Object Sentiment Analysis Benchmark for Evaluating Multimodal Large Language Models Understanding of Complex Image
Nov 25, 2024



Multimodal large language models (MLLMs) have shown remarkable progress in high-level semantic tasks such as visual question answering, image captioning, and emotion recognition. However, despite advancements, there remains a lack of standardized benchmarks for evaluating MLLMs performance in multi-object sentiment analysis, a key task in semantic understanding. To address this gap, we introduce MOSABench, a novel evaluation dataset designed specifically for multi-object sentiment analysis. MOSABench includes approximately 1,000 images with multiple objects, requiring MLLMs to independently assess the sentiment of each object, thereby reflecting real-world complexities. Key innovations in MOSABench include distance-based target annotation, post-processing for evaluation to standardize outputs, and an improved scoring mechanism. Our experiments reveal notable limitations in current MLLMs: while some models, like mPLUG-owl and Qwen-VL2, demonstrate effective attention to sentiment-relevant features, others exhibit scattered focus and performance declines, especially as the spatial distance between objects increases. This research underscores the need for MLLMs to enhance accuracy in complex, multi-object sentiment analysis tasks and establishes MOSABench as a foundational tool for advancing sentiment analysis capabilities in MLLMs.
Identifying Knowledge Editing Types in Large Language Models
Sep 29, 2024Knowledge editing has emerged as an efficient approach for updating the knowledge of large language models (LLMs), attracting increasing attention in recent research. However, there is a notable lack of effective measures to prevent the malicious misuse of this technology, which could lead to harmful edits in LLMs. These malicious modifications have the potential to cause LLMs to generate toxic content, misleading users into inappropriate actions. To address this issue, we introduce a novel task, \textbf{K}nowledge \textbf{E}diting \textbf{T}ype \textbf{I}dentification (KETI), aimed at identifying malicious edits in LLMs. As part of this task, we present KETIBench, a benchmark that includes five types of malicious updates and one type of benign update. Furthermore, we develop four classical classification models and three BERT-based models as baseline identifiers for both open-source and closed-source LLMs. Our experimental results, spanning 42 trials involving two models and three knowledge editing methods, demonstrate that all seven baseline identifiers achieve decent identification performance, highlighting the feasibility of identifying malicious edits in LLMs. Additional analyses reveal that the performance of the identifiers is independent of the efficacy of the knowledge editing methods and exhibits cross-domain generalization, enabling the identification of edits from unknown sources. All data and code are available in https://github.com/xpq-tech/KETI. Warning: This paper contains examples of toxic text.
PTA: Enhancing Multimodal Sentiment Analysis through Pipelined Prediction and Translation-based Alignment
May 23, 2024
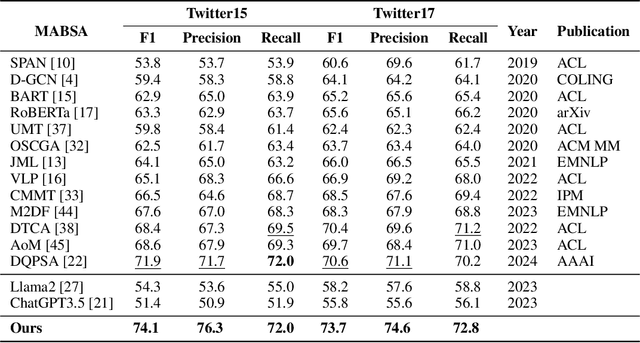


Multimodal aspect-based sentiment analysis (MABSA) aims to understand opinions in a granular manner, advancing human-computer interaction and other fields. Traditionally, MABSA methods use a joint prediction approach to identify aspects and sentiments simultaneously. However, we argue that joint models are not always superior. Our analysis shows that joint models struggle to align relevant text tokens with image patches, leading to misalignment and ineffective image utilization. In contrast, a pipeline framework first identifies aspects through MATE (Multimodal Aspect Term Extraction) and then aligns these aspects with image patches for sentiment classification (MASC: Multimodal Aspect-Oriented Sentiment Classification). This method is better suited for multimodal scenarios where effective image use is crucial. We present three key observations: (a) MATE and MASC have different feature requirements, with MATE focusing on token-level features and MASC on sequence-level features; (b) the aspect identified by MATE is crucial for effective image utilization; and (c) images play a trivial role in previous MABSA methods due to high noise. Based on these observations, we propose a pipeline framework that first predicts the aspect and then uses translation-based alignment (TBA) to enhance multimodal semantic consistency for better image utilization. Our method achieves state-of-the-art (SOTA) performance on widely used MABSA datasets Twitter-15 and Twitter-17. This demonstrates the effectiveness of the pipeline approach and its potential to provide valuable insights for future MABSA research. For reproducibility, the code and checkpoint will be released.
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
SWEA: Changing Factual Knowledge in Large Language Models via Subject Word Embedding Altering
Jan 31, 2024Model editing has recently gained widespread attention. Current model editing methods primarily involve modifying model parameters or adding additional modules to the existing model. However, the former causes irreversible damage to LLMs, while the latter incurs additional inference overhead and fuzzy vector matching is not always reliable. To address these issues, we propose an expandable Subject Word Embedding Altering (SWEA) framework, which modifies the representation of subjects and achieve the goal of editing knowledge during the inference stage. SWEA uses precise key matching outside the model and performs reliable subject word embedding altering, thus protecting the original weights of the model without increasing inference overhead. We then propose optimizing then suppressing fusion method, which first optimizes the embedding vector for the editing target and then suppresses the Knowledge Embedding Dimension (KED) to obtain the final fused embedding. We thus propose SWEAOS method for editing factual knowledge in LLMs. We demonstrate the state-of-the-art performance of SWEAOS on the COUNTERFACT and zsRE datasets. To further validate the reasoning ability of SWEAOS in editing knowledge, we evaluate it on the more complex RIPPLEEDITS benchmark. The results on two subdatasets demonstrate that our SWEAOS possesses state-of-the-art reasoning ability.