 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Knowledge Editing Types in Large Language Models
Sep 29, 2024Knowledge editing has emerged as an efficient approach for updating the knowledge of large language models (LLMs), attracting increasing attention in recent research. However, there is a notable lack of effective measures to prevent the malicious misuse of this technology, which could lead to harmful edits in LLMs. These malicious modifications have the potential to cause LLMs to generate toxic content, misleading users into inappropriate actions. To address this issue, we introduce a novel task, \textbf{K}nowledge \textbf{E}diting \textbf{T}ype \textbf{I}dentification (KETI), aimed at identifying malicious edits in LLMs. As part of this task, we present KETIBench, a benchmark that includes five types of malicious updates and one type of benign update. Furthermore, we develop four classical classification models and three BERT-based models as baseline identifiers for both open-source and closed-source LLMs. Our experimental results, spanning 42 trials involving two models and three knowledge editing methods, demonstrate that all seven baseline identifiers achieve decent identification performance, highlighting the feasibility of identifying malicious edits in LLMs. Additional analyses reveal that the performance of the identifiers is independent of the efficacy of the knowledge editing methods and exhibits cross-domain generalization, enabling the identification of edits from unknown sources. All data and code are available in https://github.com/xpq-tech/KETI. Warning: This paper contains examples of toxic text.
Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning
Jun 06, 2024



Code Pre-trained Models (CodePTMs) based vulnerability detection have achieved promising results over recent years. However, these models struggle to generalize as they typically learn superficial mapping from source code to labels instead of understanding the root causes of code vulnerabilities, resulting in poor performance in real-world scenarios beyond the training instances. To tackle this challenge, we introduce VulLLM, a novel framework that integrates multi-task learning with Large Language Models (LLMs) to effectively mine deep-seated vulnerability features. Specifically, we construct two auxiliary tasks beyond the vulnerability detection task. First, we utilize the vulnerability patches to construct a vulnerability localization task. Second, based on the vulnerability features extracted from patches, we leverage GPT-4 to construct a vulnerability interpretation task. VulLLM innovatively augments vulnerability classification by leveraging generative LLMs to understand complex vulnerability patterns, thus compelling the model to capture the root causes of vulnerabilities rather than overfitting to spurious features of a single task. The experiments conducted on six large datasets demonstrate that VulLLM surpasses seven state-of-the-art models in terms of effectiveness, generalization, and robustness.
Span-based joint entity and relation extraction augmented with sequence tagging mechanism
Oct 23, 2022



Span-based joint extraction simultaneously conducts named entity recognition (NER) and relation extraction (RE) in text span form. However, since previous span-based models rely on span-level classifications, they cannot benefit from token-level label information, which has been proven advantageous for the task. In this paper, we propose a Sequence Tagging augmented Span-based Network (STSN), a span-based joint model that can make use of token-level label information. In STSN, we construct a core neural architecture by deep stacking multiple attention layers, each of which consists of three basic attention units. On the one hand, the core architecture enables our model to learn token-level label information via the sequence tagging mechanism and then uses the information in the span-based joint extraction; on the other hand, it establishes a bi-directional information interaction between NER and RE. Experimental results on three benchmark datasets show that STSN consistently outperforms the strongest baselines in terms of F1, creating new state-of-the-art results.
A Two-Phase Paradigm for Joint Entity-Relation Extraction
Aug 18, 2022
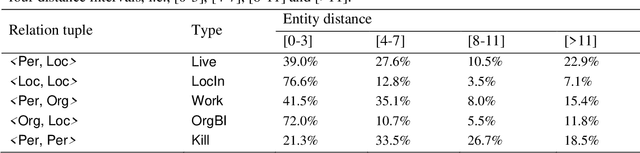
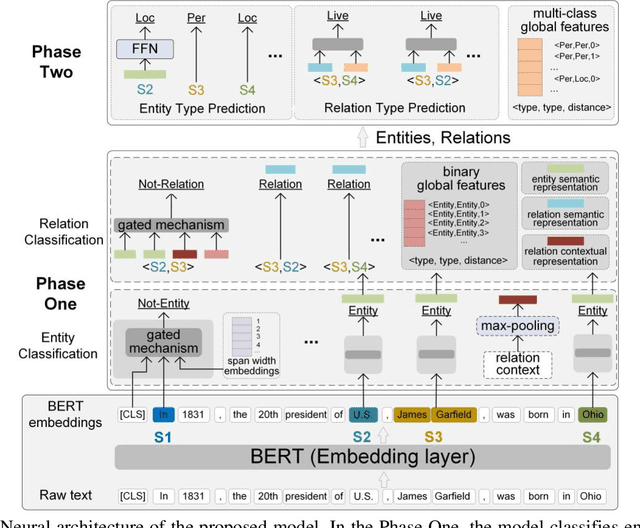

An exhaustive study has been conducted to investigate span-based models for the joint entity and relation extraction task. However, these models sample a large number of negative entities and negative relations during the model training, which are essential but result in grossly imbalanced data distributions and in turn cause suboptimal model performance. In order to address the above issues, we propose a two-phase paradigm for the span-based joint entity and relation extraction, which involves classifying the entities and relations in the first phase, and predicting the types of these entities and relations in the second phase. The two-phase paradigm enables our model to significantly reduce the data distribution gap, including the gap between negative entities and other entities, as well as the gap between negative relations and other relations. In addition, we make the first attempt at combining entity type and entity distance as global features, which has proven effective, especially for the relation extraction. Experimental results on several datasets demonstrate that the spanbased joint extraction model augmented with the two-phase paradigm and the global features consistently outperforms previous state-of-the-art span-based models for the joint extraction task, establishing a new standard benchmark. Qualitative and quantitative analyses further validate the effectiveness the proposed paradigm and the global features.
A Context-Aware Approach for Textual Adversarial Attack through Probability Difference Guided Beam Search
Aug 17, 2022


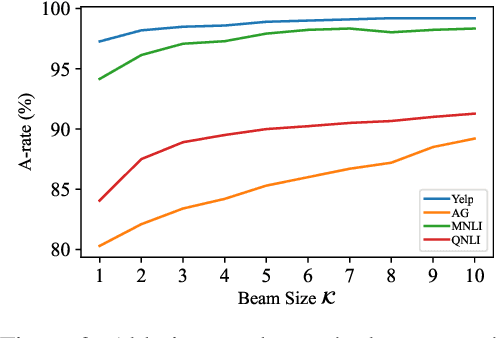
Textual adversarial attacks expose the vulnerabilities of text classifiers and can be used to improve their robustness. Existing context-aware methods solely consider the gold label probability and use the greedy search when searching an attack path, often limiting the attack efficiency. To tackle these issues, we propose PDBS, a context-aware textual adversarial attack model using Probability Difference guided Beam Search. The probability difference is an overall consideration of all class label probabilities, and PDBS uses it to guide the selection of attack paths. In addition, PDBS uses the beam search to find a successful attack path, thus avoiding suffering from limited search space. Extensive experiments and human evaluation demonstrate that PDBS outperforms previous best models in a series of evaluation metrics, especially bringing up to a +19.5% attack success rate. Ablation studies and qualitative analyses further confirm the efficiency of PDBS.
Few-shot Named Entity Recognition with Entity-level Prototypical Network Enhanced by Dispersedly Distributed Prototypes
Aug 17, 2022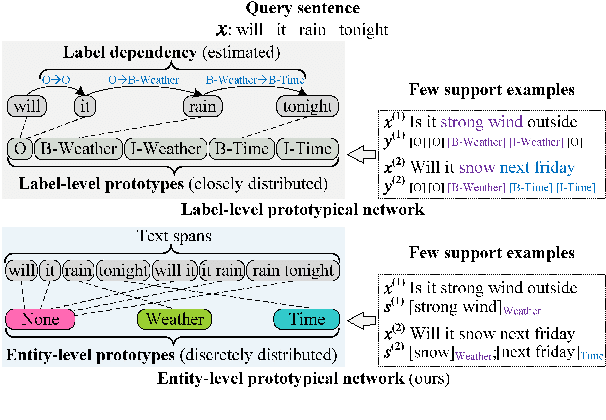
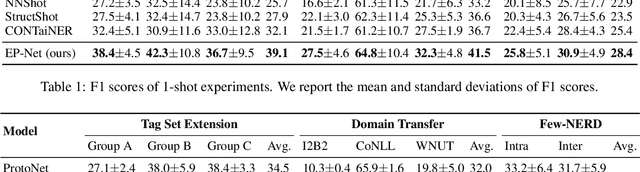
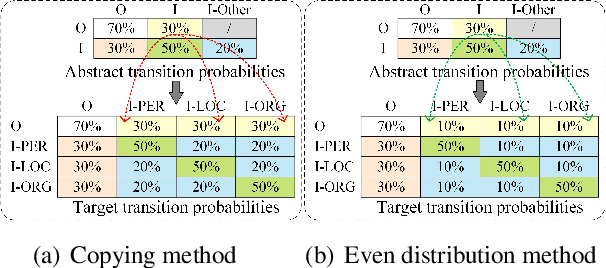
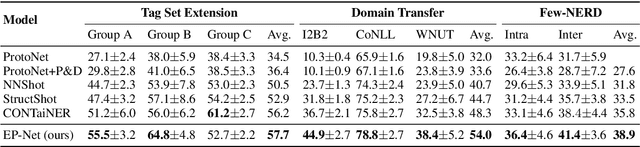
Few-shot named entity recognition (NER) enables us to build a NER system for a new domain using very few labeled examples. However, existing prototypical networks for this task suffer from roughly estimated label dependency and closely distributed prototypes, thus often causing misclassifications. To address the above issues, we propose EP-Net, an Entity-level Prototypical Network enhanced by dispersedly distributed prototypes. EP-Net builds entity-level prototypes and considers text spans to be candidate entities, so it no longer requires the label dependency. In addition, EP-Net trains the prototypes from scratch to distribute them dispersedly and aligns spans to prototypes in the embedding space using a space projection. Experimental results on two evaluation tasks and the Few-NERD settings demonstrate that EP-Net consistently outperforms the previous strong models in terms of overall performance. Extensive analyses further validate the effectiveness of EP-Net.
Win-Win Cooperation: Bundling Sequence and Span Models for Named Entity Recognition
Jul 16, 2022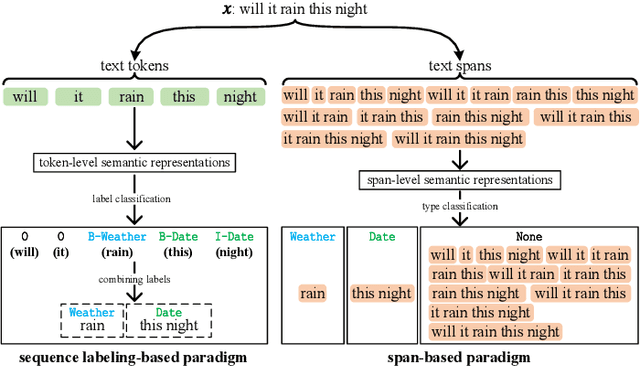
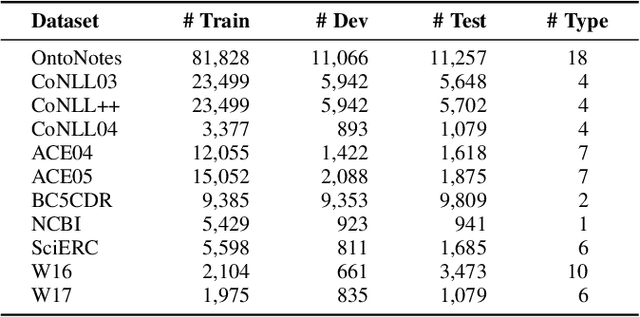

For Named Entity Recognition (NER), sequence labeling-based and span-based paradigms are quite different. Previous research has demonstrated that the two paradigms have clear complementary advantages, but few models have attempted to leverage these advantages in a single NER model as far as we know. In our previous work, we proposed a paradigm known as Bundling Learning (BL) to address the above problem. The BL paradigm bundles the two NER paradigms, enabling NER models to jointly tune their parameters by weighted summing each paradigm's training loss. However, three critical issues remain unresolved: When does BL work? Why does BL work? Can BL enhance the existing state-of-the-art (SOTA) NER models? To address the first two issues, we implement three NER models, involving a sequence labeling-based model--SeqNER, a span-based NER model--SpanNER, and BL-NER that bundles SeqNER and SpanNER together. We draw two conclusions regarding the two issues based on the experimental results on eleven NER datasets from five domains. We then apply BL to five existing SOTA NER models to investigate the third issue, consisting of three sequence labeling-based models and two span-based models. Experimental results indicate that BL consistently enhances their performance, suggesting that it is possible to construct a new SOTA NER system by incorporating BL into the current SOTA system. Moreover, we find that BL reduces both entity boundary and type prediction errors. In addition, we compare two commonly used labeling tagging methods as well as three types of span semantic representations.
Topic-Grained Text Representation-based Model for Document Retrieval
Jul 11, 2022


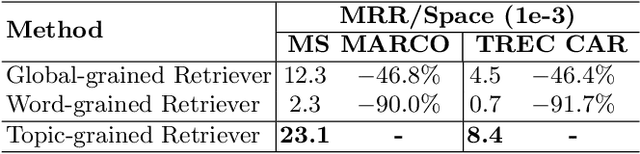
Document retrieval enables users to find their required documents accurately and quickly. To satisfy the requirement of retrieval efficiency, prevalent deep neural methods adopt a representation-based matching paradigm, which saves online matching time by pre-storing document representations offline. However, the above paradigm consumes vast local storage space, especially when storing the document as word-grained representations. To tackle this, we present TGTR, a Topic-Grained Text Representation-based Model for document retrieval. Following the representation-based matching paradigm, TGTR stores the document representations offline to ensure retrieval efficiency, whereas it significantly reduces the storage requirements by using novel topicgrained representations rather than traditional word-grained. Experimental results demonstrate that compared to word-grained baselines, TGTR is consistently competitive with them on TREC CAR and MS MARCO in terms of retrieval accuracy, but it requires less than 1/10 of the storage space required by them. Moreover, TGTR overwhelmingly surpasses global-grained baselines in terms of retrieval accuracy.
Deep Domain Adaptation for Pavement Crack Detection
Nov 19, 2021


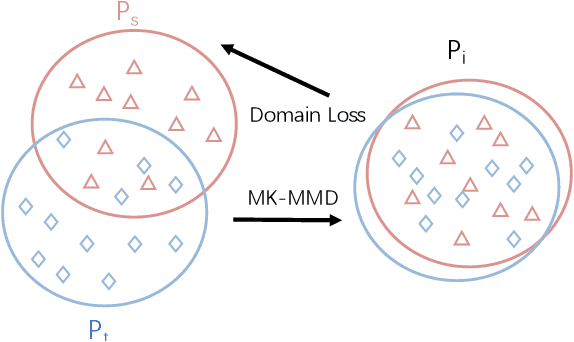
Deep learning-based pavement cracks detection methods often require large-scale labels with detailed crack location information to learn accurate predictions. In practice, however, crack locations are very difficult to be manually annotated due to various visual patterns of pavement crack. In this paper, we propose a Deep Domain Adaptation-based Crack Detection Network (DDACDN), which learns to take advantage of the source domain knowledge to predict the multi-category crack location information in the target domain, where only image-level labels are available. Specifically, DDACDN first extracts crack features from both the source and target domain by a two-branch weights-shared backbone network. And in an effort to achieve the cross-domain adaptation, an intermediate domain is constructed by aggregating the three-scale features from the feature space of each domain to adapt the crack features from the source domain to the target domain. Finally, the network involves the knowledge of both domains and is trained to recognize and localize pavement cracks. To facilitate accurate training and validation for domain adaptation, we use two challenging pavement crack datasets CQU-BPDD and RDD2020. Furthermore, we construct a new large-scale Bituminous Pavement Multi-label Disease Dataset named CQU-BPMDD, which contains 38994 high-resolution pavement disease images to further evaluate the robustness of our model. Extensive experiments demonstrate that DDACDN outperforms state-of-the-art pavement crack detection methods in predicting the crack location on the target domain.
Boosting Span-based Joint Entity and Relation Extraction via Squence Tagging Mechanism
May 21, 2021
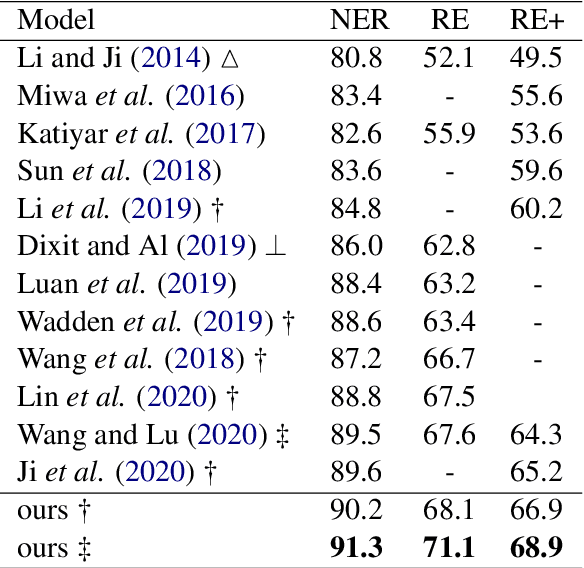
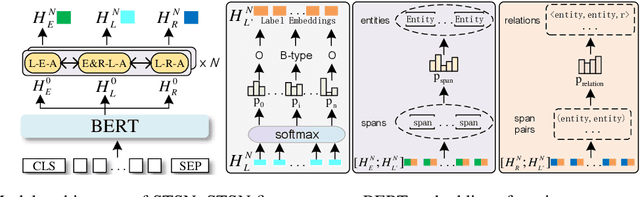
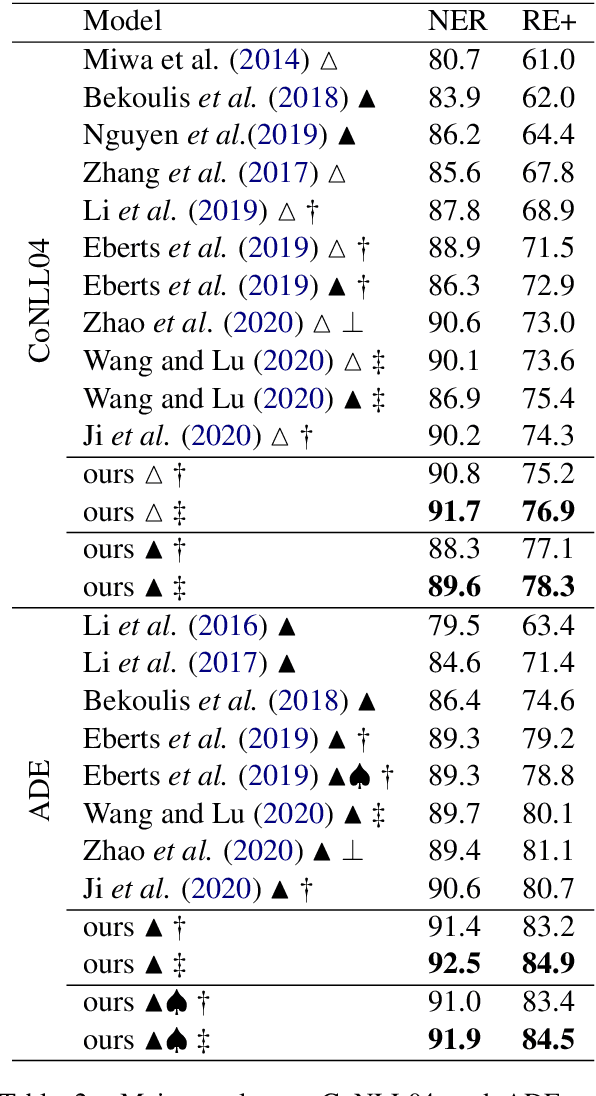
Span-based joint extraction simultaneously conducts named entity recognition (NER) and relation extraction (RE) in text span form. Recent studies have shown that token labels can convey crucial task-specific information and enrich token semantics. However, as far as we know, due to completely abstain from sequence tagging mechanism, all prior span-based work fails to use token label in-formation. To solve this problem, we pro-pose Sequence Tagging enhanced Span-based Network (STSN), a span-based joint extrac-tion network that is enhanced by token BIO label information derived from sequence tag-ging based NER. By stacking multiple atten-tion layers in depth, we design a deep neu-ral architecture to build STSN, and each atten-tion layer consists of three basic attention units. The deep neural architecture first learns seman-tic representations for token labels and span-based joint extraction, and then constructs in-formation interactions between them, which also realizes bidirectional information interac-tions between span-based NER and RE. Fur-thermore, we extend the BIO tagging scheme to make STSN can extract overlapping en-tity. Experiments on three benchmark datasets show that our model consistently outperforms previous optimal models by a large margin, creating new state-of-the-art results.