 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multi-Graphs Learning for Robust Group Re-Identification
Dec 25, 2024



Group Re-identification (G-ReID) faces greater complexity than individual Re-identification (ReID) due to challenges like mutual occlusion, dynamic member interactions, and evolving group structures. Prior graph-based approaches have aimed to capture these dynamics by modeling the group as a single topological structure. However, these methods struggle to generalize across diverse group compositions, as they fail to fully represent the multifaceted relationships within the group. In this study, we introduce a Hierarchical Multi-Graphs Learning (HMGL) framework to address these challenges. Our approach models the group as a collection of multi-relational graphs, leveraging both explicit features (such as occlusion, appearance, and foreground information) and implicit dependencies between members. This hierarchical representation, encoded via a Multi-Graphs Neural Network (MGNN), allows us to resolve ambiguities in member relationships, particularly in complex, densely populated scenes. To further enhance matching accuracy, we propose a Multi-Scale Matching (MSM) algorithm, which mitigates issues of member information ambiguity and sensitivity to hard samples, improving robustness in challenging scenarios. Our method achieves state-of-the-art performance on two standard benchmarks, CSG and RoadGroup, with Rank-1/mAP scores of 95.3%/94.4% and 93.9%/95.4%, respectively. These results mark notable improvements of 1.7% and 2.5% in Rank-1 accuracy over existing approaches.
Two-stream joint matching method based on contrastive learning for few-shot action recognition
Jan 08, 2024Although few-shot action recognition based on metric learning paradigm has achieved significant success, it fails to address the following issues: (1) inadequate action relation modeling and underutilization of multi-modal information; (2) challenges in handling video matching problems with different lengths and speeds, and video matching problems with misalignment of video sub-actions. To address these issues, we propose a Two-Stream Joint Matching method based on contrastive learning (TSJM), which consists of two modules: Multi-modal Contrastive Learning Module (MCL) and Joint Matching Module (JMM). The objective of the MCL is to extensively investigate the inter-modal mutual information relationships, thereby thoroughly extracting modal information to enhance the modeling of action relationships. The JMM aims to simultaneously address the aforementioned video matching problems. The effectiveness of the proposed method is evaluated on two widely used few shot action recognition datasets, namely, SSv2 and Kinetics. Comprehensive ablation experiments are also conducted to substantiate the efficacy of our proposed approach.
Multi-Stage Coarse-to-Fine Contrastive Learning for Conversation Intent Induction
Mar 09, 2023



Intent recognition is critical for task-oriented dialogue systems. However, for emerging domains and new services, it is difficult to accurately identify the key intent of a conversation due to time-consuming data annotation and comparatively poor model transferability. Therefore, the automatic induction of dialogue intention is very important for intelligent dialogue systems. This paper presents our solution to Track 2 of Intent Induction from Conversations for Task-Oriented Dialogue at the Eleventh Dialogue System Technology Challenge (DSTC11). The essence of intention clustering lies in distinguishing the representation of different dialogue utterances. The key to automatic intention induction is that, for any given set of new data, the sentence representation obtained by the model can be well distinguished from different labels. Therefore, we propose a multi-stage coarse-to-fine contrastive learning model training scheme including unsupervised contrastive learning pre-training, supervised contrastive learning pre-training, and fine-tuning with joint contrastive learning and clustering to obtain a better dialogue utterance representation model for the clustering task. In the released DSTC11 Track 2 evaluation results, our proposed system ranked first on both of the two subtasks of this Track.
Forcing the Whole Video as Background: An Adversarial Learning Strategy for Weakly Temporal Action Localization
Jul 14, 2022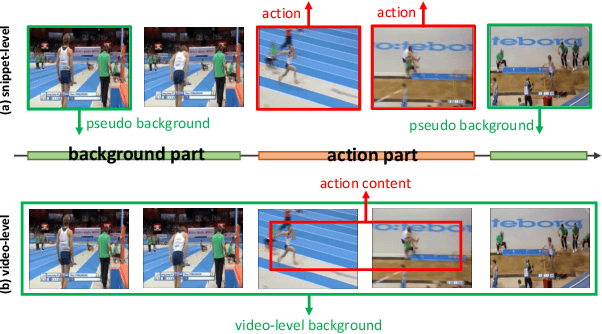
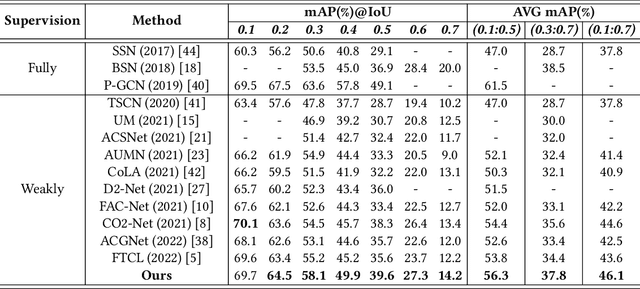
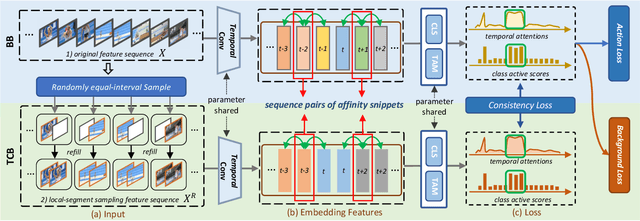
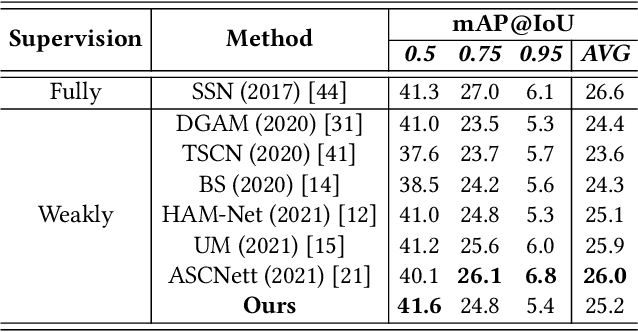
With video-level labels, weakly supervised temporal action localization (WTAL) applies a localization-by-classification paradigm to detect and classify the action in untrimmed videos. Due to the characteristic of classification, class-specific background snippets are inevitably mis-activated to improve the discriminability of the classifier in WTAL. To alleviate the disturbance of background, existing methods try to enlarge the discrepancy between action and background through modeling background snippets with pseudo-snippet-level annotations, which largely rely on artificial hypotheticals. Distinct from the previous works, we present an adversarial learning strategy to break the limitation of mining pseudo background snippets. Concretely, the background classification loss forces the whole video to be regarded as the background by a background gradient reinforcement strategy, confusing the recognition model. Reversely, the foreground(action) loss guides the model to focus on action snippets under such conditions. As a result, competition between the two classification losses drives the model to boost its ability for action modeling. Simultaneously, a novel temporal enhancement network is designed to facilitate the model to construct temporal relation of affinity snippets based on the proposed strategy, for further improving the performance of action localization. Finally, extensive experiments conducted on THUMOS14 and ActivityNet1.2 demonstrate the effectiveness of the proposed method.
Deep Domain Adaptation for Pavement Crack Detection
Nov 19, 2021


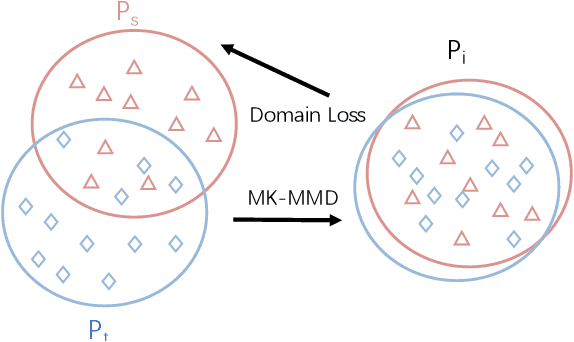
Deep learning-based pavement cracks detection methods often require large-scale labels with detailed crack location information to learn accurate predictions. In practice, however, crack locations are very difficult to be manually annotated due to various visual patterns of pavement crack. In this paper, we propose a Deep Domain Adaptation-based Crack Detection Network (DDACDN), which learns to take advantage of the source domain knowledge to predict the multi-category crack location information in the target domain, where only image-level labels are available. Specifically, DDACDN first extracts crack features from both the source and target domain by a two-branch weights-shared backbone network. And in an effort to achieve the cross-domain adaptation, an intermediate domain is constructed by aggregating the three-scale features from the feature space of each domain to adapt the crack features from the source domain to the target domain. Finally, the network involves the knowledge of both domains and is trained to recognize and localize pavement cracks. To facilitate accurate training and validation for domain adaptation, we use two challenging pavement crack datasets CQU-BPDD and RDD2020. Furthermore, we construct a new large-scale Bituminous Pavement Multi-label Disease Dataset named CQU-BPMDD, which contains 38994 high-resolution pavement disease images to further evaluate the robustness of our model. Extensive experiments demonstrate that DDACDN outperforms state-of-the-art pavement crack detection methods in predicting the crack location on the target domain.
Face Recognition via Globality-Locality Preserving Projections
Nov 06, 2013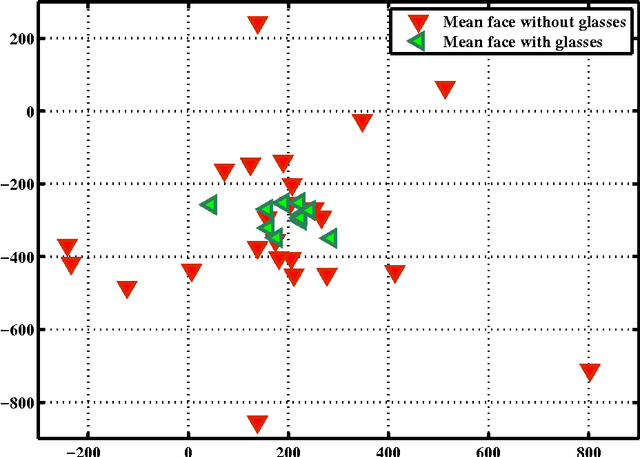


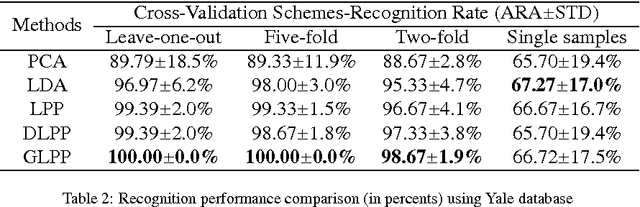
We present an improved Locality Preserving Projections (LPP) method, named Gloablity-Locality Preserving Projections (GLPP), to preserve both the global and local geometric structures of data. In our approach, an additional constraint of the geometry of classes is imposed to the objective function of conventional LPP for respecting some more global manifold structures. Moreover, we formulate a two-dimensional extension of GLPP (2D-GLPP) as an example to show how to extend GLPP with some other statistical techniques. We apply our works to face recognition on four popular face databases, namely ORL, Yale, FERET and LFW-A databases, and extensive experimental results demonstrate that the considered global manifold information can significantly improve the performance of LPP and the proposed face recognition methods outperform the state-of-the-arts.