 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConCM: Consistency-Driven Calibration and Matching for Few-Shot Class-Incremental Learning
Jun 24, 2025Few-Shot Class-Incremental Learning (FSCIL) requires models to adapt to novel classes with limited supervision while preserving learned knowledge. Existing prospective learning-based space construction methods reserve space to accommodate novel classes. However, prototype deviation and structure fixity limit the expressiveness of the embedding space. In contrast to fixed space reservation, we explore the optimization of feature-structure dual consistency and propose a Consistency-driven Calibration and Matching Framework (ConCM) that systematically mitigate the knowledge conflict inherent in FSCIL. Specifically, inspired by hippocampal associative memory, we design a memory-aware prototype calibration that extracts generalized semantic attributes from base classes and reintegrates them into novel classes to enhance the conceptual center consistency of features. Further, we propose dynamic structure matching, which adaptively aligns the calibrated features to a session-specific optimal manifold space, ensuring cross-session structure consistency. Theoretical analysis shows that our method satisfies both geometric optimality and maximum matching, thereby overcoming the need for class-number priors. On large-scale FSCIL benchmarks including mini-ImageNet and CUB200, ConCM achieves state-of-the-art performance, surpassing current optimal method by 3.20% and 3.68% in harmonic accuracy of incremental sessions.
TempoGPT: Enhancing Temporal Reasoning via Quantizing Embedding
Jan 13, 2025Multi-modal language model has made advanced progress in vision and audio, but still faces significant challenges in dealing with complex reasoning tasks in the time series domain. The reasons are twofold. First, labels for multi-modal time series data are coarse and devoid of analysis or reasoning processes. Training with these data cannot improve the model's reasoning capabilities. Second, due to the lack of precise tokenization in processing time series, the representation patterns for temporal and textual information are inconsistent, which hampers the effectiveness of multi-modal alignment. To address these challenges, we propose a multi-modal time series data construction approach and a multi-modal time series language model (TLM), TempoGPT. Specially, we construct multi-modal data for complex reasoning tasks by analyzing the variable-system relationships within a white-box system. Additionally, proposed TempoGPT achieves consistent representation between temporal and textual information by quantizing temporal embeddings, where temporal embeddings are quantized into a series of discrete tokens using a predefined codebook; subsequently, a shared embedding layer processes both temporal and textual tokens. Extensive experiments demonstrate that TempoGPT accurately perceives temporal information, logically infers conclusions, and achieves state-of-the-art in the constructed complex time series reasoning tasks. Moreover, we quantitatively demonstrate the effectiveness of quantizing temporal embeddings in enhancing multi-modal alignment and the reasoning capabilities of TLMs. Code and data are available at https://github.com/zhanghaochuan20/TempoGPT.
Sensorformer: Cross-patch attention with global-patch compression is effective for high-dimensional multivariate time series forecasting
Jan 06, 2025



Among the existing Transformer-based multivariate time series forecasting methods, iTransformer, which treats each variable sequence as a token and only explicitly extracts cross-variable dependencies, and PatchTST, which adopts a channel-independent strategy and only explicitly extracts cross-time dependencies, both significantly outperform most Channel-Dependent Transformer that simultaneously extract cross-time and cross-variable dependencies. This indicates that existing Transformer-based multivariate time series forecasting methods still struggle to effectively fuse these two types of information. We attribute this issue to the dynamic time lags in the causal relationships between different variables. Therefore, we propose a new multivariate time series forecasting Transformer, Sensorformer, which first compresses the global patch information and then simultaneously extracts cross-variable and cross-time dependencies from the compressed representations. Sensorformer can effectively capture the correct inter-variable correlations and causal relationships, even in the presence of dynamic causal lags between variables, while also reducing the computational complexity of pure cross-patch self-attention from $O(D^2 \cdot Patch\_num^2 \cdot d\_model)$ to $O(D^2 \cdot Patch\_num \cdot d\_model)$. Extensive comparative and ablation experiments on 9 mainstream real-world multivariate time series forecasting datasets demonstrate the superiority of Sensorformer. The implementation of Sensorformer, following the style of the Time-series-library and scripts for reproducing the main results, is publicly available at https://github.com/BigYellowTiger/Sensorformer
Canonical Correlation Guided Deep Neural Network
Sep 28, 2024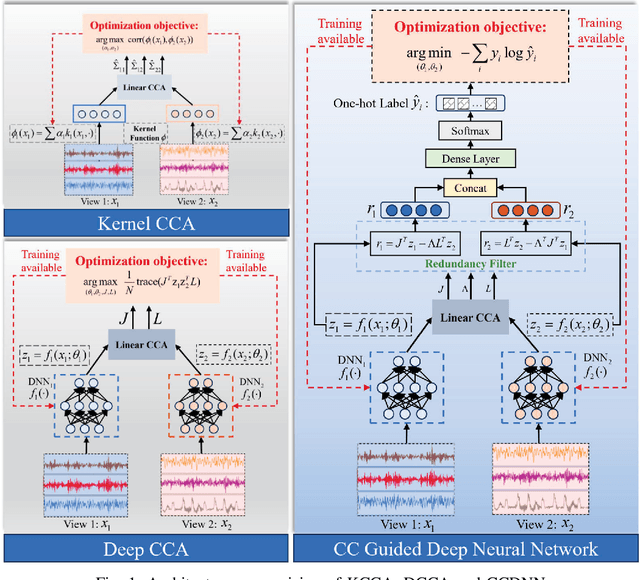
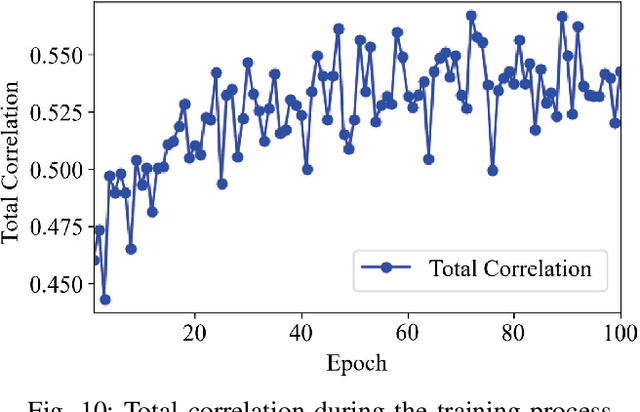
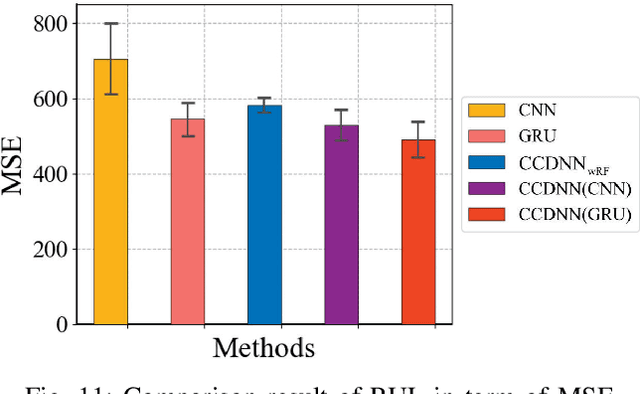
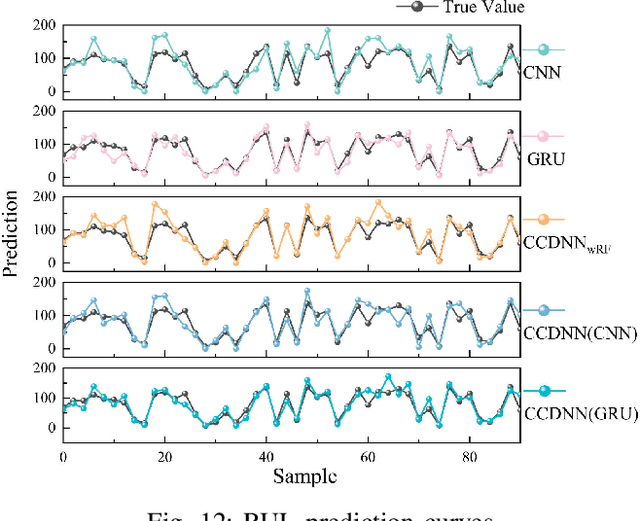
Learning representations of two views of data such that the resulting representations are highly linearly correlated is appealing in machine learning. In this paper, we present a canonical correlation guided learning framework, which allows to be realized by deep neural networks (CCDNN), to learn such a correlated representation. It is also a novel merging of multivariate analysis (MVA) and machine learning, which can be viewed as transforming MVA into end-to-end architectures with the aid of neural networks. Unlike the linear canonical correlation analysis (CCA), kernel CCA and deep CCA, in the proposed method, the optimization formulation is not restricted to maximize correlation, instead we make canonical correlation as a constraint, which preserves the correlated representation learning ability and focuses more on the engineering tasks endowed by optimization formulation, such as reconstruction, classification and prediction. Furthermore, to reduce the redundancy induced by correlation, a redundancy filter is designed. We illustrate the performance of CCDNN on various tasks. In experiments on MNIST dataset, the results show that CCDNN has better reconstruction performance in terms of mean squared error and mean absolute error than DCCA and DCCAE. Also, we present the application of the proposed network to industrial fault diagnosis and remaining useful life cases for the classification and prediction tasks accordingly. The proposed method demonstrates superior performance in both tasks when compared to existing methods. Extension of CCDNN to much more deeper with the aid of residual connection is also presented in appendix.
AIGC for Industrial Time Series: From Deep Generative Models to Large Generative Models
Jul 16, 2024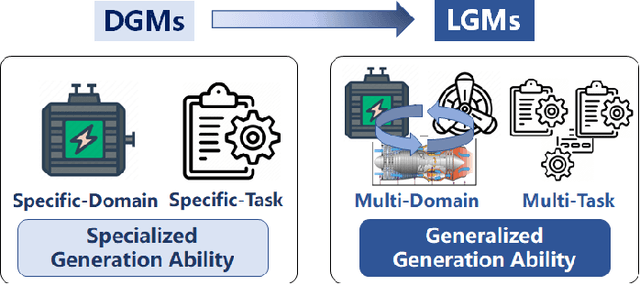
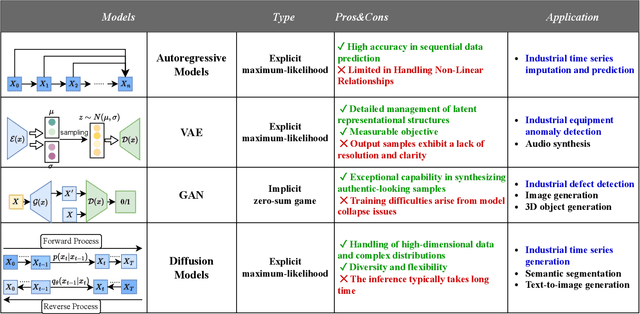
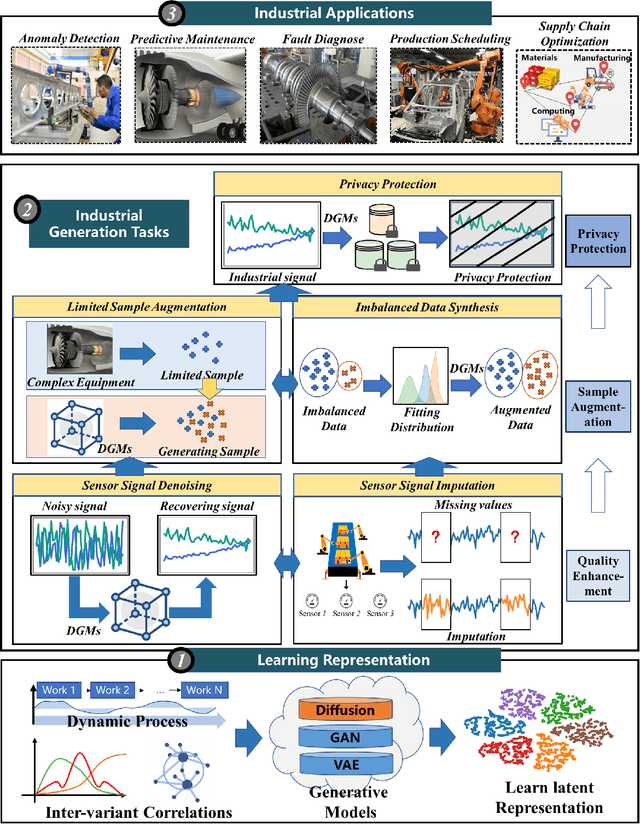
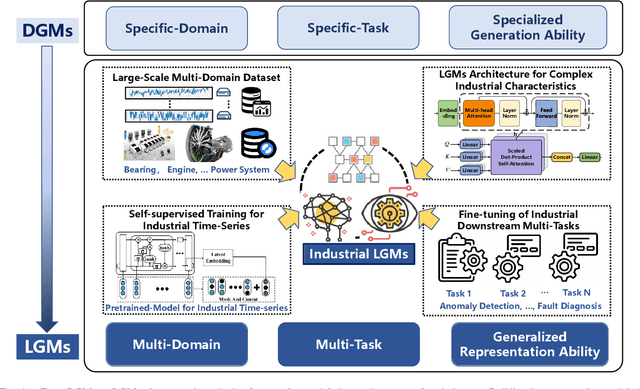
With the remarkable success of generative models like ChatGPT, Artificial Intelligence Generated Content (AIGC) is undergoing explosive development. Not limited to text and images, generative models can generate industrial time series data, addressing challenges such as the difficulty of data collection and data annotation. Due to their outstanding generation ability, they have been widely used in Internet of Things, metaverse, and cyber-physical-social systems to enhance the efficiency of industrial production. In this paper, we present a comprehensive overview of generative models for industrial time series from deep generative models (DGMs) to large generative models (LGMs). First, a DGM-based AIGC framework is proposed for industrial time series generation. Within this framework, we survey advanced industrial DGMs and present a multi-perspective categorization. Furthermore, we systematically analyze the critical technologies required to construct industrial LGMs from four aspects: large-scale industrial dataset, LGMs architecture for complex industrial characteristics, self-supervised training for industrial time series, and fine-tuning of industrial downstream tasks. Finally, we conclude the challenges and future directions to enable the development of generative models in industry.
Spatial-temporal associations representation and application for process monitoring using graph convolution neural network
May 11, 2022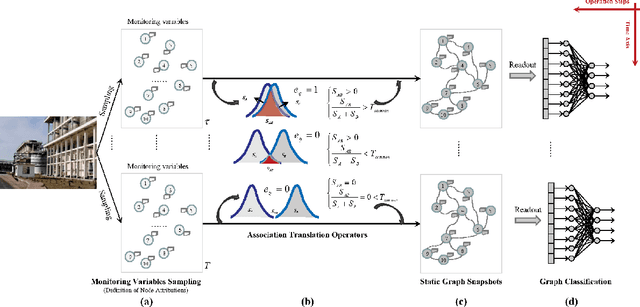
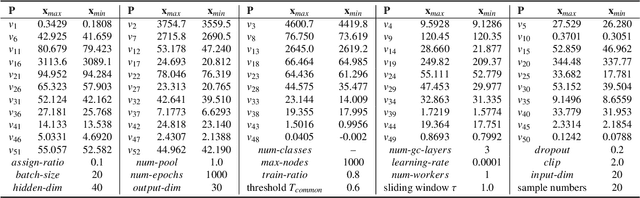
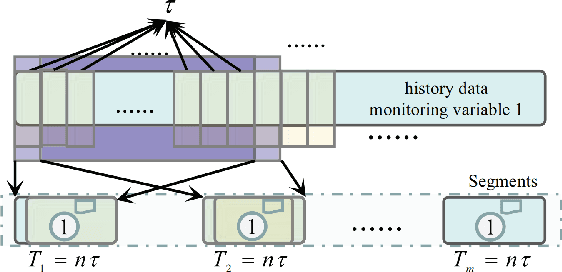

Industrial process data reflects the dynamic changes of operation conditions, which mainly refer to the irregular changes in the dynamic associations between different variables in different time. And this related associations knowledge for process monitoring is often implicit in these dynamic monitoring data which always have richer operation condition information and have not been paid enough attention in current research. To this end, a new process monitoring method based on spatial-based graph convolution neural network (SGCN) is proposed to describe the characteristics of the dynamic associations which can be used to represent the operation status over time. Spatia-temporal graphs are firstly defined, which can be used to represent the characteristics of node attributes (dynamic edge features) dynamically changing with time. Then, the associations between monitoring variables at a certain time can be considered as the node attributes to define a snapshot of the static graph network at the certain time. Finally, the snapshot containing graph structure and node attributes is used as model inputs which are processed to implement graph classification by spatial-based convolution graph neural network with aggregate and readout steps. The feasibility and applicability of this proposed method are demonstrated by our experimental results of benchmark and practical case application.
Deep Domain Adaptation for Pavement Crack Detection
Nov 19, 2021


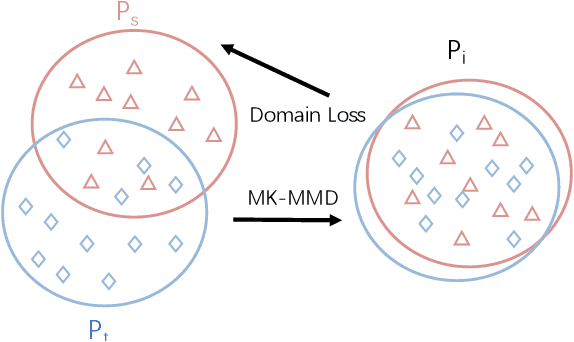
Deep learning-based pavement cracks detection methods often require large-scale labels with detailed crack location information to learn accurate predictions. In practice, however, crack locations are very difficult to be manually annotated due to various visual patterns of pavement crack. In this paper, we propose a Deep Domain Adaptation-based Crack Detection Network (DDACDN), which learns to take advantage of the source domain knowledge to predict the multi-category crack location information in the target domain, where only image-level labels are available. Specifically, DDACDN first extracts crack features from both the source and target domain by a two-branch weights-shared backbone network. And in an effort to achieve the cross-domain adaptation, an intermediate domain is constructed by aggregating the three-scale features from the feature space of each domain to adapt the crack features from the source domain to the target domain. Finally, the network involves the knowledge of both domains and is trained to recognize and localize pavement cracks. To facilitate accurate training and validation for domain adaptation, we use two challenging pavement crack datasets CQU-BPDD and RDD2020. Furthermore, we construct a new large-scale Bituminous Pavement Multi-label Disease Dataset named CQU-BPMDD, which contains 38994 high-resolution pavement disease images to further evaluate the robustness of our model. Extensive experiments demonstrate that DDACDN outperforms state-of-the-art pavement crack detection methods in predicting the crack location on the target domain.
Graph neural network-based fault diagnosis: a review
Nov 16, 2021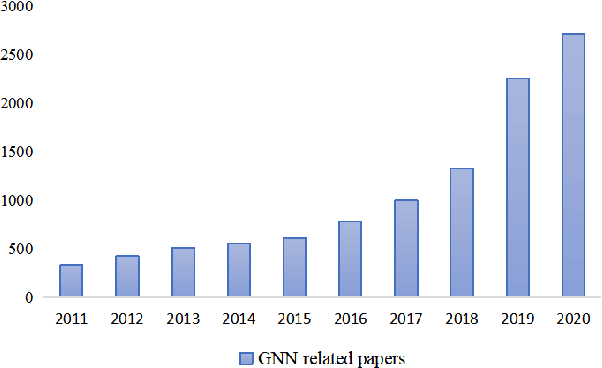
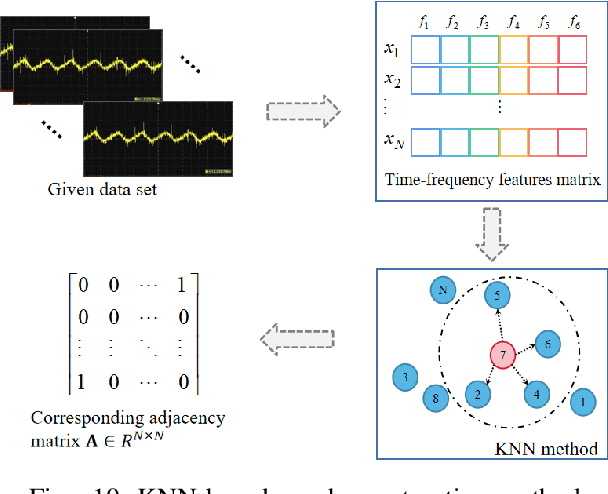
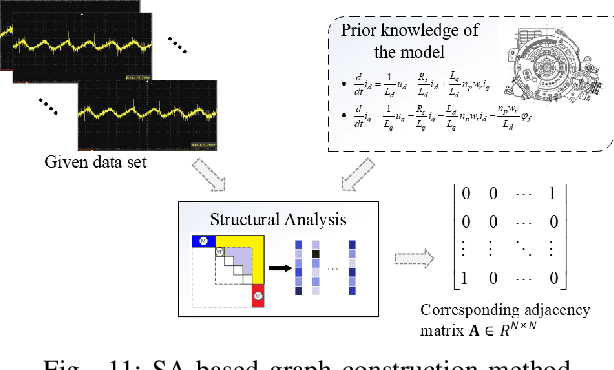
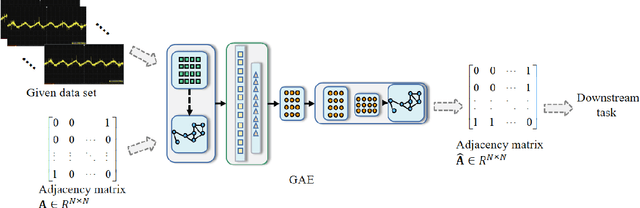
Graph neural network (GNN)-based fault diagnosis (FD) has received increasing attention in recent years, due to the fact that data coming from several application domains can be advantageously represented as graphs. Indeed, this particular representation form has led to superior performance compared to traditional FD approaches. In this review, an easy introduction to GNN, potential applications to the field of fault diagnosis, and future perspectives are given. First, the paper reviews neural network-based FD methods by focusing on their data representations, namely, time-series, images, and graphs. Second, basic principles and principal architectures of GNN are introduced, with attention to graph convolutional networks, graph attention networks, graph sample and aggregate, graph auto-encoder, and spatial-temporal graph convolutional networks. Third, the most relevant fault diagnosis methods based on GNN are validated through the detailed experiments, and conclusions are made that the GNN-based methods can achieve good fault diagnosis performance. Finally, discussions and future challenges are provided.
An ensemble learning framework based on group decision making
Jul 01, 2020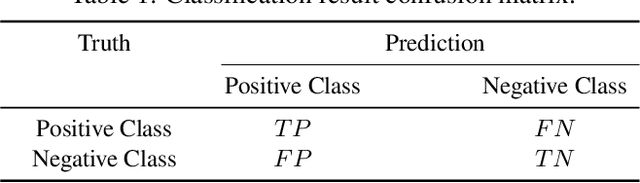
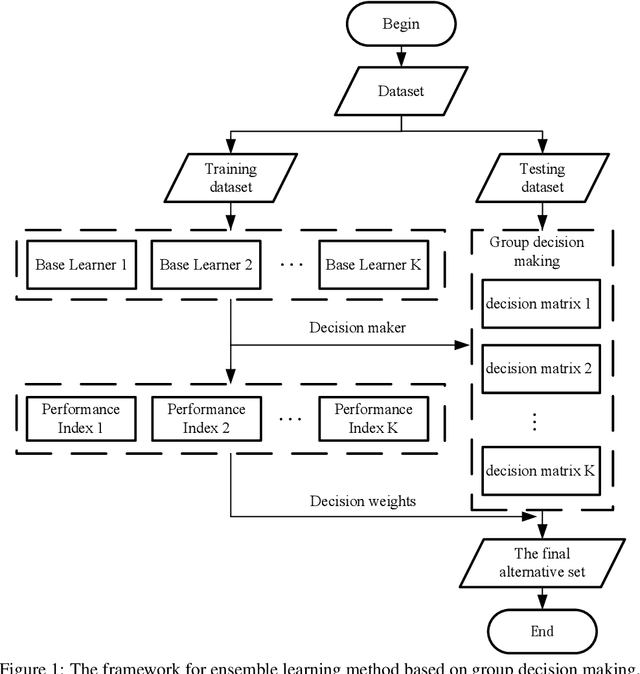
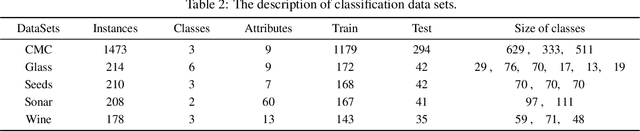
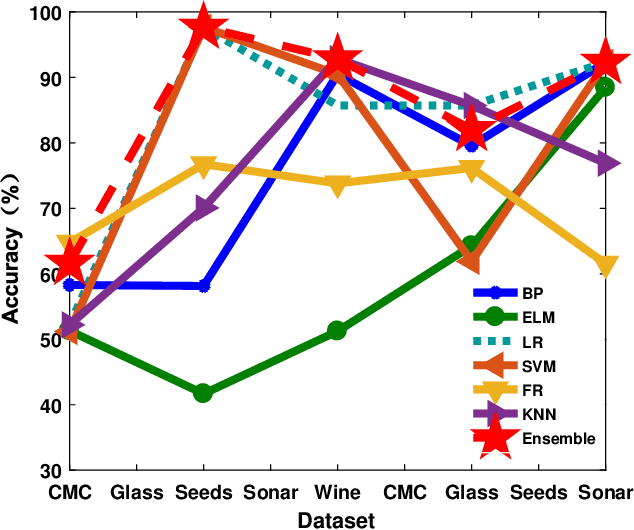
The classification problem is a significant topic in machine learning which aims to teach machines how to group together data by particular criteria. In this paper, a framework for the ensemble learning (EL) method based on group decision making (GDM) has been proposed to resolve this issue. In this framework, base learners can be considered as decision-makers, different categories can be seen as alternatives, classification results obtained by diverse base learners can be considered as performance ratings, and the precision, recall, and accuracy which can reflect the performances of the classification methods can be employed to identify the weights of decision-makers in GDM. Moreover, considering that the precision and recall defined in binary classification problems can not be used directly in the multi-classification problem, the One vs Rest (OvR) has been proposed to obtain the precision and recall of the base learner for each category. The experimental results demonstrate that the proposed EL method based on GDM has higher accuracy than other 6 current popular classification methods in most instances, which verifies the effectiveness of the proposed method.
State Transition Algorithm
Dec 09, 2013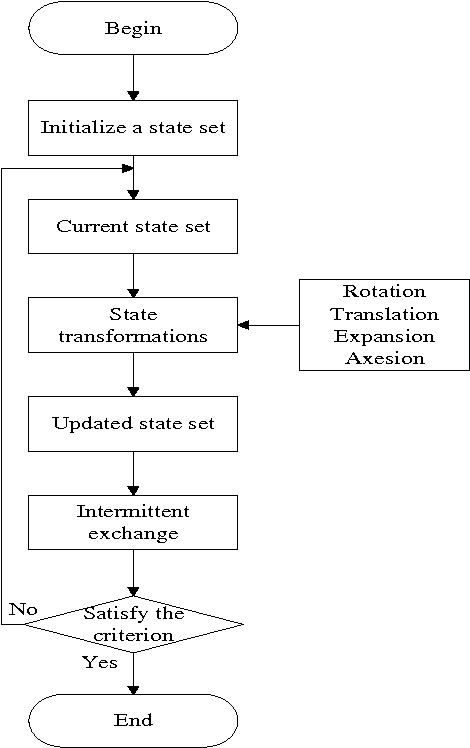

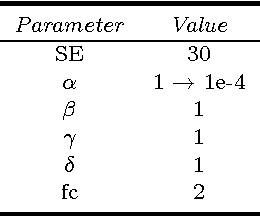
In terms of the concepts of state and state transition, a new heuristic random search algorithm named state transition algorithm is proposed. For continuous function optimization problems, four special transformation operators called rotation, translation, expansion and axesion are designed. Adjusting measures of the transformations are mainly studied to keep the balance of exploration and exploitation. Convergence analysis is also discussed about the algorithm based on random search theory. In the meanwhile, to strengthen the search ability in high dimensional space, communication strategy is introduced into the basic algorithm and intermittent exchange is presented to prevent premature convergence. Finally, experiments are carried out for the algorithms. With 10 common benchmark unconstrained continuous functions used to test the performance, the results show that state transition algorithms are promising algorithms due to their good global search capability and convergence property when compared with some popular algorithms.
* 18 pages, 28 figures