 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Correlation Guided Deep Neural Network
Sep 28, 2024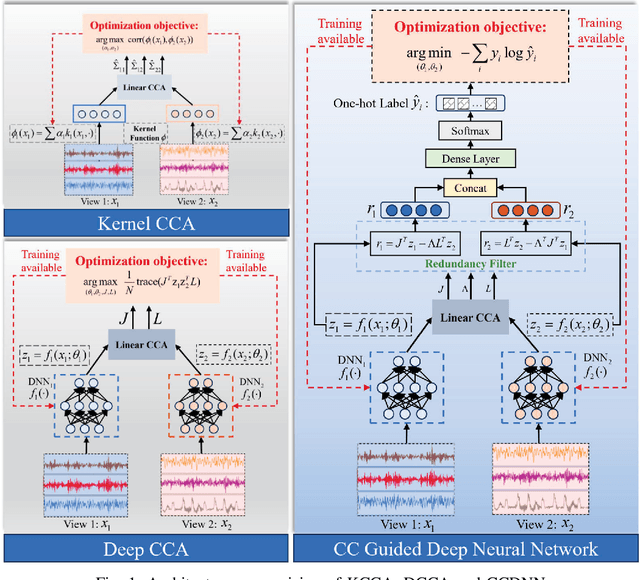
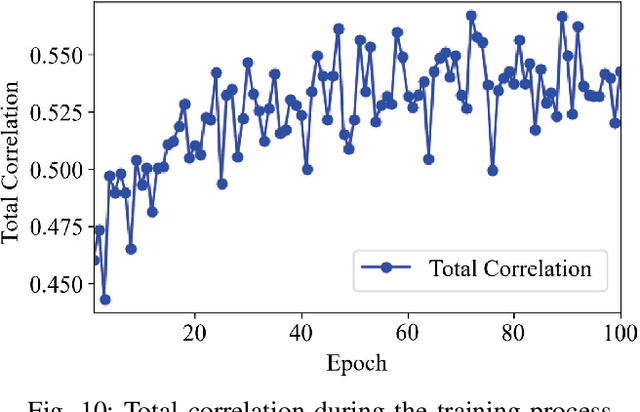
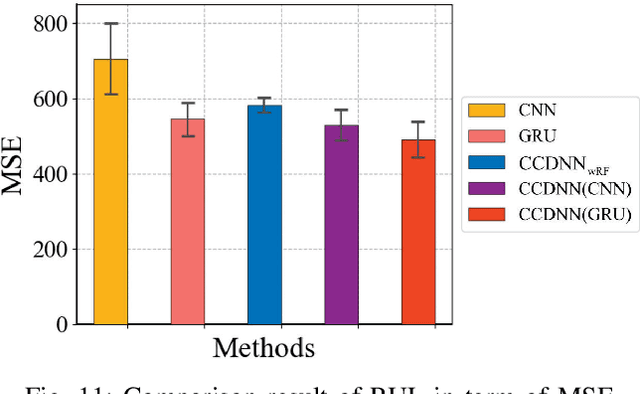
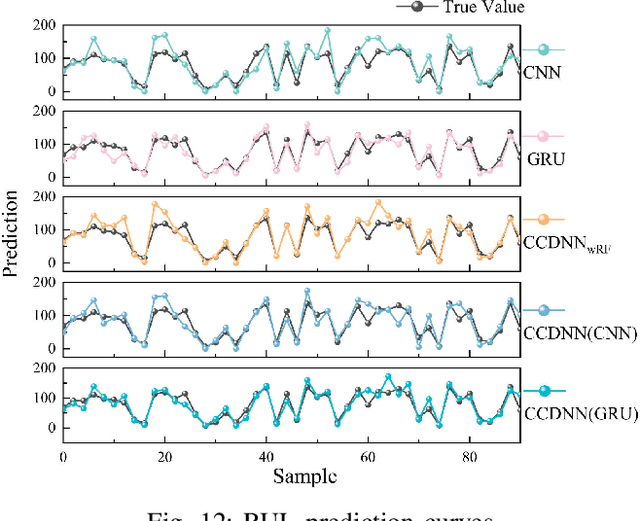
Learning representations of two views of data such that the resulting representations are highly linearly correlated is appealing in machine learning. In this paper, we present a canonical correlation guided learning framework, which allows to be realized by deep neural networks (CCDNN), to learn such a correlated representation. It is also a novel merging of multivariate analysis (MVA) and machine learning, which can be viewed as transforming MVA into end-to-end architectures with the aid of neural networks. Unlike the linear canonical correlation analysis (CCA), kernel CCA and deep CCA, in the proposed method, the optimization formulation is not restricted to maximize correlation, instead we make canonical correlation as a constraint, which preserves the correlated representation learning ability and focuses more on the engineering tasks endowed by optimization formulation, such as reconstruction, classification and prediction. Furthermore, to reduce the redundancy induced by correlation, a redundancy filter is designed. We illustrate the performance of CCDNN on various tasks. In experiments on MNIST dataset, the results show that CCDNN has better reconstruction performance in terms of mean squared error and mean absolute error than DCCA and DCCAE. Also, we present the application of the proposed network to industrial fault diagnosis and remaining useful life cases for the classification and prediction tasks accordingly. The proposed method demonstrates superior performance in both tasks when compared to existing methods. Extension of CCDNN to much more deeper with the aid of residual connection is also presented in appendix.
Graph neural network-based fault diagnosis: a review
Nov 16, 2021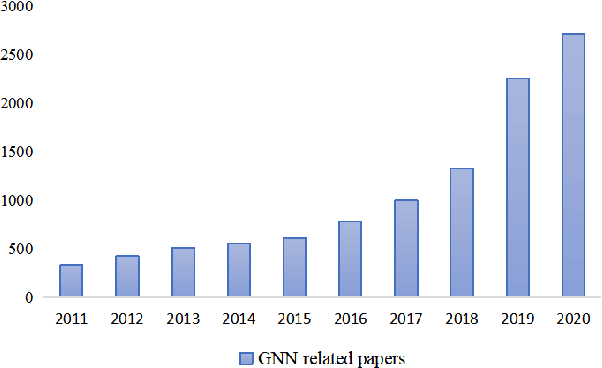
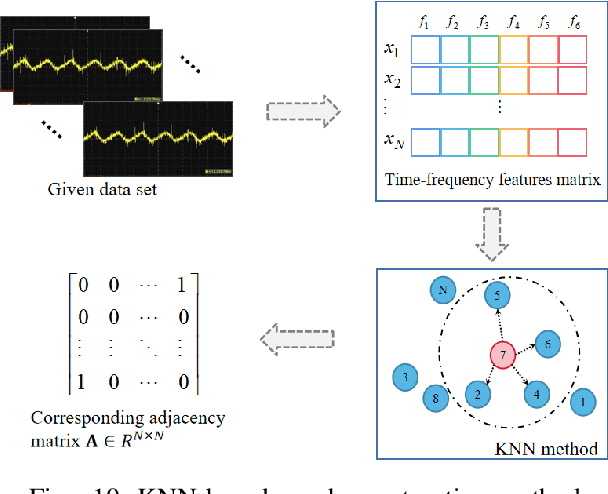
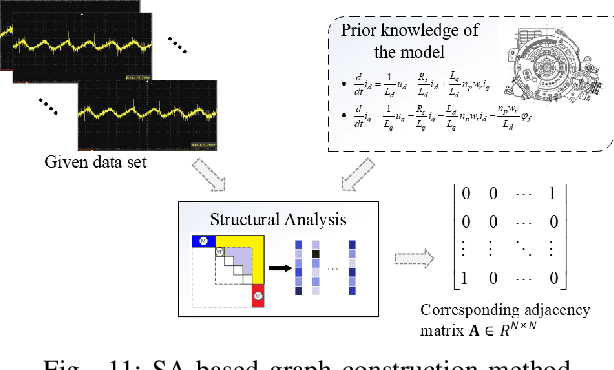
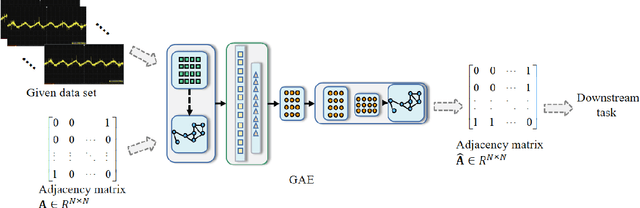
Graph neural network (GNN)-based fault diagnosis (FD) has received increasing attention in recent years, due to the fact that data coming from several application domains can be advantageously represented as graphs. Indeed, this particular representation form has led to superior performance compared to traditional FD approaches. In this review, an easy introduction to GNN, potential applications to the field of fault diagnosis, and future perspectives are given. First, the paper reviews neural network-based FD methods by focusing on their data representations, namely, time-series, images, and graphs. Second, basic principles and principal architectures of GNN are introduced, with attention to graph convolutional networks, graph attention networks, graph sample and aggregate, graph auto-encoder, and spatial-temporal graph convolutional networks. Third, the most relevant fault diagnosis methods based on GNN are validated through the detailed experiments, and conclusions are made that the GNN-based methods can achieve good fault diagnosis performance. Finally, discussions and future challenges are provided.
Curriculum-based Deep Reinforcement Learning for Quantum Control
Jan 02, 2021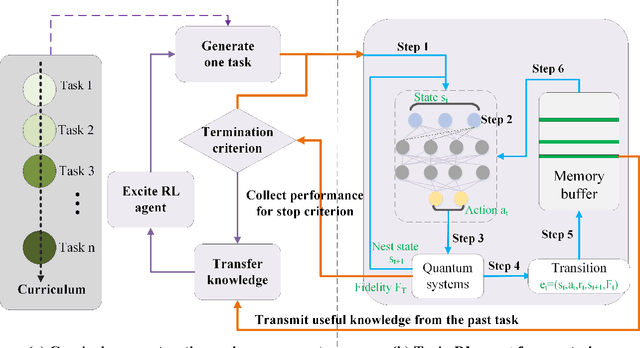
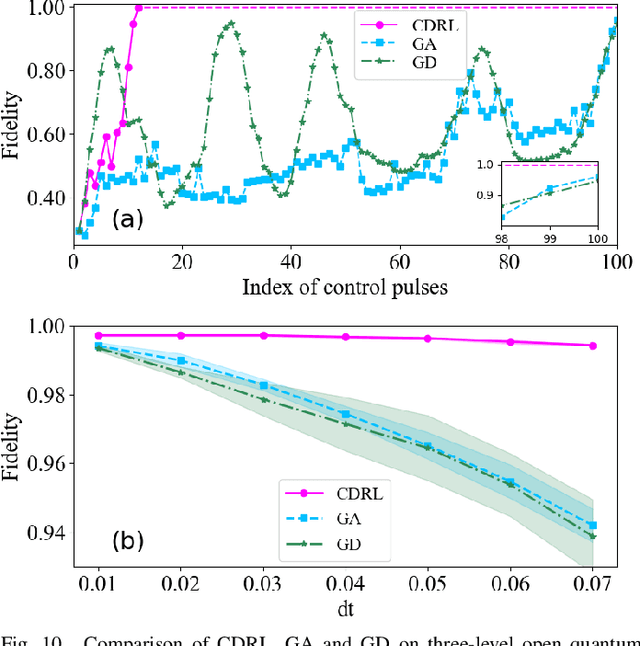


Deep reinforcement learning has been recognized as an efficient technique to design optimal strategies for different complex systems without prior knowledge of the control landscape. To achieve a fast and precise control for quantum systems, we propose a novel deep reinforcement learning approach by constructing a curriculum consisting of a set of intermediate tasks defined by a fidelity threshold. Tasks among a curriculum can be statically determined using empirical knowledge or adaptively generated with the learning process. By transferring knowledge between two successive tasks and sequencing tasks according to their difficulties, the proposed curriculum-based deep reinforcement learning (CDRL) method enables the agent to focus on easy tasks in the early stage, then move onto difficult tasks, and eventually approaches the final task. Numerical simulations on closed quantum systems and open quantum systems demonstrate that the proposed method exhibits improved control performance for quantum systems and also provides an efficient way to identify optimal strategies with fewer control pulses.
Gradient Monitored Reinforcement Learning
May 25, 2020
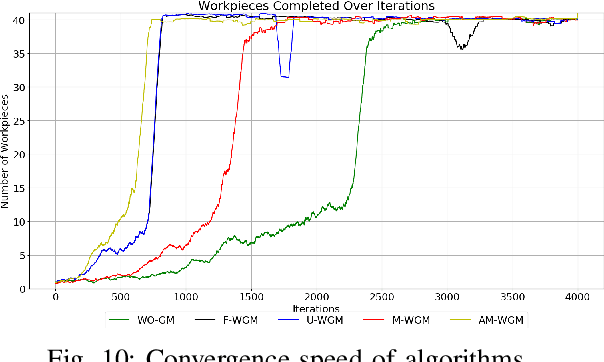
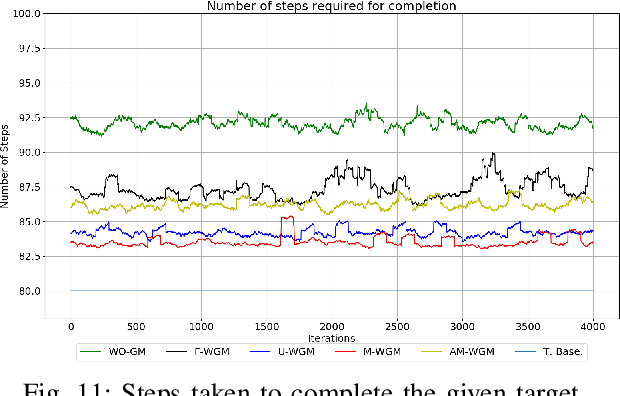
This paper presents a novel neural network training approach for faster convergence and better generalization abilities in deep reinforcement learning. Particularly, we focus on the enhancement of training and evaluation performance in reinforcement learning algorithms by systematically reducing gradient's variance and thereby providing a more targeted learning process. The proposed method which we term as Gradient Monitoring(GM), is an approach to steer the learning in the weight parameters of a neural network based on the dynamic development and feedback from the training process itself. We propose different variants of the GM methodology which have been proven to increase the underlying performance of the model. The one of the proposed variant, Momentum with Gradient Monitoring (M-WGM), allows for a continuous adjustment of the quantum of back-propagated gradients in the network based on certain learning parameters. We further enhance the method with Adaptive Momentum with Gradient Monitoring (AM-WGM) method which allows for automatic adjustment between focused learning of certain weights versus a more dispersed learning depending on the feedback from the rewards collected. As a by-product, it also allows for automatic derivation of the required deep network sizes during training as the algorithm automatically freezes trained weights. The approach is applied to two discrete (Multi-Robot Co-ordination problem and Atari games) and one continuous control task (MuJoCo) using Advantage Actor-Critic (A2C) and Proximal Policy Optimization (PPO) respectively. The results obtained particularly underline the applicability and performance improvements of the methods in terms of generalization capability.