 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Based Deep Reinforcement Learning Hyperheuristics for Job-Shop Scheduling Problems
Jan 16, 2026This paper proposes a policy-based deep reinforcement learning hyper-heuristic framework for solving the Job Shop Scheduling Problem. The hyper-heuristic agent learns to switch scheduling rules based on the system state dynamically. We extend the hyper-heuristic framework with two key mechanisms. First, action prefiltering restricts decision-making to feasible low-level actions, enabling low-level heuristics to be evaluated independently of environmental constraints and providing an unbiased assessment. Second, a commitment mechanism regulates the frequency of heuristic switching. We investigate the impact of different commitment strategies, from step-wise switching to full-episode commitment, on both training behavior and makespan. Additionally, we compare two action selection strategies at the policy level: deterministic greedy selection and stochastic sampling. Computational experiments on standard JSSP benchmarks demonstrate that the proposed approach outperforms traditional heuristics, metaheuristics, and recent neural network-based scheduling methods
Policy-Based Reinforcement Learning with Action Masking for Dynamic Job Shop Scheduling under Uncertainty: Handling Random Arrivals and Machine Failures
Jan 14, 2026We present a novel framework for solving Dynamic Job Shop Scheduling Problems under uncertainty, addressing the challenges introduced by stochastic job arrivals and unexpected machine breakdowns. Our approach follows a model-based paradigm, using Coloured Timed Petri Nets to represent the scheduling environment, and Maskable Proximal Policy Optimization to enable dynamic decision-making while restricting the agent to feasible actions at each decision point. To simulate realistic industrial conditions, dynamic job arrivals are modeled using a Gamma distribution, which captures complex temporal patterns such as bursts, clustering, and fluctuating workloads. Machine failures are modeled using a Weibull distribution to represent age-dependent degradation and wear-out dynamics. These stochastic models enable the framework to reflect real-world manufacturing scenarios better. In addition, we study two action-masking strategies: a non-gradient approach that overrides the probabilities of invalid actions, and a gradient-based approach that assigns negative gradients to invalid actions within the policy network. We conduct extensive experiments on dynamic JSSP benchmarks, demonstrating that our method consistently outperforms traditional heuristic and rule-based approaches in terms of makespan minimization. The results highlight the strength of combining interpretable Petri-net-based models with adaptive reinforcement learning policies, yielding a resilient, scalable, and explainable framework for real-time scheduling in dynamic and uncertain manufacturing environments.
Stabilizing Multimodal Autoencoders: A Theoretical and Empirical Analysis of Fusion Strategies
Dec 23, 2025



In recent years, the development of multimodal autoencoders has gained significant attention due to their potential to handle multimodal complex data types and improve model performance. Understanding the stability and robustness of these models is crucial for optimizing their training, architecture, and real-world applicability. This paper presents an analysis of Lipschitz properties in multimodal autoencoders, combining both theoretical insights and empirical validation to enhance the training stability of these models. We begin by deriving the theoretical Lipschitz constants for aggregation methods within the multimodal autoencoder framework. We then introduce a regularized attention-based fusion method, developed based on our theoretical analysis, which demonstrates improved stability and performance during training. Through a series of experiments, we empirically validate our theoretical findings by estimating the Lipschitz constants across multiple trials and fusion strategies. Our results demonstrate that our proposed fusion function not only aligns with theoretical predictions but also outperforms existing strategies in terms of consistency, convergence speed, and accuracy. This work provides a solid theoretical foundation for understanding fusion in multimodal autoencoders and contributes a solution for enhancing their performance.
Real Time Self-Tuning Adaptive Controllers on Temperature Control Loops using Event-based Game Theory
Jun 16, 2025This paper presents a novel method for enhancing the adaptability of Proportional-Integral-Derivative (PID) controllers in industrial systems using event-based dynamic game theory, which enables the PID controllers to self-learn, optimize, and fine-tune themselves. In contrast to conventional self-learning approaches, our proposed framework offers an event-driven control strategy and game-theoretic learning algorithms. The players collaborate with the PID controllers to dynamically adjust their gains in response to set point changes and disturbances. We provide a theoretical analysis showing sound convergence guarantees for the game given suitable stability ranges of the PID controlled loop. We further introduce an automatic boundary detection mechanism, which helps the players to find an optimal initialization of action spaces and significantly reduces the exploration time. The efficacy of this novel methodology is validated through its implementation in the temperature control loop of a printing press machine. Eventually, the outcomes of the proposed intelligent self-tuning PID controllers are highly promising, particularly in terms of reducing overshoot and settling time.
Impact of Evidence Theory Uncertainty on Training Object Detection Models
Dec 23, 2024This paper investigates the use of Evidence Theory to enhance the training efficiency of object detection models by incorporating uncertainty into the feedback loop. In each training iteration, during the validation phase, Evidence Theory is applied to establish a relationship between ground truth labels and predictions. The Dempster-Shafer rule of combination is used to quantify uncertainty based on the evidence from these predictions. This uncertainty measure is then utilized to weight the feedback loss for the subsequent iteration, allowing the model to adjust its learning dynamically. By experimenting with various uncertainty-weighting strategies, this study aims to determine the most effective method for optimizing feedback to accelerate the training process. The results demonstrate that using uncertainty-based feedback not only reduces training time but can also enhance model performance compared to traditional approaches. This research offers insights into the role of uncertainty in improving machine learning workflows, particularly in object detection, and suggests broader applications for uncertainty-driven training across other AI disciplines.
Predicting Wall Thickness Changes in Cold Forging Processes: An Integrated FEM and Neural Network approach
Nov 21, 2024This study presents a novel approach for predicting wall thickness changes in tubes during the nosing process. Specifically, we first provide a thorough analysis of nosing processes and the influencing parameters. We further set-up a Finite Element Method (FEM) simulation to better analyse the effects of varying process parameters. As however traditional FEM simulations, while accurate, are time-consuming and computationally intensive, which renders them inapplicable for real-time application, we present a novel modeling framework based on specifically designed graph neural networks as surrogate models. To this end, we extend the neural network architecture by directly incorporating information about the nosing process by adding different types of edges and their corresponding encoders to model object interactions. This augmentation enhances model accuracy and opens the possibility for employing precise surrogate models within closed-loop production processes. The proposed approach is evaluated using a new evaluation metric termed area between thickness curves (ABTC). The results demonstrate promising performance and highlight the potential of neural networks as surrogate models in predicting wall thickness changes during nosing forging processes.
Self-optimization in distributed manufacturing systems using Modular State-based Stackelberg Games
Oct 30, 2024In this study, we introduce Modular State-based Stackelberg Games (Mod-SbSG), a novel game structure developed for distributed self-learning in modular manufacturing systems. Mod-SbSG enhances cooperative decision-making among self-learning agents within production systems by integrating State-based Potential Games (SbPG) with Stackelberg games. This hierarchical structure assigns more important modules of the manufacturing system a first-mover advantage, while less important modules respond optimally to the leaders' decisions. This decision-making process differs from typical multi-agent learning algorithms in manufacturing systems, where decisions are made simultaneously. We provide convergence guarantees for the novel game structure and design learning algorithms to account for the hierarchical game structure. We further analyse the effects of single-leader/multiple-follower and multiple-leader/multiple-follower scenarios within a Mod-SbSG. To assess its effectiveness, we implement and test Mod-SbSG in an industrial control setting using two laboratory-scale testbeds featuring sequential and serial-parallel processes. The proposed approach delivers promising results compared to the vanilla SbPG, which reduces overflow by 97.1%, and in some cases, prevents overflow entirely. Additionally, it decreases power consumption by 5-13% while satisfying the production demand, which significantly improves potential (global objective) values.
Transfer learning of state-based potential games for process optimization in decentralized manufacturing systems
Aug 12, 2024
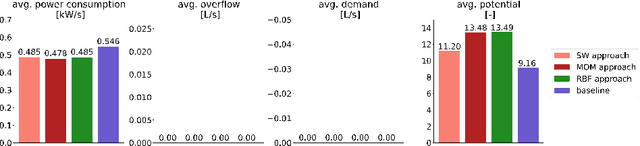
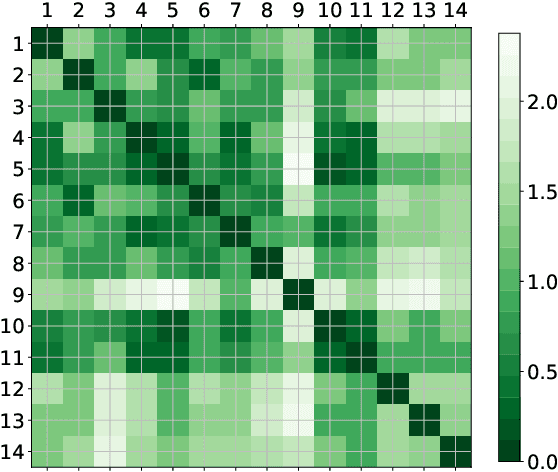
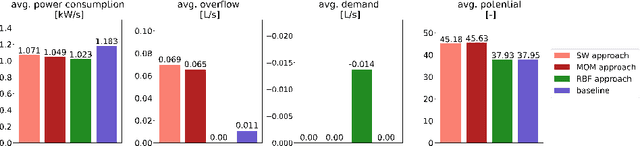
This paper presents a novel transfer learning approach in state-based potential games (TL-SbPGs) for enhancing distributed self-optimization in manufacturing systems. The approach focuses on the practical relevant industrial setting where sharing and transferring gained knowledge among similar-behaved players improves the self-learning mechanism in large-scale systems. With TL-SbPGs, the gained knowledge can be reused by other players to optimize their policies, thereby improving the learning outcomes of the players and accelerating the learning process. To accomplish this goal, we develop transfer learning concepts and similarity criteria for players, which offer two distinct settings: (a) predefined similarities between players and (b) dynamically inferred similarities between players during training. We formally prove the applicability of the SbPG framework in transfer learning. Additionally, we introduce an efficient method to determine the optimal timing and weighting of the transfer learning procedure during the training phase. Through experiments on a laboratory-scale testbed, we demonstrate that TL-SbPGs significantly boost production efficiency while reducing power consumption of the production schedules while also outperforming native SbPGs.
Distributed Stackelberg Strategies in State-based Potential Games for Autonomous Decentralized Learning Manufacturing Systems
Aug 12, 2024



This article describes a novel game structure for autonomously optimizing decentralized manufacturing systems with multi-objective optimization challenges, namely Distributed Stackelberg Strategies in State-Based Potential Games (DS2-SbPG). DS2-SbPG integrates potential games and Stackelberg games, which improves the cooperative trade-off capabilities of potential games and the multi-objective optimization handling by Stackelberg games. Notably, all training procedures remain conducted in a fully distributed manner. DS2-SbPG offers a promising solution to finding optimal trade-offs between objectives by eliminating the complexities of setting up combined objective optimization functions for individual players in self-learning domains, particularly in real-world industrial settings with diverse and numerous objectives between the sub-systems. We further prove that DS2-SbPG constitutes a dynamic potential game that results in corresponding converge guarantees. Experimental validation conducted on a laboratory-scale testbed highlights the efficacy of DS2-SbPG and its two variants, such as DS2-SbPG for single-leader-follower and Stack DS2-SbPG for multi-leader-follower. The results show significant reductions in power consumption and improvements in overall performance, which signals the potential of DS2-SbPG in real-world applications.
Improving Quaternion Neural Networks with Quaternionic Activation Functions
Jun 24, 2024In this paper, we propose novel quaternion activation functions where we modify either the quaternion magnitude or the phase, as an alternative to the commonly used split activation functions. We define criteria that are relevant for quaternion activation functions, and subsequently we propose our novel activation functions based on this analysis. Instead of applying a known activation function like the ReLU or Tanh on the quaternion elements separately, these activation functions consider the quaternion properties and respect the quaternion space $\mathbb{H}$. In particular, all quaternion components are utilized to calculate all output components, carrying out the benefit of the Hamilton product in e.g. the quaternion convolution to the activation functions. The proposed activation functions can be incorporated in arbitrary quaternion valued neural networks trained with gradient descent techniques. We further discuss the derivatives of the proposed activation functions where we observe beneficial properties for the activation functions affecting the phase. Specifically, they prove to be sensitive on basically the whole input range, thus improved gradient flow can be expected. We provide an elaborate experimental evaluation of our proposed quaternion activation functions including comparison with the split ReLU and split Tanh on two image classification tasks using the CIFAR-10 and SVHN dataset. There, especially the quaternion activation functions affecting the phase consistently prove to provide better performance.