 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Learning in State-based Potential Games for Self-Learning Production Systems
Paper and Code
Jun 14, 2024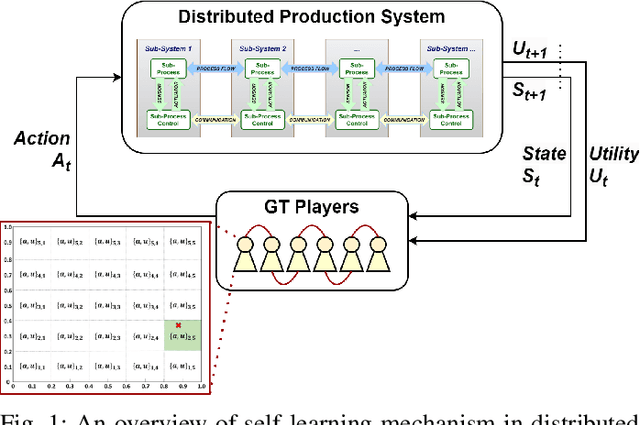
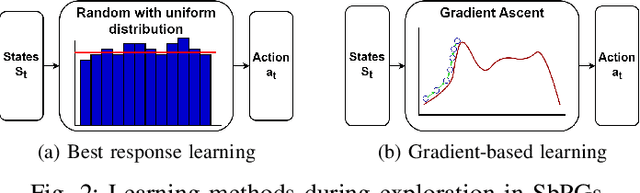


In this paper, we introduce novel gradient-based optimization methods for state-based potential games (SbPGs) within self-learning distributed production systems. SbPGs are recognised for their efficacy in enabling self-optimizing distributed multi-agent systems and offer a proven convergence guarantee, which facilitates collaborative player efforts towards global objectives. Our study strives to replace conventional ad-hoc random exploration-based learning in SbPGs with contemporary gradient-based approaches, which aim for faster convergence and smoother exploration dynamics, thereby shortening training duration while upholding the efficacy of SbPGs. Moreover, we propose three distinct variants for estimating the objective function of gradient-based learning, each developed to suit the unique characteristics of the systems under consideration. To validate our methodology, we apply it to a laboratory testbed, namely Bulk Good Laboratory Plant, which represents a smart and flexible distributed multi-agent production system. The incorporation of gradient-based learning in SbPGs reduces training times and achieves more optimal policies than its baseline.