 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Time Self-Tuning Adaptive Controllers on Temperature Control Loops using Event-based Game Theory
Jun 16, 2025This paper presents a novel method for enhancing the adaptability of Proportional-Integral-Derivative (PID) controllers in industrial systems using event-based dynamic game theory, which enables the PID controllers to self-learn, optimize, and fine-tune themselves. In contrast to conventional self-learning approaches, our proposed framework offers an event-driven control strategy and game-theoretic learning algorithms. The players collaborate with the PID controllers to dynamically adjust their gains in response to set point changes and disturbances. We provide a theoretical analysis showing sound convergence guarantees for the game given suitable stability ranges of the PID controlled loop. We further introduce an automatic boundary detection mechanism, which helps the players to find an optimal initialization of action spaces and significantly reduces the exploration time. The efficacy of this novel methodology is validated through its implementation in the temperature control loop of a printing press machine. Eventually, the outcomes of the proposed intelligent self-tuning PID controllers are highly promising, particularly in terms of reducing overshoot and settling time.
Self-optimization in distributed manufacturing systems using Modular State-based Stackelberg Games
Oct 30, 2024In this study, we introduce Modular State-based Stackelberg Games (Mod-SbSG), a novel game structure developed for distributed self-learning in modular manufacturing systems. Mod-SbSG enhances cooperative decision-making among self-learning agents within production systems by integrating State-based Potential Games (SbPG) with Stackelberg games. This hierarchical structure assigns more important modules of the manufacturing system a first-mover advantage, while less important modules respond optimally to the leaders' decisions. This decision-making process differs from typical multi-agent learning algorithms in manufacturing systems, where decisions are made simultaneously. We provide convergence guarantees for the novel game structure and design learning algorithms to account for the hierarchical game structure. We further analyse the effects of single-leader/multiple-follower and multiple-leader/multiple-follower scenarios within a Mod-SbSG. To assess its effectiveness, we implement and test Mod-SbSG in an industrial control setting using two laboratory-scale testbeds featuring sequential and serial-parallel processes. The proposed approach delivers promising results compared to the vanilla SbPG, which reduces overflow by 97.1%, and in some cases, prevents overflow entirely. Additionally, it decreases power consumption by 5-13% while satisfying the production demand, which significantly improves potential (global objective) values.
Distributed Stackelberg Strategies in State-based Potential Games for Autonomous Decentralized Learning Manufacturing Systems
Aug 12, 2024



This article describes a novel game structure for autonomously optimizing decentralized manufacturing systems with multi-objective optimization challenges, namely Distributed Stackelberg Strategies in State-Based Potential Games (DS2-SbPG). DS2-SbPG integrates potential games and Stackelberg games, which improves the cooperative trade-off capabilities of potential games and the multi-objective optimization handling by Stackelberg games. Notably, all training procedures remain conducted in a fully distributed manner. DS2-SbPG offers a promising solution to finding optimal trade-offs between objectives by eliminating the complexities of setting up combined objective optimization functions for individual players in self-learning domains, particularly in real-world industrial settings with diverse and numerous objectives between the sub-systems. We further prove that DS2-SbPG constitutes a dynamic potential game that results in corresponding converge guarantees. Experimental validation conducted on a laboratory-scale testbed highlights the efficacy of DS2-SbPG and its two variants, such as DS2-SbPG for single-leader-follower and Stack DS2-SbPG for multi-leader-follower. The results show significant reductions in power consumption and improvements in overall performance, which signals the potential of DS2-SbPG in real-world applications.
Transfer learning of state-based potential games for process optimization in decentralized manufacturing systems
Aug 12, 2024
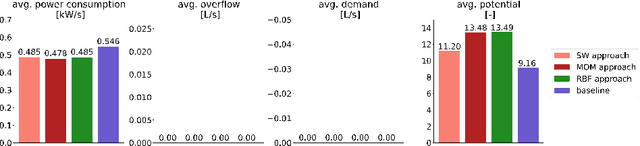
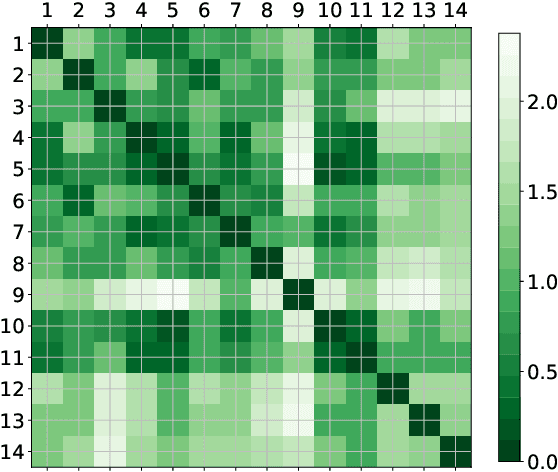
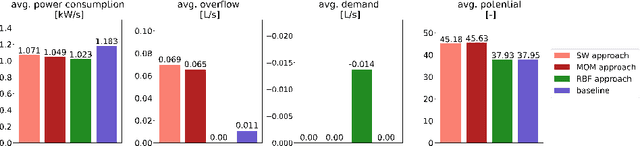
This paper presents a novel transfer learning approach in state-based potential games (TL-SbPGs) for enhancing distributed self-optimization in manufacturing systems. The approach focuses on the practical relevant industrial setting where sharing and transferring gained knowledge among similar-behaved players improves the self-learning mechanism in large-scale systems. With TL-SbPGs, the gained knowledge can be reused by other players to optimize their policies, thereby improving the learning outcomes of the players and accelerating the learning process. To accomplish this goal, we develop transfer learning concepts and similarity criteria for players, which offer two distinct settings: (a) predefined similarities between players and (b) dynamically inferred similarities between players during training. We formally prove the applicability of the SbPG framework in transfer learning. Additionally, we introduce an efficient method to determine the optimal timing and weighting of the transfer learning procedure during the training phase. Through experiments on a laboratory-scale testbed, we demonstrate that TL-SbPGs significantly boost production efficiency while reducing power consumption of the production schedules while also outperforming native SbPGs.
Gradient-based Learning in State-based Potential Games for Self-Learning Production Systems
Jun 14, 2024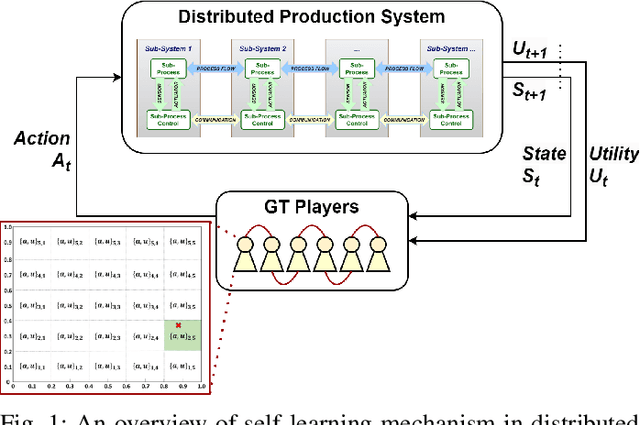
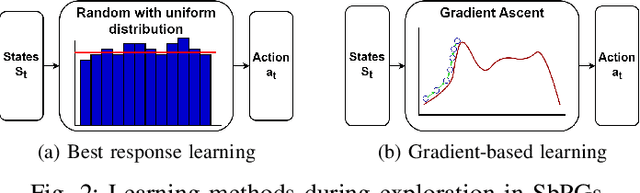


In this paper, we introduce novel gradient-based optimization methods for state-based potential games (SbPGs) within self-learning distributed production systems. SbPGs are recognised for their efficacy in enabling self-optimizing distributed multi-agent systems and offer a proven convergence guarantee, which facilitates collaborative player efforts towards global objectives. Our study strives to replace conventional ad-hoc random exploration-based learning in SbPGs with contemporary gradient-based approaches, which aim for faster convergence and smoother exploration dynamics, thereby shortening training duration while upholding the efficacy of SbPGs. Moreover, we propose three distinct variants for estimating the objective function of gradient-based learning, each developed to suit the unique characteristics of the systems under consideration. To validate our methodology, we apply it to a laboratory testbed, namely Bulk Good Laboratory Plant, which represents a smart and flexible distributed multi-agent production system. The incorporation of gradient-based learning in SbPGs reduces training times and achieves more optimal policies than its baseline.