 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Graph Representation Learning with Dynamic Information Pathways
Mar 10, 2026Multimodal graphs, where nodes contain heterogeneous features such as images and text, are increasingly common in real-world applications. Effectively learning on such graphs requires both adaptive intra-modal message passing and efficient inter-modal aggregation. However, most existing approaches to multimodal graph learning are typically extended from conventional graph neural networks and rely on static structures or dense attention, which limit flexibility and expressive node embedding learning. In this paper, we propose a novel multimodal graph representation learning framework with Dynamic information Pathways (DiP). By introducing modality-specific pseudo nodes, DiP enables dynamic message routing within each modality via proximity-guided pseudo-node interactions and captures inter-modality dependence through efficient information pathways in a shared state space. This design achieves adaptive, expressive, and sparse message propagation across modalities with linear complexity. We conduct the link prediction and node classification tasks to evaluate performance and carry out full experimental analyses. Extensive experiments across multiple benchmarks demonstrate that DiP consistently outperforms baselines.
Enhanced Probabilistic Collision Detection for Motion Planning Under Sensing Uncertainty
Feb 21, 2025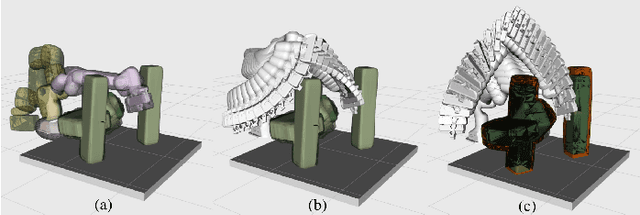
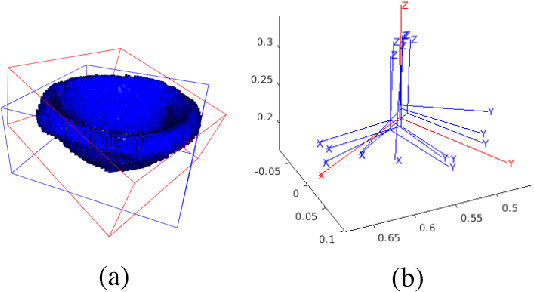
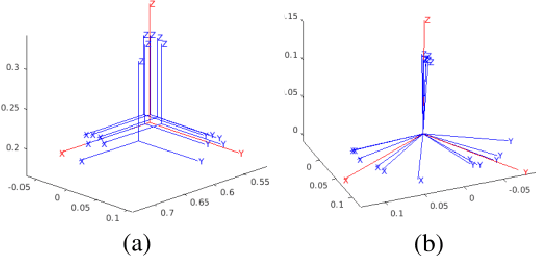

Probabilistic collision detection (PCD) is essential in motion planning for robots operating in unstructured environments, where considering sensing uncertainty helps prevent damage. Existing PCD methods mainly used simplified geometric models and addressed only position estimation errors. This paper presents an enhanced PCD method with two key advancements: (a) using superquadrics for more accurate shape approximation and (b) accounting for both position and orientation estimation errors to improve robustness under sensing uncertainty. Our method first computes an enlarged surface for each object that encapsulates its observed rotated copies, thereby addressing the orientation estimation errors. Then, the collision probability under the position estimation errors is formulated as a chance-constraint problem that is solved with a tight upper bound. Both the two steps leverage the recently developed normal parameterization of superquadric surfaces. Results show that our PCD method is twice as close to the Monte-Carlo sampled baseline as the best existing PCD method and reduces path length by 30% and planning time by 37%, respectively. A Real2Sim pipeline further validates the importance of considering orientation estimation errors, showing that the collision probability of executing the planned path in simulation is only 2%, compared to 9% and 29% when considering only position estimation errors or none at all.
TempoGPT: Enhancing Temporal Reasoning via Quantizing Embedding
Jan 13, 2025Multi-modal language model has made advanced progress in vision and audio, but still faces significant challenges in dealing with complex reasoning tasks in the time series domain. The reasons are twofold. First, labels for multi-modal time series data are coarse and devoid of analysis or reasoning processes. Training with these data cannot improve the model's reasoning capabilities. Second, due to the lack of precise tokenization in processing time series, the representation patterns for temporal and textual information are inconsistent, which hampers the effectiveness of multi-modal alignment. To address these challenges, we propose a multi-modal time series data construction approach and a multi-modal time series language model (TLM), TempoGPT. Specially, we construct multi-modal data for complex reasoning tasks by analyzing the variable-system relationships within a white-box system. Additionally, proposed TempoGPT achieves consistent representation between temporal and textual information by quantizing temporal embeddings, where temporal embeddings are quantized into a series of discrete tokens using a predefined codebook; subsequently, a shared embedding layer processes both temporal and textual tokens. Extensive experiments demonstrate that TempoGPT accurately perceives temporal information, logically infers conclusions, and achieves state-of-the-art in the constructed complex time series reasoning tasks. Moreover, we quantitatively demonstrate the effectiveness of quantizing temporal embeddings in enhancing multi-modal alignment and the reasoning capabilities of TLMs. Code and data are available at https://github.com/zhanghaochuan20/TempoGPT.
Sensorformer: Cross-patch attention with global-patch compression is effective for high-dimensional multivariate time series forecasting
Jan 06, 2025



Among the existing Transformer-based multivariate time series forecasting methods, iTransformer, which treats each variable sequence as a token and only explicitly extracts cross-variable dependencies, and PatchTST, which adopts a channel-independent strategy and only explicitly extracts cross-time dependencies, both significantly outperform most Channel-Dependent Transformer that simultaneously extract cross-time and cross-variable dependencies. This indicates that existing Transformer-based multivariate time series forecasting methods still struggle to effectively fuse these two types of information. We attribute this issue to the dynamic time lags in the causal relationships between different variables. Therefore, we propose a new multivariate time series forecasting Transformer, Sensorformer, which first compresses the global patch information and then simultaneously extracts cross-variable and cross-time dependencies from the compressed representations. Sensorformer can effectively capture the correct inter-variable correlations and causal relationships, even in the presence of dynamic causal lags between variables, while also reducing the computational complexity of pure cross-patch self-attention from $O(D^2 \cdot Patch\_num^2 \cdot d\_model)$ to $O(D^2 \cdot Patch\_num \cdot d\_model)$. Extensive comparative and ablation experiments on 9 mainstream real-world multivariate time series forecasting datasets demonstrate the superiority of Sensorformer. The implementation of Sensorformer, following the style of the Time-series-library and scripts for reproducing the main results, is publicly available at https://github.com/BigYellowTiger/Sensorformer
Mitigating the Negative Impact of Over-association for Conversational Query Production
Sep 29, 2024



Conversational query generation aims at producing search queries from dialogue histories, which are then used to retrieve relevant knowledge from a search engine to help knowledge-based dialogue systems. Trained to maximize the likelihood of gold queries, previous models suffer from the data hunger issue, and they tend to both drop important concepts from dialogue histories and generate irrelevant concepts at inference time. We attribute these issues to the over-association phenomenon where a large number of gold queries are indirectly related to the dialogue topics, because annotators may unconsciously perform reasoning with their background knowledge when generating these gold queries. We carefully analyze the negative effects of this phenomenon on pretrained Seq2seq query producers and then propose effective instance-level weighting strategies for training to mitigate these issues from multiple perspectives. Experiments on two benchmarks, Wizard-of-Internet and DuSinc, show that our strategies effectively alleviate the negative effects and lead to significant performance gains (2%-5% across automatic metrics and human evaluation). Further analysis shows that our model selects better concepts from dialogue histories and is 10 times more data efficient than the baseline. The code is available at https://github.com/DeepLearnXMU/QG-OverAsso.
MA-CDMR: An Intelligent Cross-domain Multicast Routing Method based on Multiagent Deep Reinforcement Learning in Multi-domain SDWN
Sep 11, 2024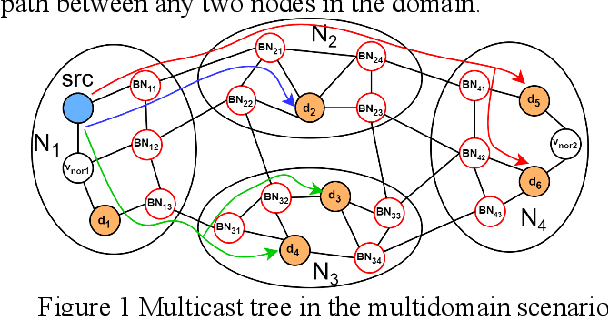
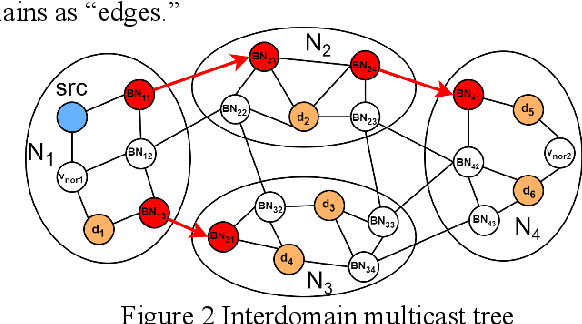
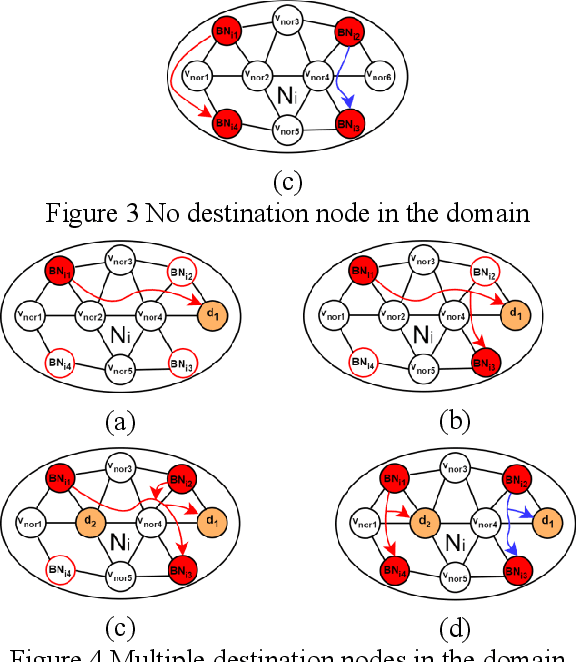
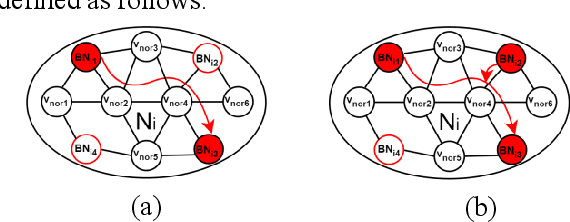
The cross-domain multicast routing problem in a software-defined wireless network with multiple controllers is a classic NP-hard optimization problem. As the network size increases, designing and implementing cross-domain multicast routing paths in the network requires not only designing efficient solution algorithms to obtain the optimal cross-domain multicast tree but also ensuring the timely and flexible acquisition and maintenance of global network state information. However, existing solutions have a limited ability to sense the network traffic state, affecting the quality of service of multicast services. In addition, these methods have difficulty adapting to the highly dynamically changing network states and have slow convergence speeds. To this end, this paper aims to design and implement a multiagent deep reinforcement learning based cross-domain multicast routing method for SDWN with multicontroller domains. First, a multicontroller communication mechanism and a multicast group management module are designed to transfer and synchronize network information between different control domains of the SDWN, thus effectively managing the joining and classification of members in the cross-domain multicast group. Second, a theoretical analysis and proof show that the optimal cross-domain multicast tree includes an interdomain multicast tree and an intradomain multicast tree. An agent is established for each controller, and a cooperation mechanism between multiple agents is designed to effectively optimize cross-domain multicast routing and ensure consistency and validity in the representation of network state information for cross-domain multicast routing decisions. Third, a multiagent reinforcement learning-based method that combines online and offline training is designed to reduce the dependence on the real-time environment and increase the convergence speed of multiple agents.
NDDEs: A Deep Neural Network Framework for Solving Forward and Inverse Problems in Delay Differential Equations
Aug 17, 2024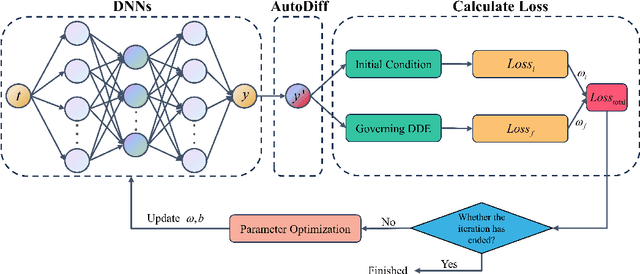

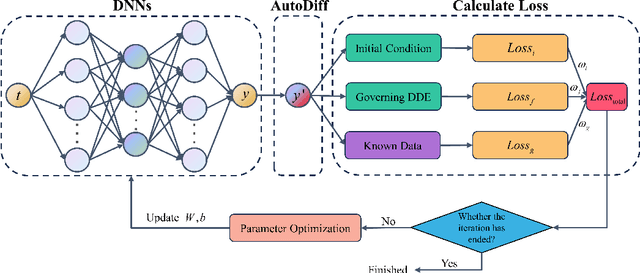

This article proposes a solution framework for delay differential equations (DDEs) based on deep neural networks (DNNs) - the neural delay differential equations (NDDEs), aimed at solving the forward and inverse problems of delay differential equations. This framework embeds the delay differential equations into the neural networks to accommodate the diverse requirements of DDEs in terms of initial conditions, control equations, and known data. NDDEs adjust the network parameters through automatic differentiation and optimization algorithms to minimize the loss function, thereby obtaining numerical solutions to the delay differential equations without the grid dependence and discretization errors typical of traditional numerical methods. In addressing inverse problems, the NDDE framework can utilize observational data to perform precise estimation of single or multiple delay parameters. The results of multiple numerical experiments have shown that NDDEs demonstrate high precision in both forward and inverse problems, proving their effectiveness and promising potential in dealing with delayed differential equation issues.
Rethinking Multi-view Representation Learning via Distilled Disentangling
Mar 29, 2024
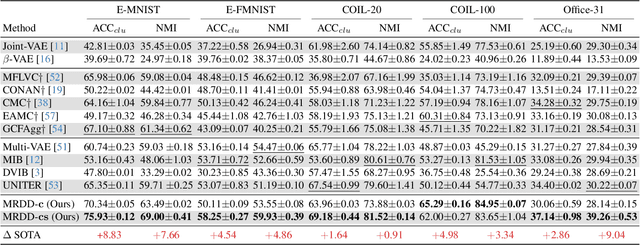
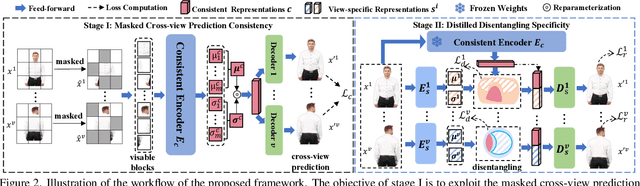
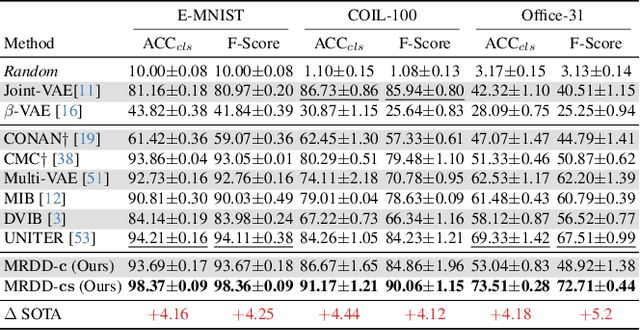
Multi-view representation learning aims to derive robust representations that are both view-consistent and view-specific from diverse data sources. This paper presents an in-depth analysis of existing approaches in this domain, highlighting a commonly overlooked aspect: the redundancy between view-consistent and view-specific representations. To this end, we propose an innovative framework for multi-view representation learning, which incorporates a technique we term 'distilled disentangling'. Our method introduces the concept of masked cross-view prediction, enabling the extraction of compact, high-quality view-consistent representations from various sources without incurring extra computational overhead. Additionally, we develop a distilled disentangling module that efficiently filters out consistency-related information from multi-view representations, resulting in purer view-specific representations. This approach significantly reduces redundancy between view-consistent and view-specific representations, enhancing the overall efficiency of the learning process. Our empirical evaluations reveal that higher mask ratios substantially improve the quality of view-consistent representations. Moreover, we find that reducing the dimensionality of view-consistent representations relative to that of view-specific representations further refines the quality of the combined representations. Our code is accessible at: https://github.com/Guanzhou-Ke/MRDD.
Fine-tuning Large Language Models for Domain-specific Machine Translation
Feb 23, 2024



Large language models (LLMs) have made significant progress in machine translation (MT). However, their potential in domain-specific MT remains under-explored. Current LLM-based MT systems still face several challenges. First, for LLMs with in-context learning, their effectiveness is highly sensitive to input translation examples, and processing them can increase inference costs. They often require extra post-processing due to over-generation. Second, LLMs with fine-tuning on domain-specific data often require high training costs for domain adaptation, and may weaken the zero-shot MT capabilities of LLMs due to over-specialization. The aforementioned methods can struggle to translate rare words in domain transfer scenarios. To address these challenges, this paper proposes a prompt-oriented fine-tuning method, denoted as LlamaIT, to effectively and efficiently fine-tune a general-purpose LLM for domain-specific MT tasks. First, we construct a task-specific mix-domain dataset, which is then used to fine-tune the LLM with LoRA. This can eliminate the need for input translation examples, post-processing, or over-specialization. By zero-shot prompting with instructions, we adapt the MT tasks to the target domain at inference time. To further elicit the MT capability for rare words, we construct new prompts by incorporating domain-specific bilingual vocabulary. We also conduct extensive experiments on both publicly available and self-constructed datasets. The results show that our LlamaIT can significantly enhance the domain-specific MT capabilities of the LLM, meanwhile preserving its zero-shot MT capabilities.
BESTMVQA: A Benchmark Evaluation System for Medical Visual Question Answering
Dec 13, 2023Medical Visual Question Answering (Med-VQA) is a very important task in healthcare industry, which answers a natural language question with a medical image. Existing VQA techniques in information systems can be directly applied to solving the task. However, they often suffer from (i) the data insufficient problem, which makes it difficult to train the state of the arts (SOTAs) for the domain-specific task, and (ii) the reproducibility problem, that many existing models have not been thoroughly evaluated in a unified experimental setup. To address these issues, this paper develops a Benchmark Evaluation SysTem for Medical Visual Question Answering, denoted by BESTMVQA. Given self-collected clinical data, our system provides a useful tool for users to automatically build Med-VQA datasets, which helps overcoming the data insufficient problem. Users also can conveniently select a wide spectrum of SOTA models from our model library to perform a comprehensive empirical study. With simple configurations, our system automatically trains and evaluates the selected models over a benchmark dataset, and reports the comprehensive results for users to develop new techniques or perform medical practice. Limitations of existing work are overcome (i) by the data generation tool, which automatically constructs new datasets from unstructured clinical data, and (ii) by evaluating SOTAs on benchmark datasets in a unified experimental setup. The demonstration video of our system can be found at https://youtu.be/QkEeFlu1x4A. Our code and data will be available soon.