 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPARE: Clinical Optimization with Modular Planning and Assessment via RAG-Enhanced AI-OCT: Superior Decision Support for Percutaneous Coronary Intervention Compared to ChatGPT-5 and Junior Operators
Dec 11, 2025Background: While intravascular imaging, particularly optical coherence tomography (OCT), improves percutaneous coronary intervention (PCI) outcomes, its interpretation is operator-dependent. General-purpose artificial intelligence (AI) shows promise but lacks domain-specific reliability. We evaluated the performance of CA-GPT, a novel large model deployed on an AI-OCT system, against that of the general-purpose ChatGPT-5 and junior physicians for OCT-guided PCI planning and assessment. Methods: In this single-center analysis of 96 patients who underwent OCT-guided PCI, the procedural decisions generated by the CA-GPT, ChatGPT-5, and junior physicians were compared with an expert-derived procedural record. Agreement was assessed using ten pre-specified metrics across pre-PCI and post-PCI phases. Results: For pre-PCI planning, CA-GPT demonstrated significantly higher median agreement scores (5[IQR 3.75-5]) compared to both ChatGPT-5 (3[2-4], P<0.001) and junior physicians (4[3-4], P<0.001). CA-GPT significantly outperformed ChatGPT-5 across all individual pre-PCI metrics and showed superior performance to junior physicians in stent diameter (90.3% vs. 72.2%, P<0.05) and length selection (80.6% vs. 52.8%, P<0.01). In post-PCI assessment, CA-GPT maintained excellent overall agreement (5[4.75-5]), significantly higher than both ChatGPT-5 (4[4-5], P<0.001) and junior physicians (5[4-5], P<0.05). Subgroup analysis confirmed CA-GPT's robust performance advantage in complex scenarios. Conclusion: The CA-GPT-based AI-OCT system achieved superior decision-making agreement versus a general-purpose large language model and junior physicians across both PCI planning and assessment phases. This approach provides a standardized and reliable method for intravascular imaging interpretation, demonstrating significant potential to augment operator expertise and optimize OCT-guided PCI.
Process-aware Human Activity Recognition
Nov 13, 2024



Humans naturally follow distinct patterns when conducting their daily activities, which are driven by established practices and processes, such as production workflows, social norms and daily routines. Human activity recognition (HAR) algorithms usually use neural networks or machine learning techniques to analyse inherent relationships within the data. However, these approaches often overlook the contextual information in which the data are generated, potentially limiting their effectiveness. We propose a novel approach that incorporates process information from context to enhance the HAR performance. Specifically, we align probabilistic events generated by machine learning models with process models derived from contextual information. This alignment adaptively weighs these two sources of information to optimise HAR accuracy. Our experiments demonstrate that our approach achieves better accuracy and Macro F1-score compared to baseline models.
Exploring the traditional NMT model and Large Language Model for chat translation
Sep 24, 2024



This paper describes the submissions of Huawei Translation Services Center(HW-TSC) to WMT24 chat translation shared task on English$\leftrightarrow$Germany (en-de) bidirection. The experiments involved fine-tuning models using chat data and exploring various strategies, including Minimum Bayesian Risk (MBR) decoding and self-training. The results show significant performance improvements in certain directions, with the MBR self-training method achieving the best results. The Large Language Model also discusses the challenges and potential avenues for further research in the field of chat translation.
Fine-tuning Large Language Models for Domain-specific Machine Translation
Feb 23, 2024



Large language models (LLMs) have made significant progress in machine translation (MT). However, their potential in domain-specific MT remains under-explored. Current LLM-based MT systems still face several challenges. First, for LLMs with in-context learning, their effectiveness is highly sensitive to input translation examples, and processing them can increase inference costs. They often require extra post-processing due to over-generation. Second, LLMs with fine-tuning on domain-specific data often require high training costs for domain adaptation, and may weaken the zero-shot MT capabilities of LLMs due to over-specialization. The aforementioned methods can struggle to translate rare words in domain transfer scenarios. To address these challenges, this paper proposes a prompt-oriented fine-tuning method, denoted as LlamaIT, to effectively and efficiently fine-tune a general-purpose LLM for domain-specific MT tasks. First, we construct a task-specific mix-domain dataset, which is then used to fine-tune the LLM with LoRA. This can eliminate the need for input translation examples, post-processing, or over-specialization. By zero-shot prompting with instructions, we adapt the MT tasks to the target domain at inference time. To further elicit the MT capability for rare words, we construct new prompts by incorporating domain-specific bilingual vocabulary. We also conduct extensive experiments on both publicly available and self-constructed datasets. The results show that our LlamaIT can significantly enhance the domain-specific MT capabilities of the LLM, meanwhile preserving its zero-shot MT capabilities.
Alignment-based conformance checking over probabilistic events
Sep 09, 2022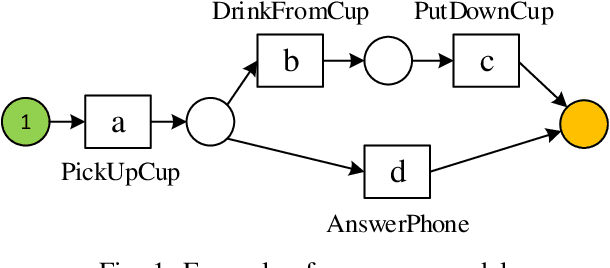
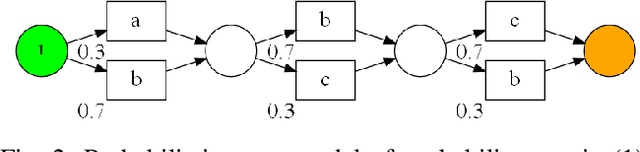
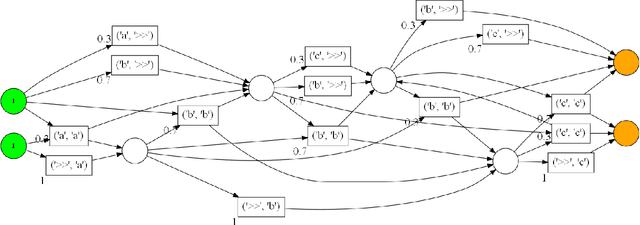
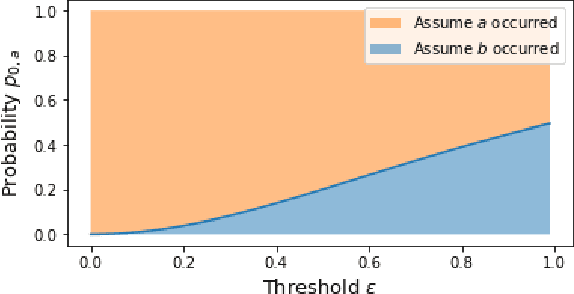
Conformance checking techniques allow us to evaluate how well some exhibited behaviour, represented by a trace of monitored events, conforms to a specified process model. Modern monitoring and activity recognition technologies, such as those relying on sensors, the IoT, statistics and AI, can produce a wealth of relevant event data. However, this data is typically characterised by noise and uncertainty, in contrast to the assumption of a deterministic event log required by conformance checking algorithms. In this paper, we extend alignment-based conformance checking to function under a probabilistic event log. We introduce a probabilistic trace model and alignment cost function, and a custom threshold parameter that controls the level of trust on the event data vs. the process model. The resulting algorithm yields an increased fitness score in the presence of aligned events of sufficiently high probability compared to traditional alignment, and thus fewer false positive deviations. We explain the algorithm and its motivation both from a formal and intuitive perspective, and demonstrate its functionality in comparison with deterministic alignment using a set of theoretical examples.