 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess-aware Human Activity Recognition
Nov 13, 2024



Humans naturally follow distinct patterns when conducting their daily activities, which are driven by established practices and processes, such as production workflows, social norms and daily routines. Human activity recognition (HAR) algorithms usually use neural networks or machine learning techniques to analyse inherent relationships within the data. However, these approaches often overlook the contextual information in which the data are generated, potentially limiting their effectiveness. We propose a novel approach that incorporates process information from context to enhance the HAR performance. Specifically, we align probabilistic events generated by machine learning models with process models derived from contextual information. This alignment adaptively weighs these two sources of information to optimise HAR accuracy. Our experiments demonstrate that our approach achieves better accuracy and Macro F1-score compared to baseline models.
Alignment-based conformance checking over probabilistic events
Sep 09, 2022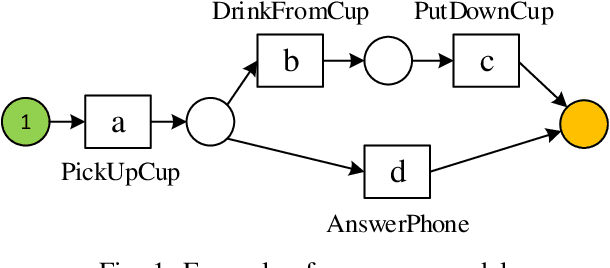
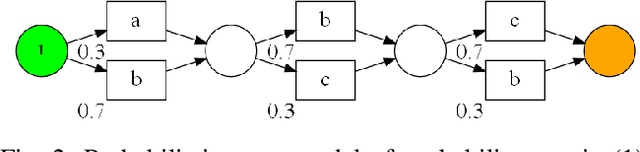
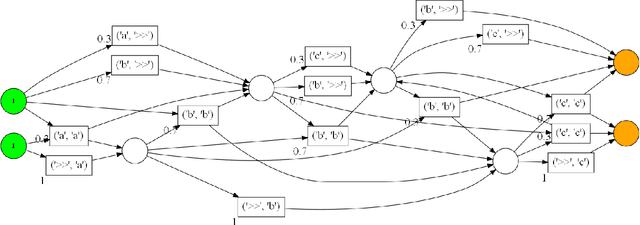
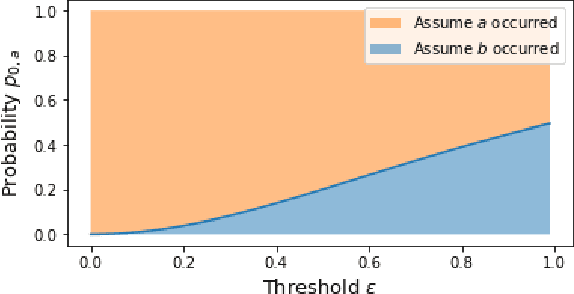
Conformance checking techniques allow us to evaluate how well some exhibited behaviour, represented by a trace of monitored events, conforms to a specified process model. Modern monitoring and activity recognition technologies, such as those relying on sensors, the IoT, statistics and AI, can produce a wealth of relevant event data. However, this data is typically characterised by noise and uncertainty, in contrast to the assumption of a deterministic event log required by conformance checking algorithms. In this paper, we extend alignment-based conformance checking to function under a probabilistic event log. We introduce a probabilistic trace model and alignment cost function, and a custom threshold parameter that controls the level of trust on the event data vs. the process model. The resulting algorithm yields an increased fitness score in the presence of aligned events of sufficiently high probability compared to traditional alignment, and thus fewer false positive deviations. We explain the algorithm and its motivation both from a formal and intuitive perspective, and demonstrate its functionality in comparison with deterministic alignment using a set of theoretical examples.
Dr.Aid: Supporting Data-governance Rule Compliance for Decentralized Collaboration in an Automated Way
Oct 03, 2021


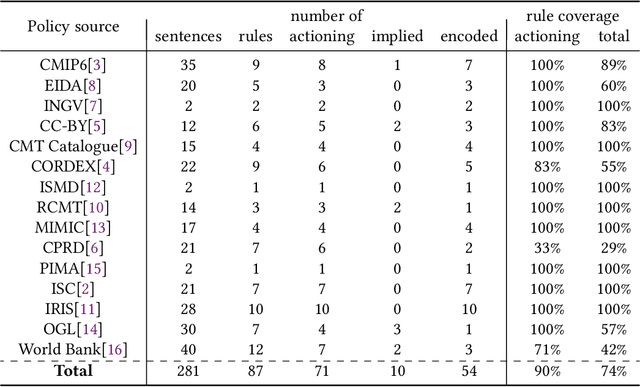
Collaboration across institutional boundaries is widespread and increasing today. It depends on federations sharing data that often have governance rules or external regulations restricting their use. However, the handling of data governance rules (aka. data-use policies) remains manual, time-consuming and error-prone, limiting the rate at which collaborations can form and respond to challenges and opportunities, inhibiting citizen science and reducing data providers' trust in compliance. Using an automated system to facilitate compliance handling reduces substantially the time needed for such non-mission work, thereby accelerating collaboration and improving productivity. We present a framework, Dr.Aid, that helps individuals, organisations and federations comply with data rules, using automation to track which rules are applicable as data is passed between processes and as derived data is generated. It encodes data-governance rules using a formal language and performs reasoning on multi-input-multi-output data-flow graphs in decentralised contexts. We test its power and utility by working with users performing cyclone tracking and earthquake modelling to support mitigation and emergency response. We query standard provenance traces to detach Dr.Aid from details of the tools and systems they are using, as these inevitably vary across members of a federation and through time. We evaluate the model in three aspects by encoding real-life data-use policies from diverse fields, showing its capability for real-world usage and its advantages compared with traditional frameworks. We argue that this approach will lead to more agile, more productive and more trustworthy collaborations and show that the approach can be adopted incrementally. This, in-turn, will allow more appropriate data policies to emerge opening up new forms of collaboration.