 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormally Verified Neurosymbolic Trajectory Learning via Tensor-based Linear Temporal Logic on Finite Traces
Jan 23, 2025
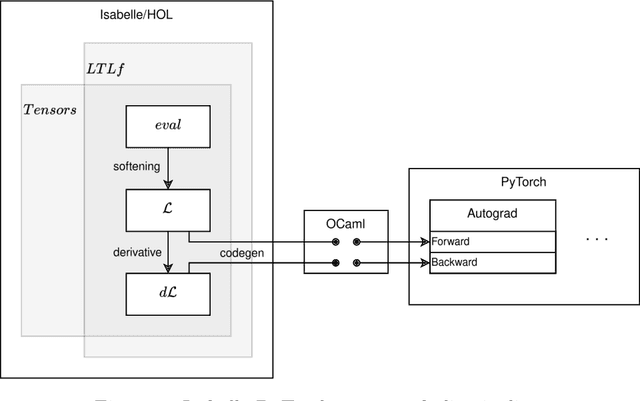
We present a novel formalisation of tensor semantics for linear temporal logic on finite traces (LTLf), with formal proofs of correctness carried out in the theorem prover Isabelle/HOL. We demonstrate that this formalisation can be integrated into a neurosymbolic learning process by defining and verifying a differentiable loss function for the LTLf constraints, and automatically generating an implementation that integrates with PyTorch. We show that, by using this loss, the process learns to satisfy pre-specified logical constraints. Our approach offers a fully rigorous framework for constrained training, eliminating many of the inherent risks of ad-hoc, manual implementations of logical aspects directly in an "unsafe" programming language such as Python, while retaining efficiency in implementation.
Process-aware Human Activity Recognition
Nov 13, 2024



Humans naturally follow distinct patterns when conducting their daily activities, which are driven by established practices and processes, such as production workflows, social norms and daily routines. Human activity recognition (HAR) algorithms usually use neural networks or machine learning techniques to analyse inherent relationships within the data. However, these approaches often overlook the contextual information in which the data are generated, potentially limiting their effectiveness. We propose a novel approach that incorporates process information from context to enhance the HAR performance. Specifically, we align probabilistic events generated by machine learning models with process models derived from contextual information. This alignment adaptively weighs these two sources of information to optimise HAR accuracy. Our experiments demonstrate that our approach achieves better accuracy and Macro F1-score compared to baseline models.
Neurosymbolic AI for Reasoning on Biomedical Knowledge Graphs
Jul 17, 2023Biomedical datasets are often modeled as knowledge graphs (KGs) because they capture the multi-relational, heterogeneous, and dynamic natures of biomedical systems. KG completion (KGC), can, therefore, help researchers make predictions to inform tasks like drug repositioning. While previous approaches for KGC were either rule-based or embedding-based, hybrid approaches based on neurosymbolic artificial intelligence are becoming more popular. Many of these methods possess unique characteristics which make them even better suited toward biomedical challenges. Here, we survey such approaches with an emphasis on their utilities and prospective benefits for biomedicine.
Neurosymbolic AI for Reasoning on Graph Structures: A Survey
Feb 14, 2023



Neurosymbolic AI is an increasingly active area of research which aims to combine symbolic reasoning methods with deep learning to generate models with both high predictive performance and some degree of human-level comprehensibility. As knowledge graphs are becoming a popular way to represent heterogeneous and multi-relational data, methods for reasoning on graph structures have attempted to follow this neurosymbolic paradigm. Traditionally, such approaches have utilized either rule-based inference or generated representative numerical embeddings from which patterns could be extracted. However, several recent studies have attempted to bridge this dichotomy in ways that facilitate interpretability, maintain performance, and integrate expert knowledge. Within this article, we survey a breadth of methods that perform neurosymbolic reasoning tasks on graph structures. To better compare the various methods, we propose a novel taxonomy by which we can classify them. Specifically, we propose three major categories: (1) logically-informed embedding approaches, (2) embedding approaches with logical constraints, and (3) rule-learning approaches. Alongside the taxonomy, we provide a tabular overview of the approaches and links to their source code, if available, for more direct comparison. Finally, we discuss the applications on which these methods were primarily used and propose several prospective directions toward which this new field of research could evolve.
Constrained Training of Neural Networks via Theorem Proving
Jul 08, 2022
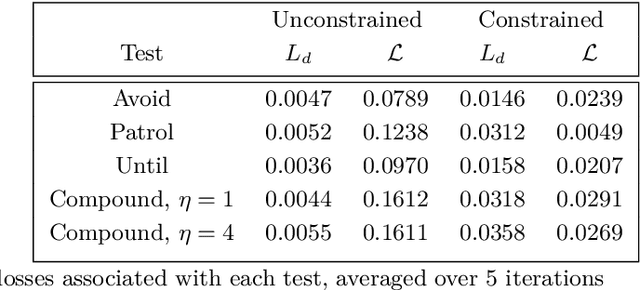
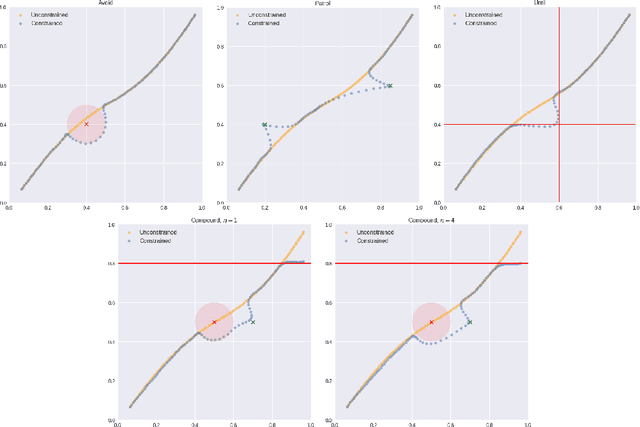
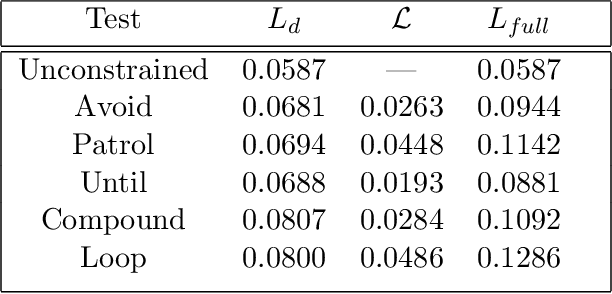
We introduce a theorem proving approach to the specification and generation of temporal logical constraints for training neural networks. We formalise a deep embedding of linear temporal logic over finite traces (LTL$_f$) and an associated evaluation function characterising its semantics within the higher-order logic of the Isabelle theorem prover. We then proceed to formalise a loss function $\mathcal{L}$ that we formally prove to be sound, and differentiable to a function $d\mathcal{L}$. We subsequently use Isabelle's automatic code generation mechanism to produce OCaml versions of LTL$_f$, $\mathcal{L}$ and $d\mathcal{L}$ that we integrate with PyTorch via OCaml bindings for Python. We show that, when used for training in an existing deep learning framework for dynamic movement, our approach produces expected results for common movement specification patterns such as obstacle avoidance and patrolling. The distinctive benefit of our approach is the fully rigorous method for constrained training, eliminating many of the risks inherent to ad-hoc implementations of logical aspects directly in an "unsafe" programming language such as Python.
Interpretable Machine Learning Classifiers for Brain Tumour Survival Prediction
Jun 17, 2021



Prediction of survival in patients diagnosed with a brain tumour is challenging because of heterogeneous tumour behaviours and responses to treatment. Better estimations of prognosis would support treatment planning and patient support. Advances in machine learning have informed development of clinical predictive models, but their integration into clinical practice is almost non-existent. One reasons for this is the lack of interpretability of models. In this paper, we use a novel brain tumour dataset to compare two interpretable rule list models against popular machine learning approaches for brain tumour survival prediction. All models are quantitatively evaluated using standard performance metrics. The rule lists are also qualitatively assessed for their interpretability and clinical utility. The interpretability of the black box machine learning models is evaluated using two post-hoc explanation techniques, LIME and SHAP. Our results show that the rule lists were only slightly outperformed by the black box models. We demonstrate that rule list algorithms produced simple decision lists that align with clinical expertise. By comparison, post-hoc interpretability methods applied to black box models may produce unreliable explanations of local model predictions. Model interpretability is essential for understanding differences in predictive performance and for integration into clinical practice.