 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormally Verified Neurosymbolic Trajectory Learning via Tensor-based Linear Temporal Logic on Finite Traces
Jan 23, 2025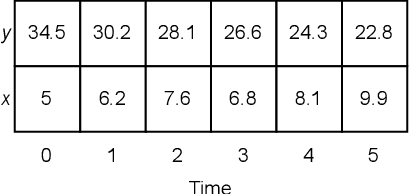
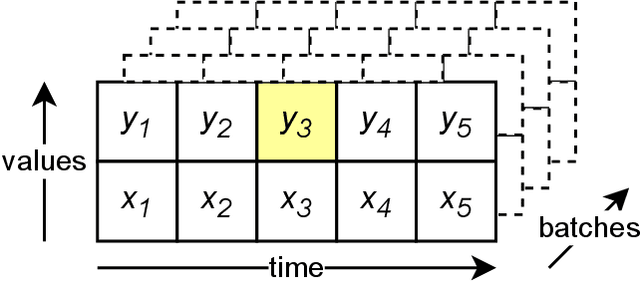
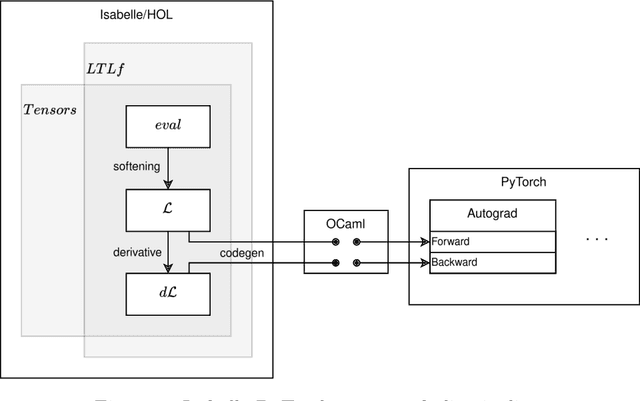
We present a novel formalisation of tensor semantics for linear temporal logic on finite traces (LTLf), with formal proofs of correctness carried out in the theorem prover Isabelle/HOL. We demonstrate that this formalisation can be integrated into a neurosymbolic learning process by defining and verifying a differentiable loss function for the LTLf constraints, and automatically generating an implementation that integrates with PyTorch. We show that, by using this loss, the process learns to satisfy pre-specified logical constraints. Our approach offers a fully rigorous framework for constrained training, eliminating many of the inherent risks of ad-hoc, manual implementations of logical aspects directly in an "unsafe" programming language such as Python, while retaining efficiency in implementation.
Constrained Training of Neural Networks via Theorem Proving
Jul 08, 2022
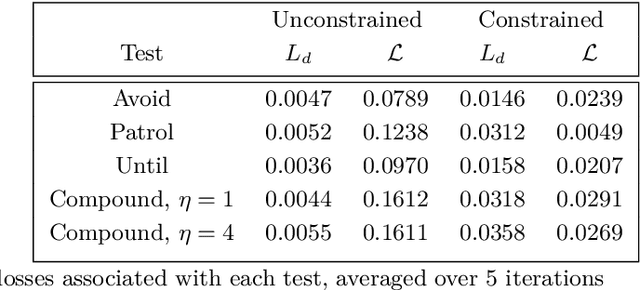
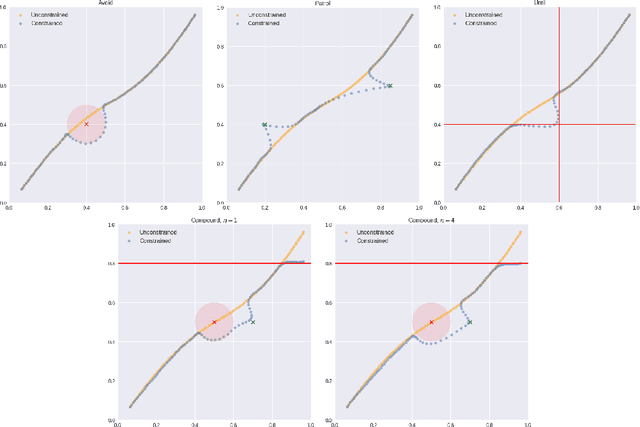
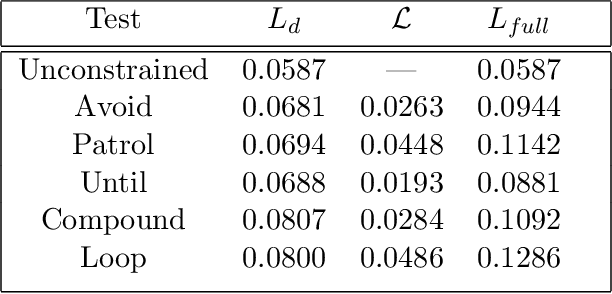
We introduce a theorem proving approach to the specification and generation of temporal logical constraints for training neural networks. We formalise a deep embedding of linear temporal logic over finite traces (LTL$_f$) and an associated evaluation function characterising its semantics within the higher-order logic of the Isabelle theorem prover. We then proceed to formalise a loss function $\mathcal{L}$ that we formally prove to be sound, and differentiable to a function $d\mathcal{L}$. We subsequently use Isabelle's automatic code generation mechanism to produce OCaml versions of LTL$_f$, $\mathcal{L}$ and $d\mathcal{L}$ that we integrate with PyTorch via OCaml bindings for Python. We show that, when used for training in an existing deep learning framework for dynamic movement, our approach produces expected results for common movement specification patterns such as obstacle avoidance and patrolling. The distinctive benefit of our approach is the fully rigorous method for constrained training, eliminating many of the risks inherent to ad-hoc implementations of logical aspects directly in an "unsafe" programming language such as Python.
Formalising the Foundations of Discrete Reinforcement Learning in Isabelle/HOL
Dec 11, 2021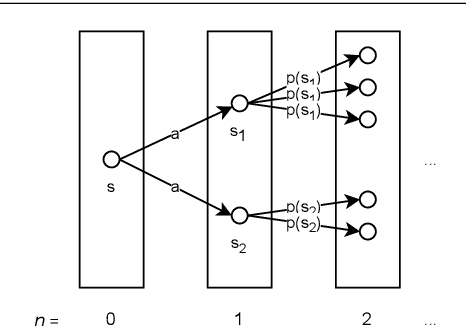
We present a formalisation of finite Markov decision processes with rewards in the Isabelle theorem prover. We focus on the foundations required for dynamic programming and the use of reinforcement learning agents over such processes. In particular, we derive the Bellman equation from first principles (in both scalar and vector form), derive a vector calculation that produces the expected value of any policy p, and go on to prove the existence of a universally optimal policy where there is a discounting factor less than one. Lastly, we prove that the value iteration and the policy iteration algorithms work in finite time, producing an epsilon-optimal and a fully optimal policy respectively.