 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the traditional NMT model and Large Language Model for chat translation
Sep 24, 2024



This paper describes the submissions of Huawei Translation Services Center(HW-TSC) to WMT24 chat translation shared task on English$\leftrightarrow$Germany (en-de) bidirection. The experiments involved fine-tuning models using chat data and exploring various strategies, including Minimum Bayesian Risk (MBR) decoding and self-training. The results show significant performance improvements in certain directions, with the MBR self-training method achieving the best results. The Large Language Model also discusses the challenges and potential avenues for further research in the field of chat translation.
Multilingual Transfer and Domain Adaptation for Low-Resource Languages of Spain
Sep 24, 2024This article introduces the submission status of the Translation into Low-Resource Languages of Spain task at (WMT 2024) by Huawei Translation Service Center (HW-TSC). We participated in three translation tasks: spanish to aragonese (es-arg), spanish to aranese (es-arn), and spanish to asturian (es-ast). For these three translation tasks, we use training strategies such as multilingual transfer, regularized dropout, forward translation and back translation, labse denoising, transduction ensemble learning and other strategies to neural machine translation (NMT) model based on training deep transformer-big architecture. By using these enhancement strategies, our submission achieved a competitive result in the final evaluation.
Machine Translation Advancements of Low-Resource Indian Languages by Transfer Learning
Sep 24, 2024



This paper introduces the submission by Huawei Translation Center (HW-TSC) to the WMT24 Indian Languages Machine Translation (MT) Shared Task. To develop a reliable machine translation system for low-resource Indian languages, we employed two distinct knowledge transfer strategies, taking into account the characteristics of the language scripts and the support available from existing open-source models for Indian languages. For Assamese(as) and Manipuri(mn), we fine-tuned the existing IndicTrans2 open-source model to enable bidirectional translation between English and these languages. For Khasi (kh) and Mizo (mz), We trained a multilingual model as a baseline using bilingual data from these four language pairs, along with an additional about 8kw English-Bengali bilingual data, all of which share certain linguistic features. This was followed by fine-tuning to achieve bidirectional translation between English and Khasi, as well as English and Mizo. Our transfer learning experiments produced impressive results: 23.5 BLEU for en-as, 31.8 BLEU for en-mn, 36.2 BLEU for as-en, and 47.9 BLEU for mn-en on their respective test sets. Similarly, the multilingual model transfer learning experiments yielded impressive outcomes, achieving 19.7 BLEU for en-kh, 32.8 BLEU for en-mz, 16.1 BLEU for kh-en, and 33.9 BLEU for mz-en on their respective test sets. These results not only highlight the effectiveness of transfer learning techniques for low-resource languages but also contribute to advancing machine translation capabilities for low-resource Indian languages.
Adaptive Global-Local Representation Learning and Selection for Cross-Domain Facial Expression Recognition
Jan 20, 2024Domain shift poses a significant challenge in Cross-Domain Facial Expression Recognition (CD-FER) due to the distribution variation across different domains. Current works mainly focus on learning domain-invariant features through global feature adaptation, while neglecting the transferability of local features. Additionally, these methods lack discriminative supervision during training on target datasets, resulting in deteriorated feature representation in target domain. To address these limitations, we propose an Adaptive Global-Local Representation Learning and Selection (AGLRLS) framework. The framework incorporates global-local adversarial adaptation and semantic-aware pseudo label generation to enhance the learning of domain-invariant and discriminative feature during training. Meanwhile, a global-local prediction consistency learning is introduced to improve classification results during inference. Specifically, the framework consists of separate global-local adversarial learning modules that learn domain-invariant global and local features independently. We also design a semantic-aware pseudo label generation module, which computes semantic labels based on global and local features. Moreover, a novel dynamic threshold strategy is employed to learn the optimal thresholds by leveraging independent prediction of global and local features, ensuring filtering out the unreliable pseudo labels while retaining reliable ones. These labels are utilized for model optimization through the adversarial learning process in an end-to-end manner. During inference, a global-local prediction consistency module is developed to automatically learn an optimal result from multiple predictions. We conduct comprehensive experiments and analysis based on a fair evaluation benchmark. The results demonstrate that the proposed framework outperforms the current competing methods by a substantial margin.
PSP: Million-level Protein Sequence Dataset for Protein Structure Prediction
Jun 24, 2022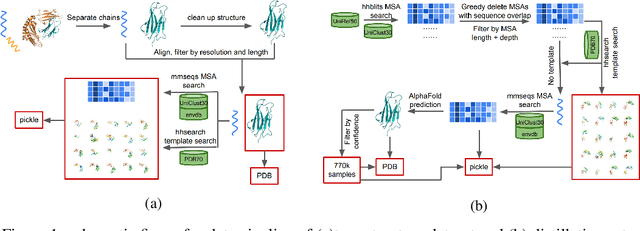
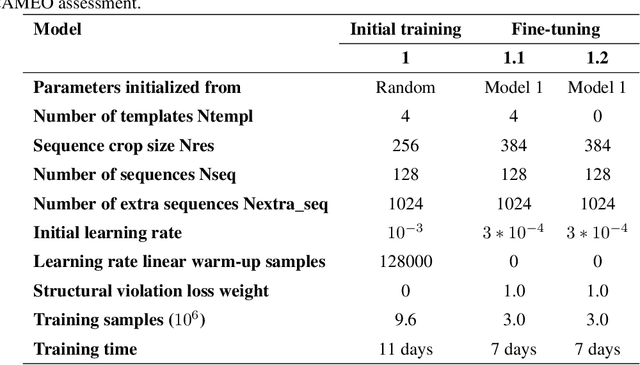
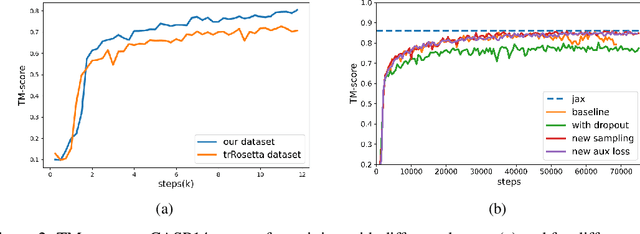
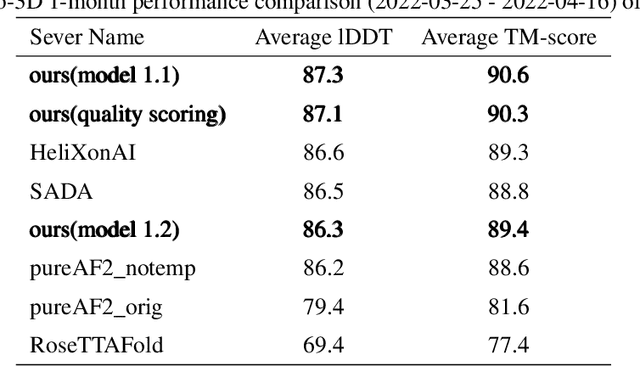
Proteins are essential component of human life and their structures are important for function and mechanism analysis. Recent work has shown the potential of AI-driven methods for protein structure prediction. However, the development of new models is restricted by the lack of dataset and benchmark training procedure. To the best of our knowledge, the existing open source datasets are far less to satisfy the needs of modern protein sequence-structure related research. To solve this problem, we present the first million-level protein structure prediction dataset with high coverage and diversity, named as PSP. This dataset consists of 570k true structure sequences (10TB) and 745k complementary distillation sequences (15TB). We provide in addition the benchmark training procedure for SOTA protein structure prediction model on this dataset. We validate the utility of this dataset for training by participating CAMEO contest in which our model won the first place. We hope our PSP dataset together with the training benchmark can enable a broader community of AI/biology researchers for AI-driven protein related research.
Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents
Feb 05, 2020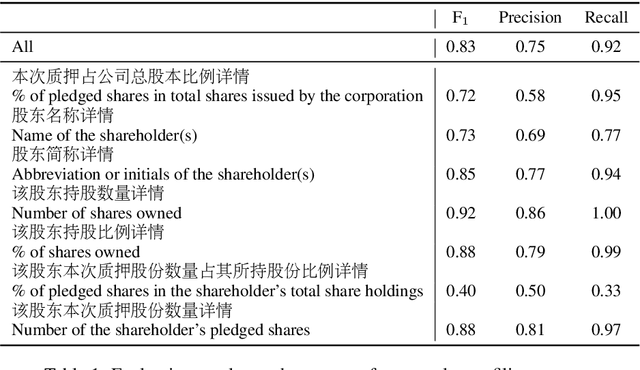
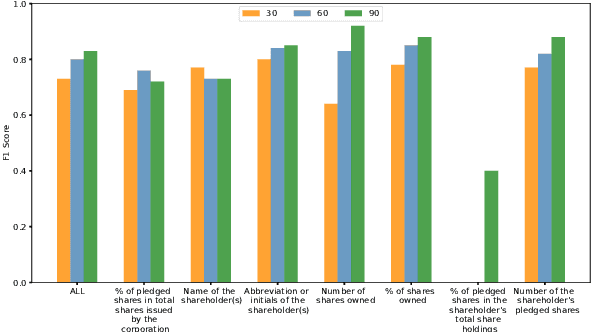
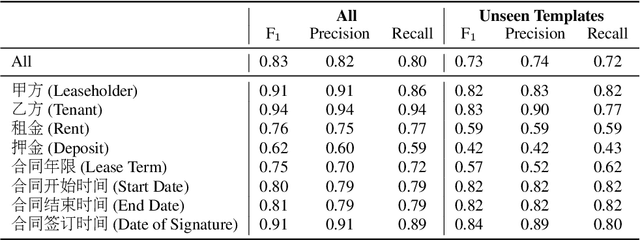
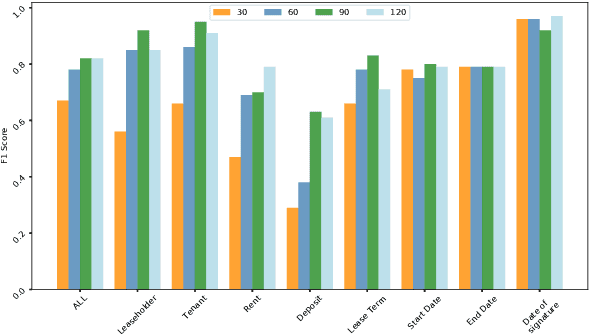
Techniques for automatically extracting important content elements from business documents such as contracts, statements, and filings have the potential to make business operations more efficient. This problem can be formulated as a sequence labeling task, and we demonstrate the adaption of BERT to two types of business documents: regulatory filings and property lease agreements. There are aspects of this problem that make it easier than "standard" information extraction tasks and other aspects that make it more difficult, but on balance we find that modest amounts of annotated data (less than 100 documents) are sufficient to achieve reasonable accuracy. We integrate our models into an end-to-end cloud platform that provides both an easy-to-use annotation interface as well as an inference interface that allows users to upload documents and inspect model outputs.