 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Paraphrase or Not To Paraphrase: User-Controllable Selective Paraphrase Generation
Aug 21, 2020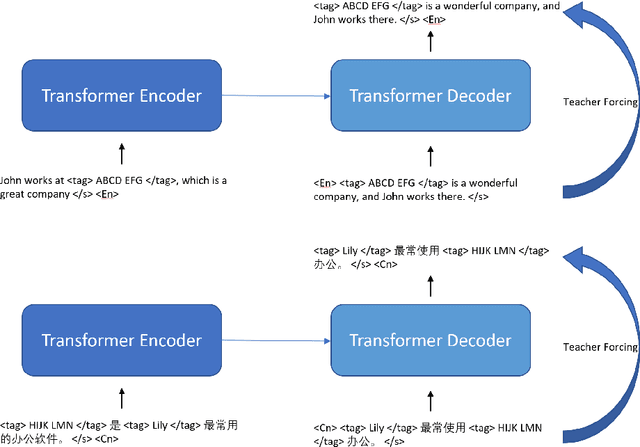
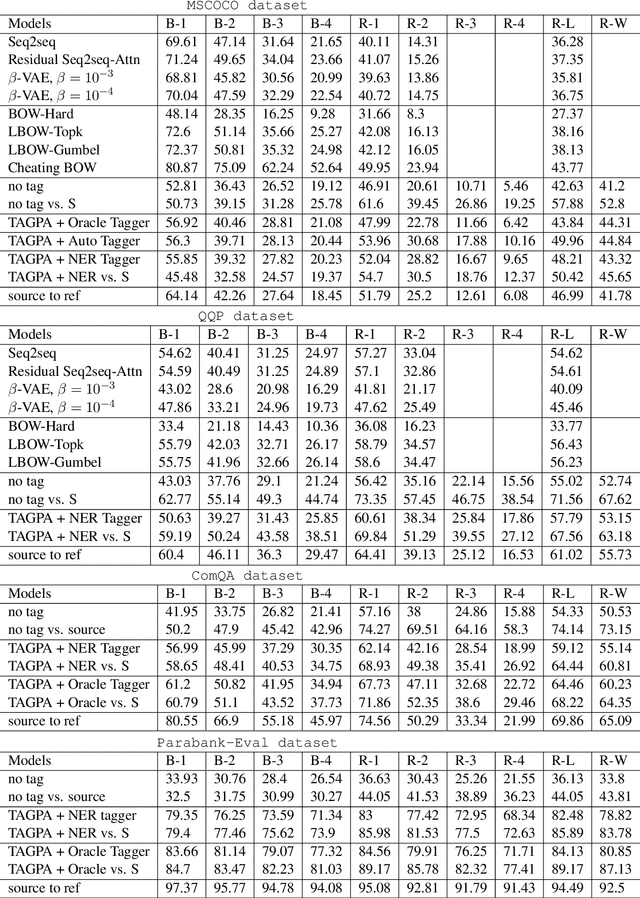
In this article, we propose a paraphrase generation technique to keep the key phrases in source sentences during paraphrasing. We also develop a model called TAGPA with such technique, which has multiple pre-configured or trainable key phrase detector and a paraphrase generator. The paraphrase generator aims to keep the key phrases and increase the diversity of the paraphrased sentences. The key phrases can be entities provided by our user, like company names, people's names, domain-specific terminologies, etc., or can be learned from a given dataset.
SegaBERT: Pre-training of Segment-aware BERT for Language Understanding
Apr 30, 2020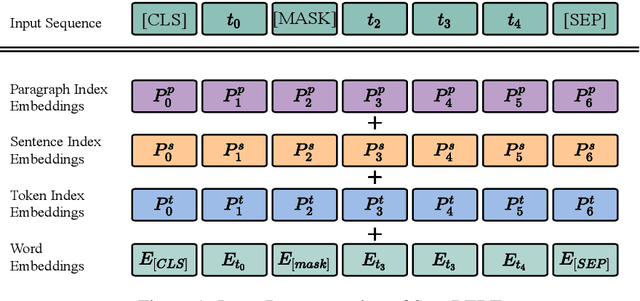
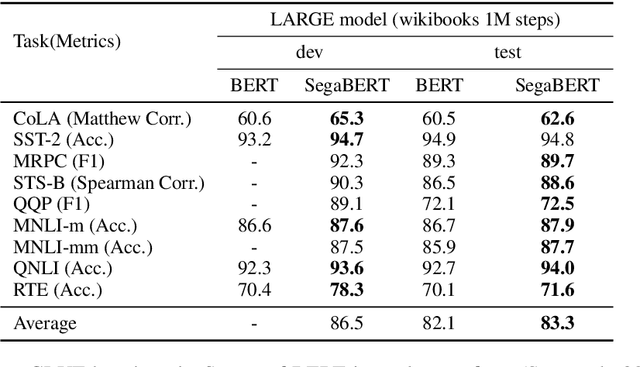
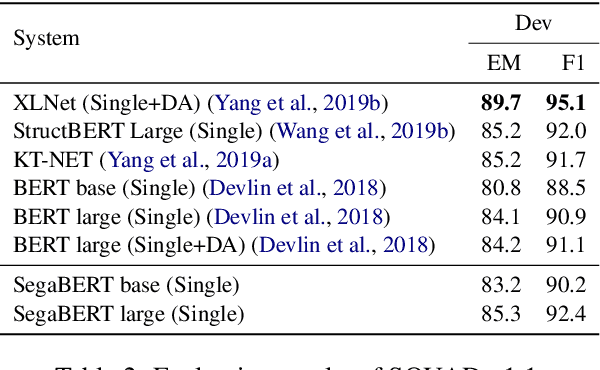
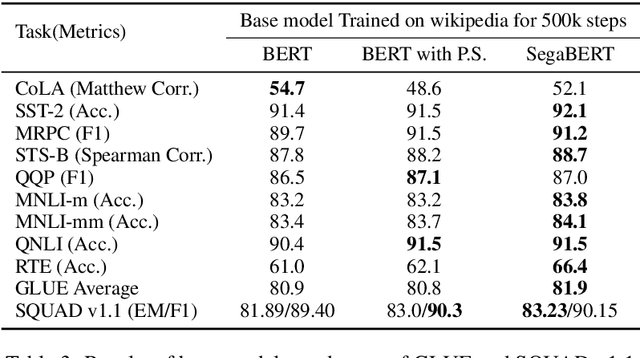
Pre-trained language models have achieved state-of-the-art results in various natural language processing tasks. Most of them are based on the Transformer architecture, which distinguishes tokens with the token position index of the input sequence. However, sentence index and paragraph index are also important to indicate the token position in a document. We hypothesize that better contextual representations can be generated from the text encoder with richer positional information. To verify this, we propose a segment-aware BERT, by replacing the token position embedding of Transformer with a combination of paragraph index, sentence index, and token index embeddings. We pre-trained the SegaBERT on the masked language modeling task in BERT but without any affiliated tasks. Experimental results show that our pre-trained model can outperform the original BERT model on various NLP tasks.
Semantics of the Unwritten
Apr 05, 2020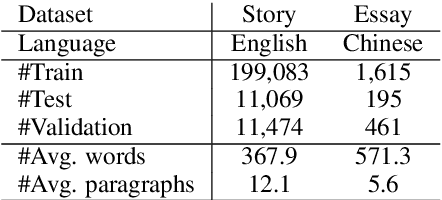
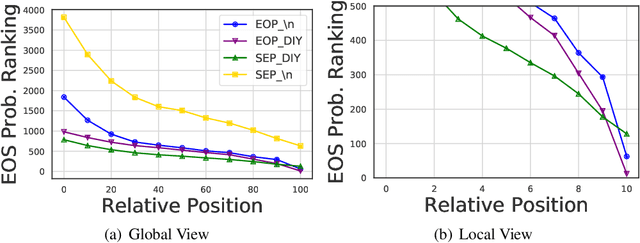
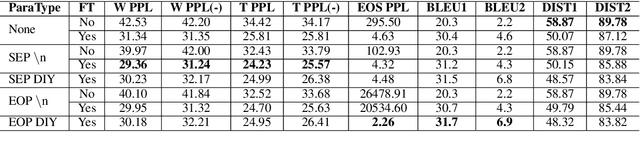

The semantics of a text is manifested not only by what is read, but also by what is not read. In this article, we will study how those implicit "not read" information such as end-of-paragraph (EOP) and end-of-sequence (EOS) affect the quality of text generation. Transformer-based pretrained language models (LMs) have demonstrated the ability to generate long continuations with good quality. This model gives us a platform for the first time to demonstrate that paragraph layouts and text endings are also important components of human writing. Specifically, we find that pretrained LMs can generate better continuations by learning to generate the end of the paragraph (EOP) in the fine-tuning stage. Experimental results on English story generation show that EOP can lead to higher BLEU score and lower EOS perplexity. To further investigate the relationship between text ending and EOP, we conduct experiments with a self-collected Chinese essay dataset on Chinese-GPT2, a character level LM without paragraph breaker or EOS during pre-training. Experimental results show that the Chinese GPT2 can generate better essay endings with paragraph information. Experiments on both English stories and Chinese essays demonstrate that learning to end paragraphs can benefit the continuation generation with pretrained LMs.
Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents
Feb 05, 2020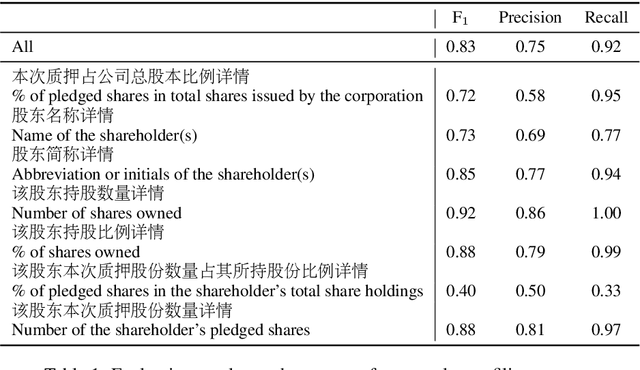
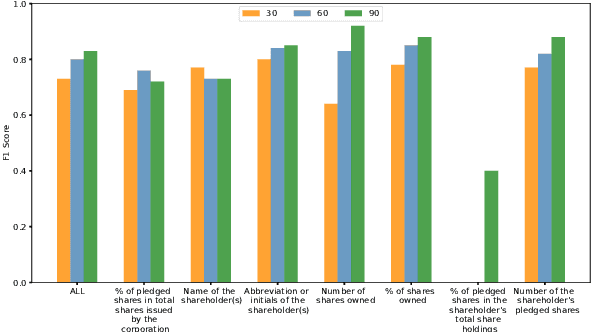
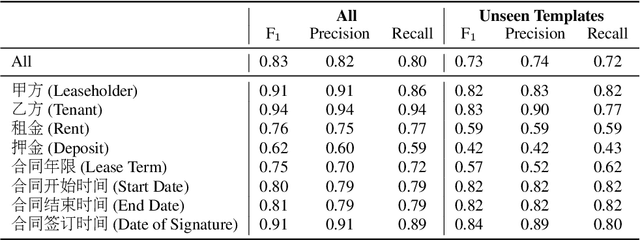
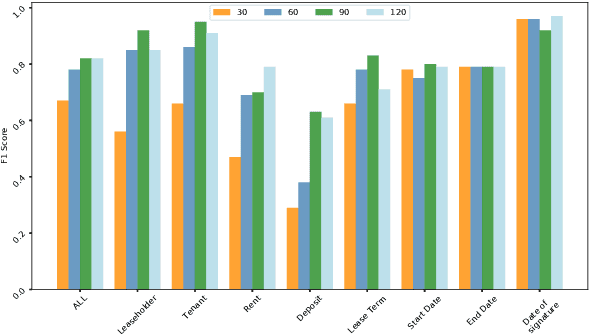
Techniques for automatically extracting important content elements from business documents such as contracts, statements, and filings have the potential to make business operations more efficient. This problem can be formulated as a sequence labeling task, and we demonstrate the adaption of BERT to two types of business documents: regulatory filings and property lease agreements. There are aspects of this problem that make it easier than "standard" information extraction tasks and other aspects that make it more difficult, but on balance we find that modest amounts of annotated data (less than 100 documents) are sufficient to achieve reasonable accuracy. We integrate our models into an end-to-end cloud platform that provides both an easy-to-use annotation interface as well as an inference interface that allows users to upload documents and inspect model outputs.
Data Augmentation for BERT Fine-Tuning in Open-Domain Question Answering
Apr 14, 2019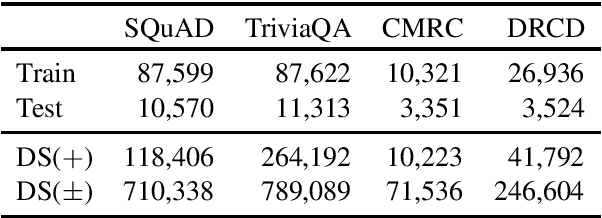
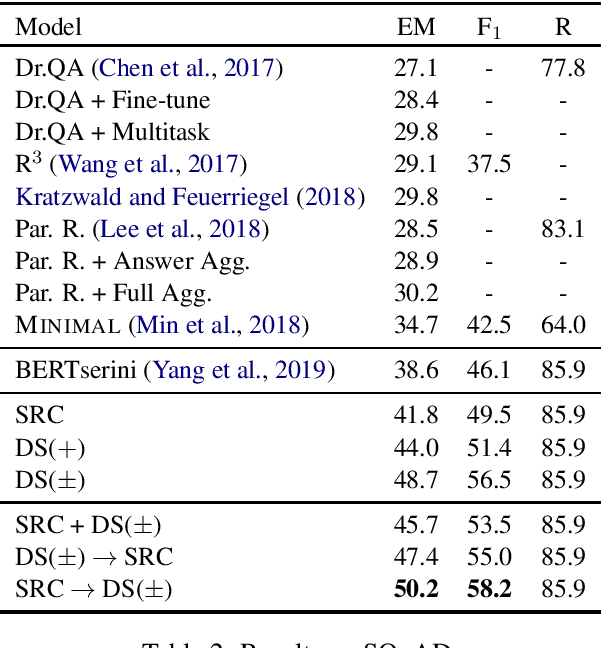
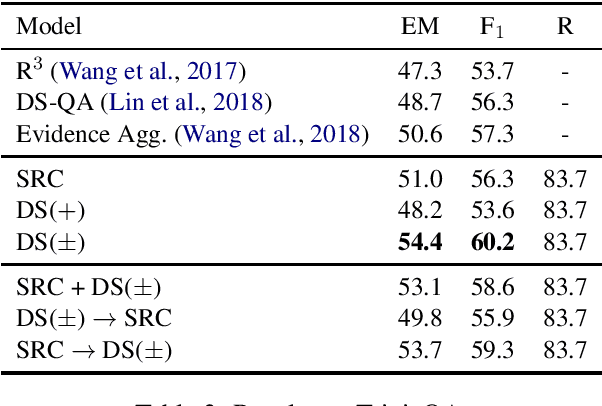
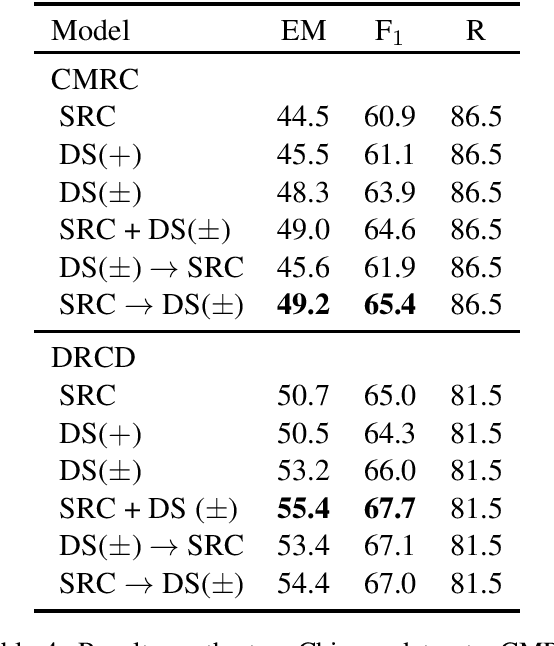
Recently, a simple combination of passage retrieval using off-the-shelf IR techniques and a BERT reader was found to be very effective for question answering directly on Wikipedia, yielding a large improvement over the previous state of the art on a standard benchmark dataset. In this paper, we present a data augmentation technique using distant supervision that exploits positive as well as negative examples. We apply a stage-wise approach to fine tuning BERT on multiple datasets, starting with data that is "furthest" from the test data and ending with the "closest". Experimental results show large gains in effectiveness over previous approaches on English QA datasets, and we establish new baselines on two recent Chinese QA datasets.
End-to-End Open-Domain Question Answering with BERTserini
Feb 05, 2019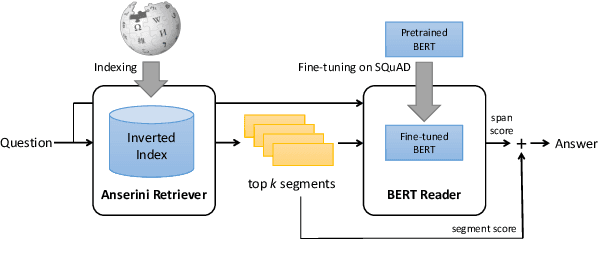
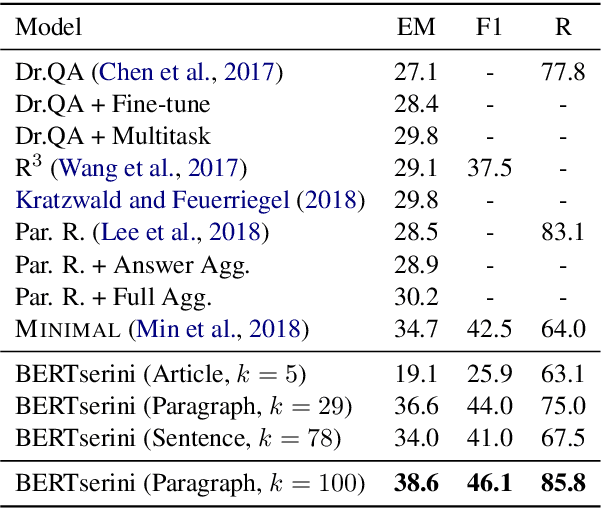
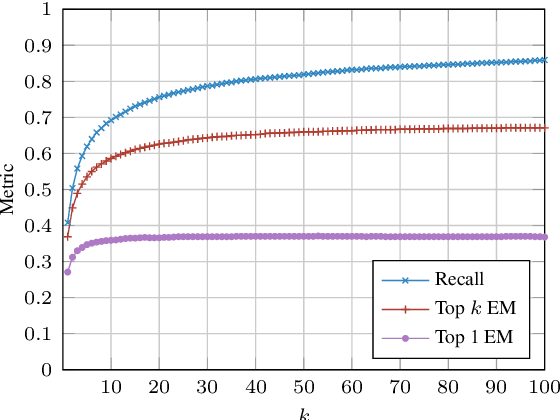
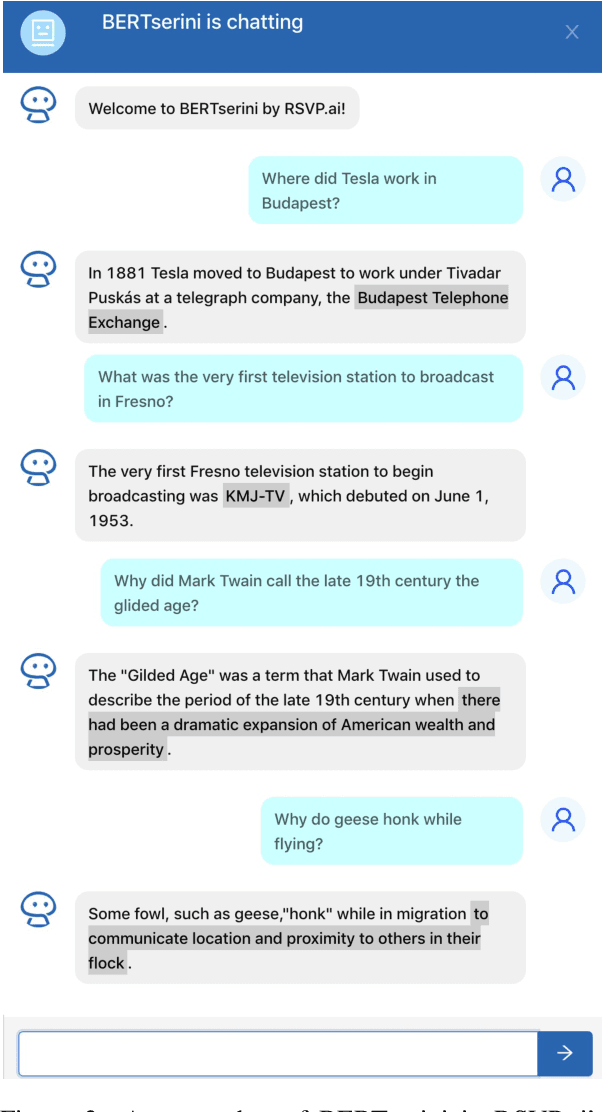
We demonstrate an end-to-end question answering system that integrates BERT with the open-source Anserini information retrieval toolkit. In contrast to most question answering and reading comprehension models today, which operate over small amounts of input text, our system integrates best practices from IR with a BERT-based reader to identify answers from a large corpus of Wikipedia articles in an end-to-end fashion. We report large improvements over previous results on a standard benchmark test collection, showing that fine-tuning pretrained BERT with SQuAD is sufficient to achieve high accuracy in identifying answer spans.