 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter with Experience: Self-Evolving LLM Agents for Evidence-Grounded Health Community Notes
Jun 01, 2026Large Language Model (LLM)-augmented Community Notes offer a scalable path for timely, evidence-grounded correction of health misinformation on social platforms. However, they still reset at every post, leaving useful correction experience from prior cases unused. We introduce EvoNote, an agentic framework that enables health Community Notes generation to self-evolve through an evolving experience memory of prior misinformation correction episodes. Its core is fine-grained credit assignment: EvoNote grounds trajectory-level feedback in health-specific note qualities and distills it into action-level memory for claim analysis, evidence acquisition, and note writing. We evaluate EvoNote on MM-HealthCN, a 1.2K-instance multimodal benchmark of user-flagged health posts with human-written Community Notes and crowd-derived helpfulness labels. Under a human-validated hierarchical utility judge, EvoNote-generated notes are preferred over corresponding human-written notes in 89.6% of cases; on a separate set of Needs More Ratings posts without a crowd helpfulness verdict, EvoNote produces helpful notes for 82.0% of cases. It also reduces the median time needed to produce a candidate correction from over 13 hours in the human-note pipeline to under 2 minutes. Analyses link these gains to stronger evidence use and reusable correction strategies, positioning self-evolving note generation as a promising paradigm for health misinformation governance.
Reasoning Resides in Layers: Restoring Temporal Reasoning in Video-Language Models with Layer-Selective Merging
Apr 13, 2026Multimodal adaptation equips large language models (LLMs) with perceptual capabilities, but often weakens the reasoning ability inherited from language-only pretraining. This trade-off is especially pronounced in video-language models (VLMs), where visual alignment can impair temporal reasoning (TR) over sequential events. We propose MERIT, a training-free, task-driven model merging framework for restoring TR in VLMs. MERIT searches over layer-wise self-attention merging recipes between a VLM and its paired text-only backbone using an objective that improves TR while penalizing degradation in temporal perception (TP). Across three representative VLMs and multiple challenging video benchmarks, MERIT consistently improves TR, preserves or improves TP, and generalizes beyond the search set to four distinct benchmarks. It also outperforms uniform full-model merging and random layer selection, showing that effective recovery depends on selecting the right layers. Interventional masking and frame-level attribution further show that the selected layers are disproportionately important for reasoning and shift model decisions toward temporally and causally relevant evidence. These results show that targeted, perception-aware model merging can effectively restore TR in VLMs without retraining.
InfoAffect: A Dataset for Affective Analysis of Infographics
Nov 09, 2025Infographics are widely used to convey complex information, yet their affective dimensions remain underexplored due to the scarcity of data resources. We introduce a 3.5k-sample affect-annotated InfoAffect dataset, which combines textual content with real-world infographics. We first collect the raw data from six domains and aligned them via preprocessing, the accompanied-text-priority method, and three strategies to guarantee the quality and compliance. After that we construct an affect table and use it to constrain annotation. Five state-of-the-art multimodal large language models (MLLMs) then analyze both modalities, and their outputs are fused with Reciprocal Rank Fusion (RRF) algorithm to yield robust affects and confidences. We conducted a user study with two experiments to validate usability and assess InfoAffect dataset using the Composite Affect Consistency Index (CACI), achieving an overall score of 0.986, which indicates high accuracy.
Personalized Interpolation: An Efficient Method to Tame Flexible Optimization Window Estimation
Jan 23, 2025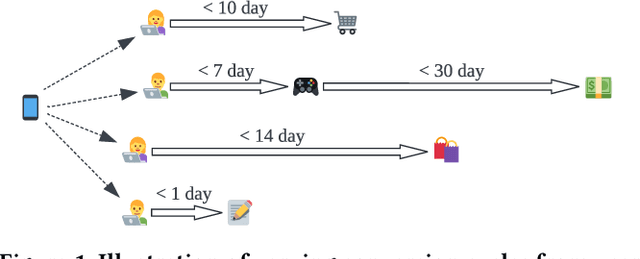
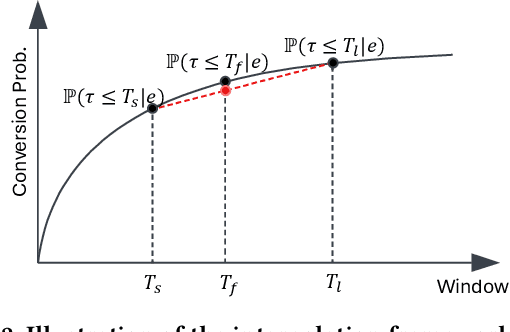
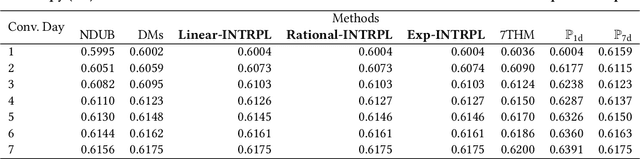
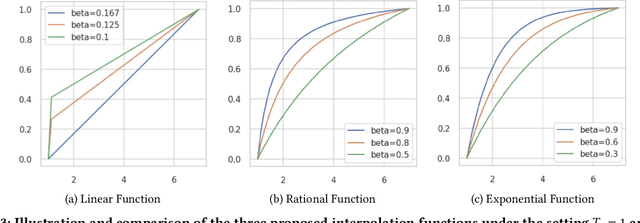
In the realm of online advertising, optimizing conversions is crucial for delivering relevant products to users and enhancing business outcomes. Predicting conversion events is challenging due to variable delays between user interactions, such as impressions or clicks, and the actual conversions. These delays differ significantly across various advertisers and products, necessitating distinct optimization time windows for targeted conversions. To address this, we introduce a novel approach named the \textit{Personalized Interpolation} method, which innovatively builds upon existing fixed conversion window models to estimate flexible conversion windows. This method allows for the accurate estimation of conversions across a variety of delay ranges, thus meeting the diverse needs of advertisers without increasing system complexity. To validate the efficacy of our proposed method, we conducted comprehensive experiments using ads conversion model. Our experiments demonstrate that this method not only achieves high prediction accuracy but also does so more efficiently than other existing solutions. This validation underscores the potential of our Personalized Interpolation method to significantly enhance conversion optimization in real-world online advertising systems, promising improved targeting and effectiveness in advertising strategies.
To Paraphrase or Not To Paraphrase: User-Controllable Selective Paraphrase Generation
Aug 21, 2020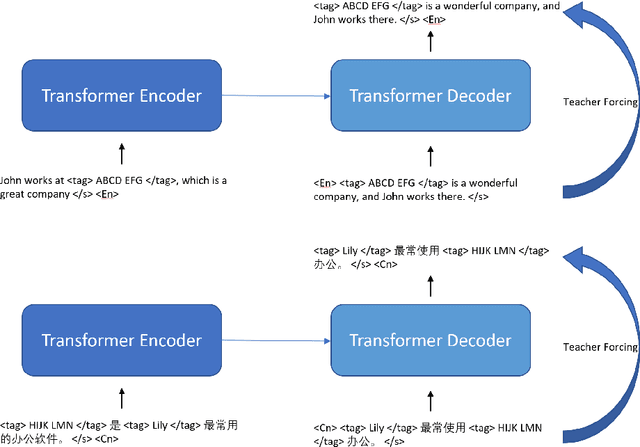
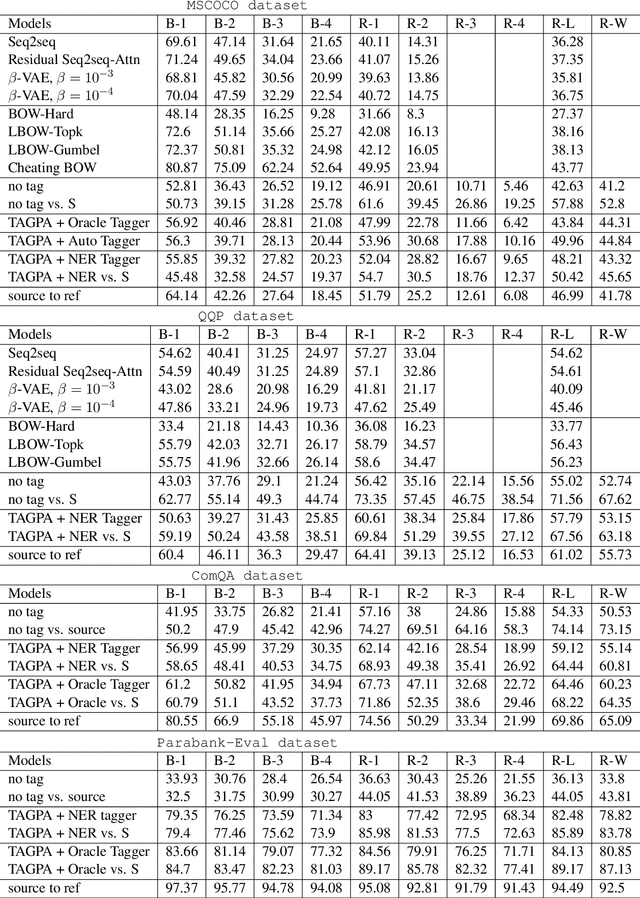
In this article, we propose a paraphrase generation technique to keep the key phrases in source sentences during paraphrasing. We also develop a model called TAGPA with such technique, which has multiple pre-configured or trainable key phrase detector and a paraphrase generator. The paraphrase generator aims to keep the key phrases and increase the diversity of the paraphrased sentences. The key phrases can be entities provided by our user, like company names, people's names, domain-specific terminologies, etc., or can be learned from a given dataset.
Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents
Feb 05, 2020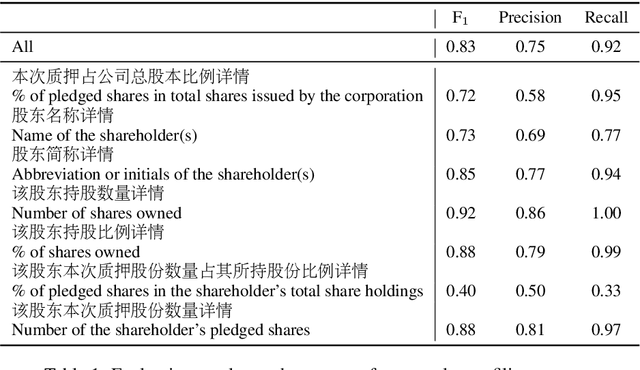
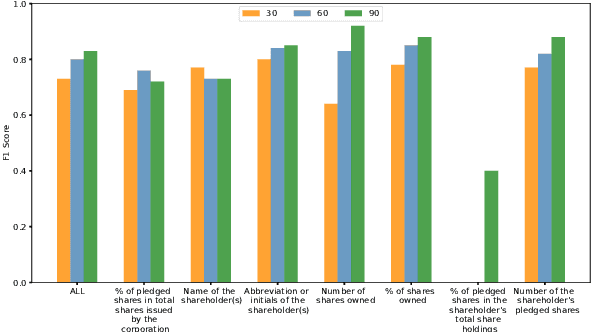
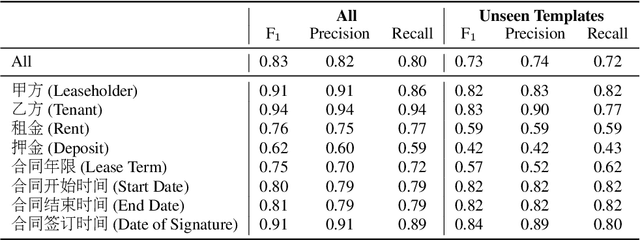
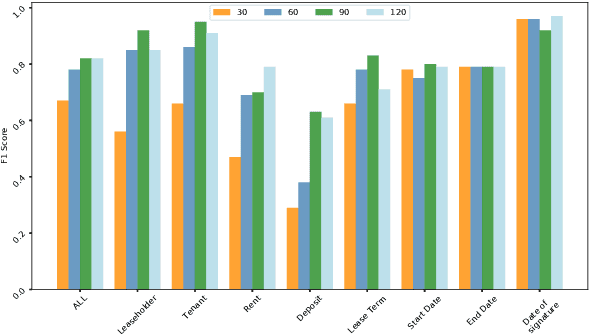
Techniques for automatically extracting important content elements from business documents such as contracts, statements, and filings have the potential to make business operations more efficient. This problem can be formulated as a sequence labeling task, and we demonstrate the adaption of BERT to two types of business documents: regulatory filings and property lease agreements. There are aspects of this problem that make it easier than "standard" information extraction tasks and other aspects that make it more difficult, but on balance we find that modest amounts of annotated data (less than 100 documents) are sufficient to achieve reasonable accuracy. We integrate our models into an end-to-end cloud platform that provides both an easy-to-use annotation interface as well as an inference interface that allows users to upload documents and inspect model outputs.