 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Reward Shaping from Multi-Objective Human Heuristics
Dec 17, 2025Designing effective reward functions remains a central challenge in reinforcement learning, especially in multi-objective environments. In this work, we propose Multi-Objective Reward Shaping with Exploration (MORSE), a general framework that automatically combines multiple human-designed heuristic rewards into a unified reward function. MORSE formulates the shaping process as a bi-level optimization problem: the inner loop trains a policy to maximize the current shaped reward, while the outer loop updates the reward function to optimize task performance. To encourage exploration in the reward space and avoid suboptimal local minima, MORSE introduces stochasticity into the shaping process, injecting noise guided by task performance and the prediction error of a fixed, randomly initialized neural network. Experimental results in MuJoCo and Isaac Sim environments show that MORSE effectively balances multiple objectives across various robotic tasks, achieving task performance comparable to those obtained with manually tuned reward functions.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
Dec 17, 2024Executing precise and agile flight maneuvers is critical for quadrotors in various applications. Traditional quadrotor control approaches are limited by their reliance on flat trajectories or time-consuming optimization, which restricts their flexibility. Recently, RL-based policy has emerged as a promising alternative due to its ability to directly map observations to actions, reducing the need for detailed system knowledge and actuation constraints. However, a significant challenge remains in bridging the sim-to-real gap, where RL-based policies often experience instability when deployed in real world. In this paper, we investigate key factors for learning robust RL-based control policies that are capable of zero-shot deployment in real-world quadrotors. We identify five critical factors and we develop a PPO-based training framework named SimpleFlight, which integrates these five techniques. We validate the efficacy of SimpleFlight on Crazyflie quadrotor, demonstrating that it achieves more than a 50% reduction in trajectory tracking error compared to state-of-the-art RL baselines, and achieves 70% improvement over the traditional MPC. The policy derived by SimpleFlight consistently excels across both smooth polynominal trajectories and challenging infeasible zigzag trajectories on small thrust-to-weight quadrotors. In contrast, baseline methods struggle with high-speed or infeasible trajectories. To support further research and reproducibility, we integrate SimpleFlight into a GPU-based simulator Omnidrones and provide open-source access to the code and model checkpoints. We hope SimpleFlight will offer valuable insights for advancing RL-based quadrotor control. For more details, visit our project website at https://sites.google.com/view/simpleflight/.
Multi-UAV Behavior-based Formation with Static and Dynamic Obstacles Avoidance via Reinforcement Learning
Oct 24, 2024



Formation control of multiple Unmanned Aerial Vehicles (UAVs) is vital for practical applications. This paper tackles the task of behavior-based UAV formation while avoiding static and dynamic obstacles during directed flight. We present a two-stage reinforcement learning (RL) training pipeline to tackle the challenge of multi-objective optimization, large exploration spaces, and the sim-to-real gap. The first stage searches in a simplified scenario for a linear utility function that balances all task objectives simultaneously, whereas the second stage applies the utility function in complex scenarios, utilizing curriculum learning to navigate large exploration spaces. Additionally, we apply an attention-based observation encoder to enhance formation maintenance and manage varying obstacle quantity. Experiments in simulation and real world demonstrate that our method outperforms planning-based and RL-based baselines regarding collision-free rate and formation maintenance in scenarios with static, dynamic, and mixed obstacles.
LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination
Jan 09, 2024



AI agents powered by Large Language Models (LLMs) have made significant advances, enabling them to assist humans in diverse complex tasks and leading to a revolution in human-AI coordination. LLM-powered agents typically require invoking LLM APIs and employing artificially designed complex prompts, which results in high inference latency. While this paradigm works well in scenarios with minimal interactive demands, such as code generation, it is unsuitable for highly interactive and real-time applications, such as gaming. Traditional gaming AI often employs small models or reactive policies, enabling fast inference but offering limited task completion and interaction abilities. In this work, we consider Overcooked as our testbed where players could communicate with natural language and cooperate to serve orders. We propose a Hierarchical Language Agent (HLA) for human-AI coordination that provides both strong reasoning abilities while keeping real-time execution. In particular, HLA adopts a hierarchical framework and comprises three modules: a proficient LLM, referred to as Slow Mind, for intention reasoning and language interaction, a lightweight LLM, referred to as Fast Mind, for generating macro actions, and a reactive policy, referred to as Executor, for transforming macro actions into atomic actions. Human studies show that HLA outperforms other baseline agents, including slow-mind-only agents and fast-mind-only agents, with stronger cooperation abilities, faster responses, and more consistent language communications.
Approximating Human-Like Few-shot Learning with GPT-based Compression
Aug 14, 2023In this work, we conceptualize the learning process as information compression. We seek to equip generative pre-trained models with human-like learning capabilities that enable data compression during inference. We present a novel approach that utilizes the Generative Pre-trained Transformer (GPT) to approximate Kolmogorov complexity, with the aim of estimating the optimal Information Distance for few-shot learning. We first propose using GPT as a prior for lossless text compression, achieving a noteworthy compression ratio. Experiment with LLAMA2-7B backbone achieves a compression ratio of 15.5 on enwik9. We justify the pre-training objective of GPT models by demonstrating its equivalence to the compression length, and, consequently, its ability to approximate the information distance for texts. Leveraging the approximated information distance, our method allows the direct application of GPT models in quantitative text similarity measurements. Experiment results show that our method overall achieves superior performance compared to embedding and prompt baselines on challenging NLP tasks, including semantic similarity, zero and one-shot text classification, and zero-shot text ranking.
Gate Recurrent Unit Network based on Hilbert-Schmidt Independence Criterion for State-of-Health Estimation
Mar 16, 2023State-of-health (SOH) estimation is a key step in ensuring the safe and reliable operation of batteries. Due to issues such as varying data distribution and sequence length in different cycles, most existing methods require health feature extraction technique, which can be time-consuming and labor-intensive. GRU can well solve this problem due to the simple structure and superior performance, receiving widespread attentions. However, redundant information still exists within the network and impacts the accuracy of SOH estimation. To address this issue, a new GRU network based on Hilbert-Schmidt Independence Criterion (GRU-HSIC) is proposed. First, a zero masking network is used to transform all battery data measured with varying lengths every cycle into sequences of the same length, while still retaining information about the original data size in each cycle. Second, the Hilbert-Schmidt Independence Criterion (HSIC) bottleneck, which evolved from Information Bottleneck (IB) theory, is extended to GRU to compress the information from hidden layers. To evaluate the proposed method, we conducted experiments on datasets from the Center for Advanced Life Cycle Engineering (CALCE) of the University of Maryland and NASA Ames Prognostics Center of Excellence. Experimental results demonstrate that our model achieves higher accuracy than other recurrent models.
Improving Prediction Backward-Compatiblility in NLP Model Upgrade with Gated Fusion
Feb 04, 2023



When upgrading neural models to a newer version, new errors that were not encountered in the legacy version can be introduced, known as regression errors. This inconsistent behavior during model upgrade often outweighs the benefits of accuracy gain and hinders the adoption of new models. To mitigate regression errors from model upgrade, distillation and ensemble have proven to be viable solutions without significant compromise in performance. Despite the progress, these approaches attained an incremental reduction in regression which is still far from achieving backward-compatible model upgrade. In this work, we propose a novel method, Gated Fusion, that promotes backward compatibility via learning to mix predictions between old and new models. Empirical results on two distinct model upgrade scenarios show that our method reduces the number of regression errors by 62% on average, outperforming the strongest baseline by an average of 25%.
An Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022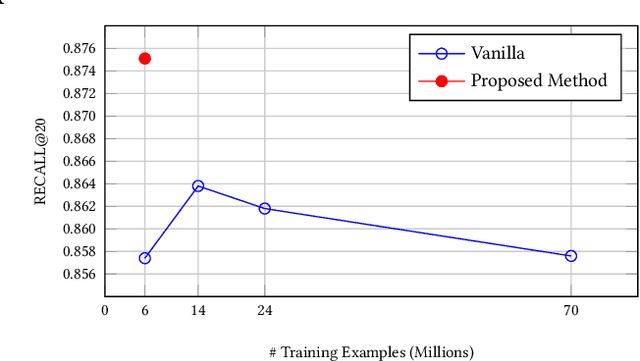

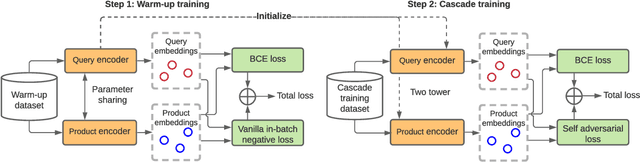
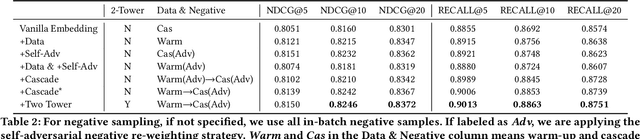
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.
Regression Bugs Are In Your Model! Measuring, Reducing and Analyzing Regressions In NLP Model Updates
May 07, 2021
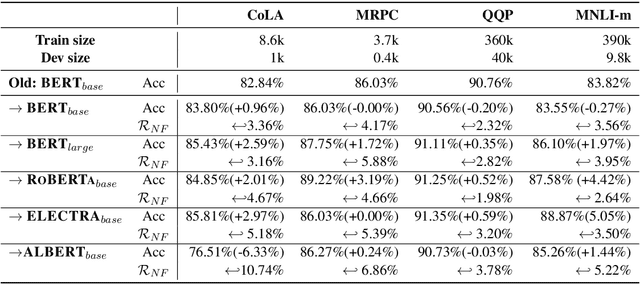
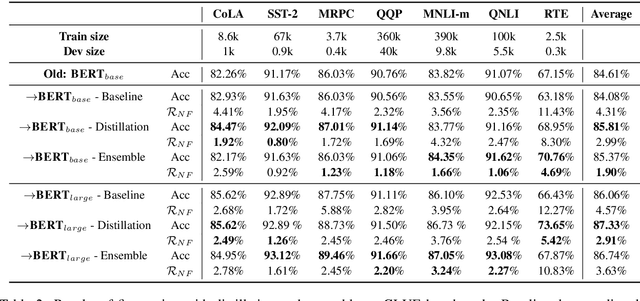
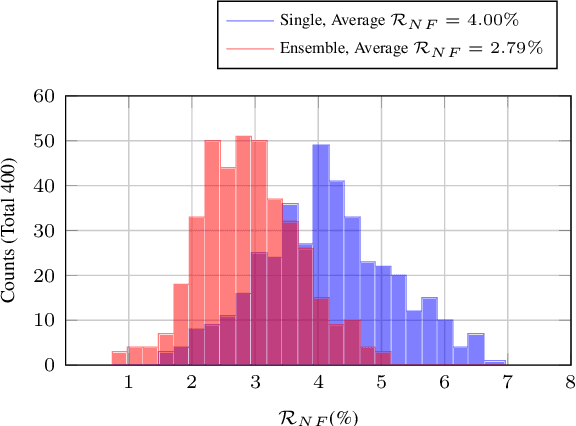
Behavior of deep neural networks can be inconsistent between different versions. Regressions during model update are a common cause of concern that often over-weigh the benefits in accuracy or efficiency gain. This work focuses on quantifying, reducing and analyzing regression errors in the NLP model updates. Using negative flip rate as regression measure, we show that regression has a prevalent presence across tasks in the GLUE benchmark. We formulate the regression-free model updates into a constrained optimization problem, and further reduce it into a relaxed form which can be approximately optimized through knowledge distillation training method. We empirically analyze how model ensemble reduces regression. Finally, we conduct CheckList behavioral testing to understand the distribution of regressions across linguistic phenomena, and the efficacy of ensemble and distillation methods.