 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022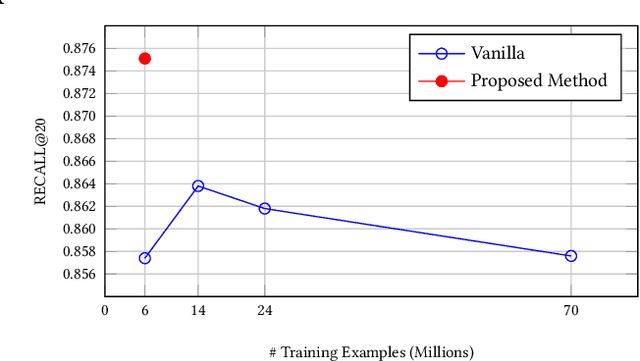

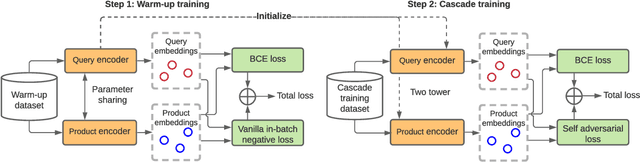
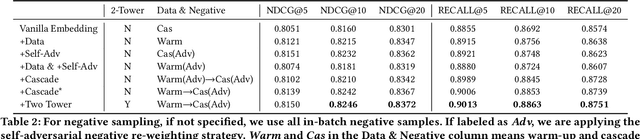
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.