 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence in Large Language Model Evaluation: A Bayesian Approach to Limited-Sample Challenges
Apr 30, 2025


Large language models (LLMs) exhibit probabilistic output characteristics, yet conventional evaluation frameworks rely on deterministic scalar metrics. This study introduces a Bayesian approach for LLM capability assessment that integrates prior knowledge through probabilistic inference, addressing limitations under limited-sample regimes. By treating model capabilities as latent variables and leveraging a curated query set to induce discriminative responses, we formalize model ranking as a Bayesian hypothesis testing problem over mutually exclusive capability intervals. Experimental evaluations with GPT-series models demonstrate that the proposed method achieves superior discrimination compared to conventional evaluation methods. Results indicate that even with reduced sample sizes, the approach maintains statistical robustness while providing actionable insights, such as probabilistic statements about a model's likelihood of surpassing specific baselines. This work advances LLM evaluation methodologies by bridging Bayesian inference with practical constraints in real-world deployment scenarios.
RTLRepoCoder: Repository-Level RTL Code Completion through the Combination of Fine-Tuning and Retrieval Augmentation
Apr 11, 2025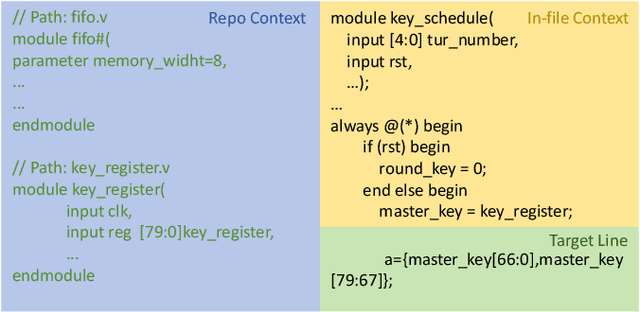
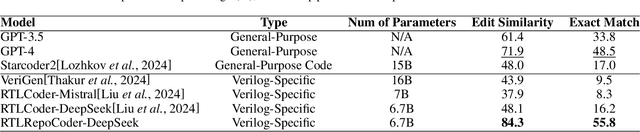
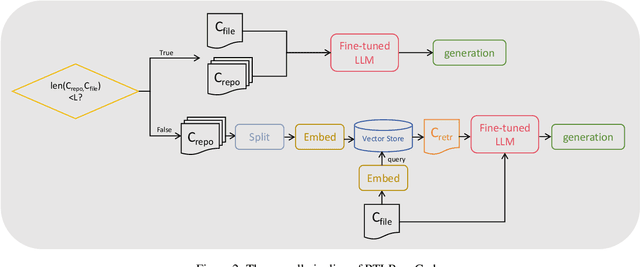

As an essential part of modern hardware design, manually writing Register Transfer Level (RTL) code such as Verilog is often labor-intensive. Following the tremendous success of large language models (LLMs), researchers have begun to explore utilizing LLMs for generating RTL code. However, current studies primarily focus on generating simple single modules, which can not meet the demands in real world. In fact, due to challenges in managing long-context RTL code and complex cross-file dependencies, existing solutions cannot handle large-scale Verilog repositories in practical hardware development. As the first endeavor to exclusively adapt LLMs for large-scale RTL development, we propose RTLRepoCoder, a groundbreaking solution that incorporates specific fine-tuning and Retrieval-Augmented Generation (RAG) for repository-level Verilog code completion. Open-source Verilog repositories from the real world, along with an extended context size, are used for domain-specific fine-tuning. The optimized RAG system improves the information density of the input context by retrieving relevant code snippets. Tailored optimizations for RAG are carried out, including the embedding model, the cross-file context splitting strategy, and the chunk size. Our solution achieves state-of-the-art performance on public benchmark, significantly surpassing GPT-4 and advanced domain-specific LLMs on Edit Similarity and Exact Match rate. Comprehensive experiments demonstrate the remarkable effectiveness of our approach and offer insights for future work.
IDGen: Item Discrimination Induced Prompt Generation for LLM Evaluation
Sep 27, 2024



As Large Language Models (LLMs) grow increasingly adept at managing complex tasks, the evaluation set must keep pace with these advancements to ensure it remains sufficiently discriminative. Item Discrimination (ID) theory, which is widely used in educational assessment, measures the ability of individual test items to differentiate between high and low performers. Inspired by this theory, we propose an ID-induced prompt synthesis framework for evaluating LLMs to ensure the evaluation set can continually update and refine according to model abilities. Our data synthesis framework prioritizes both breadth and specificity. It can generate prompts that comprehensively evaluate the capabilities of LLMs while revealing meaningful performance differences between models, allowing for effective discrimination of their relative strengths and weaknesses across various tasks and domains. To produce high-quality data, we incorporate a self-correct mechanism into our generalization framework, and develop two models to predict prompt discrimination and difficulty score to facilitate our data synthesis framework, contributing valuable tools to evaluation data synthesis research. We apply our generated data to evaluate five SOTA models. Our data achieves an average score of 51.92, accompanied by a variance of 10.06. By contrast, previous works (i.e., SELF-INSTRUCT and WizardLM) obtain an average score exceeding 67, with a variance below 3.2. The results demonstrate that the data generated by our framework is more challenging and discriminative compared to previous works. We will release a dataset of over 3,000 carefully crafted prompts to facilitate evaluation research of LLMs.
STEMO: Early Spatio-temporal Forecasting with Multi-Objective Reinforcement Learning
Jun 18, 2024Accuracy and timeliness are indeed often conflicting goals in prediction tasks. Premature predictions may yield a higher rate of false alarms, whereas delaying predictions to gather more information can render them too late to be useful. In applications such as wildfires, crimes, and traffic jams, timely forecasting are vital for safeguarding human life and property. Consequently, finding a balance between accuracy and timeliness is crucial. In this paper, we propose an early spatio-temporal forecasting model based on Multi-Objective reinforcement learning that can either implement an optimal policy given a preference or infer the preference based on a small number of samples. The model addresses two primary challenges: 1) enhancing the accuracy of early forecasting and 2) providing the optimal policy for determining the most suitable prediction time for each area. Our method demonstrates superior performance on three large-scale real-world datasets, surpassing existing methods in early spatio-temporal forecasting tasks.
Augmenting Biomedical Named Entity Recognition with General-domain Resources
Jun 15, 2024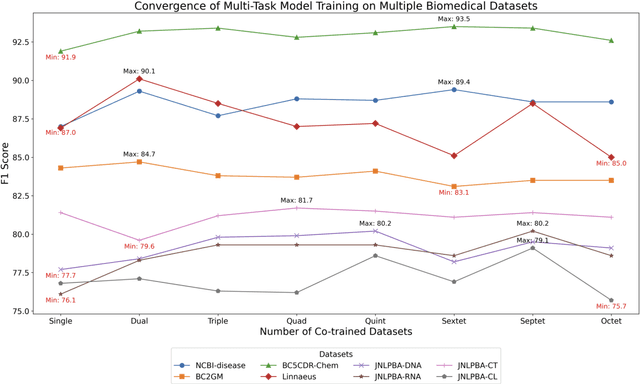

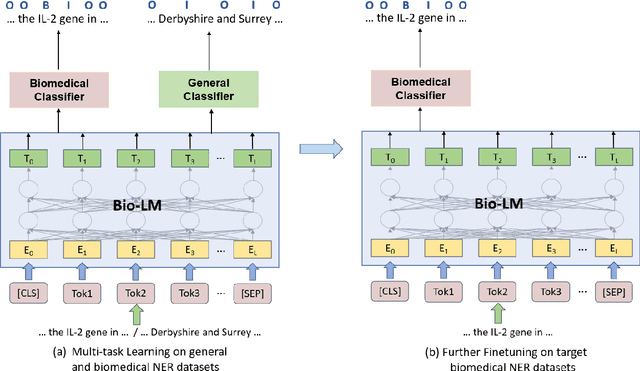
Training a neural network-based biomedical named entity recognition (BioNER) model usually requires extensive and costly human annotations. While several studies have employed multi-task learning with multiple BioNER datasets to reduce human effort, this approach does not consistently yield performance improvements and may introduce label ambiguity in different biomedical corpora. We aim to tackle those challenges through transfer learning from easily accessible resources with fewer concept overlaps with biomedical datasets. In this paper, we proposed GERBERA, a simple-yet-effective method that utilized a general-domain NER dataset for training. Specifically, we performed multi-task learning to train a pre-trained biomedical language model with both the target BioNER dataset and the general-domain dataset. Subsequently, we fine-tuned the models specifically for the BioNER dataset. We systematically evaluated GERBERA on five datasets of eight entity types, collectively consisting of 81,410 instances. Despite using fewer biomedical resources, our models demonstrated superior performance compared to baseline models trained with multiple additional BioNER datasets. Specifically, our models consistently outperformed the baselines in six out of eight entity types, achieving an average improvement of 0.9% over the best baseline performance across eight biomedical entity types sourced from five different corpora. Our method was especially effective in amplifying performance on BioNER datasets characterized by limited data, with a 4.7% improvement in F1 scores on the JNLPBA-RNA dataset.
Spatio-temporal Early Prediction based on Multi-objective Reinforcement Learning
Jun 06, 2024Accuracy and timeliness are indeed often conflicting goals in prediction tasks. Premature predictions may yield a higher rate of false alarms, whereas delaying predictions to gather more information can render them too late to be useful. In applications such as wildfires, crimes, and traffic jams, timely predictions are vital for safeguarding human life and property. Consequently, finding a balance between accuracy and timeliness is crucial. In this paper, we propose a spatio-temporal early prediction model based on Multi-Objective reinforcement learning that can either implement an optimal policy given a preference or infer the preference based on a small number of samples. The model addresses two primary challenges: 1) enhancing the accuracy of early predictions and 2) providing the optimal policy for determining the most suitable prediction time for each area. Our method demonstrates superior performance on three large-scale real-world datasets, surpassing existing methods in early spatio-temporal prediction tasks.
Non-destructive Degradation Pattern Decoupling for Ultra-early Battery Prototype Verification Using Physics-informed Machine Learning
Jun 01, 2024



Manufacturing complexities and uncertainties have impeded the transition from material prototypes to commercial batteries, making prototype verification critical to quality assessment. A fundamental challenge involves deciphering intertwined chemical processes to characterize degradation patterns and their quantitative relationship with battery performance. Here we show that a physics-informed machine learning approach can quantify and visualize temporally resolved losses concerning thermodynamics and kinetics only using electric signals. Our method enables non-destructive degradation pattern characterization, expediting temperature-adaptable predictions of entire lifetime trajectories, rather than end-of-life points. The verification speed is 25 times faster yet maintaining 95.1% accuracy across temperatures. Such advances facilitate more sustainable management of defective prototypes before massive production, establishing a 19.76 billion USD scrap material recycling market by 2060 in China. By incorporating stepwise charge acceptance as a measure of the initial manufacturing variability of normally identical batteries, we can immediately identify long-term degradation variations. We attribute the predictive power to interpreting machine learning insights using material-agnostic featurization taxonomy for degradation pattern decoupling. Our findings offer new possibilities for dynamic system analysis, such as battery prototype degradation, demonstrating that complex pattern evolutions can be accurately predicted in a non-destructive and data-driven fashion by integrating physics-informed machine learning.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
Android in the Zoo: Chain-of-Action-Thought for GUI Agents
Mar 05, 2024



Large language model (LLM) leads to a surge of autonomous GUI agents for smartphone, which completes a task triggered by natural language through predicting a sequence of actions of API. Even though the task highly relies on past actions and visual observations, existing studies typical consider little semantic information carried out by intermediate screenshots and screen operations. To address this, this work presents Chain-of-Action-Thought (dubbed CoAT), which takes the description of the previous actions, the current screen, and more importantly the action thinking of what actions should be performed and the outcomes led by the chosen action. We demonstrate that, in a zero-shot setting upon an off-the-shell LLM, CoAT significantly improves the goal progress compared to standard context modeling. To further facilitate the research in this line, we construct a benchmark Android-In-The-Zoo (AitZ), which contains 18,643 screen-action pairs together with chain-of-action-thought annotations. Experiments show that fine-tuning a 200M model on our AitZ dataset achieves on par performance with CogAgent-Chat-18B.
Point-Wise Vibration Pattern Production via a Sparse Actuator Array for Surface Tactile Feedback
Feb 18, 2024
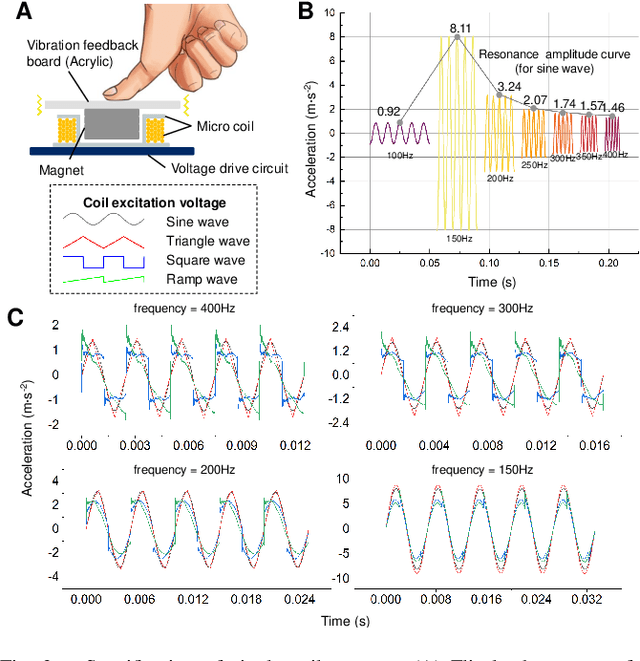


Surface vibration tactile feedback is capable of conveying various semantic information to humans via the handheld electronic devices, like smartphone, touch panel,and game controller. However, covering the whole device contacting surface with dense actuator arrangement can affect its normal use, how to produce desired vibration patterns at any contact point with only several sparse actuators deployed on the handled device surface remains a significant challenge. In this work, we develop a tactile feedback board with only five actuators in the size of a smartphone, and achieve the precise vibration pattern production that can focus at any desired position all over the board. Specifically, we investigate the vibration characteristics of single passive coil actuator, and construct its vibration pattern model at any position on the feedback board surface. Optimal phase and amplitude modulation, found with the simulated annealing algorithm, is employed with five actuators in a sparse array. And all actuators' vibration patterns are superimposed linearly to synthetically generate different onboard vibration energy distribution for tactile sensing. Experiments demonstrated that for point-wise vibration pattern production on our tactile board achieved an average level of about 0.9 in the Structural Similarity Index Measure (SSIM) evaluation, when compared to the ideal single-point-focused target vibration pattern. The sparse actuator array can be easily embedded into usual handheld electronic devices, which shows a good significant implication for enriching their haptic interaction functionalities.