 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mamba: Enhancing State-space Models with Deformable Dilated Convolutions for Multi-scale Traffic Object Detection
Apr 09, 2026In a real-world traffic scenario, varying-scale objects are usually distributed in a cluttered background, which poses great challenges to accurate detection. Although current Mamba-based methods can efficiently model long-range dependencies, they still struggle to capture small objects with abundant local details, which hinders joint modeling of local structures and global semantics. Moreover, state-space models exhibit limited hierarchical feature representation and weak cross-scale interaction due to flat sequential modeling and insufficient spatial inductive biases, leading to sub-optimal performance in complex scenes. To address these issues, we propose a Mamba with Deformable Dilated Convolutions Network (MDDCNet) for accurate traffic object detection in this study. In MDDCNet, a well-designed hybrid backbone with successive Multi-Scale Deformable Dilated Convolution (MSDDC) blocks and Mamba blocks enables hierarchical feature representation from local details to global semantics. Meanwhile, a Channel-Enhanced Feed-Forward Network (CE-FFN) is further devised to overcome the limited channel interaction capability of conventional feed-forward networks, whilst a Mamba-based Attention-Aggregating Feature Pyramid Network (A^2FPN) is constructed to achieve enhanced multi-scale feature fusion and interaction. Extensive experimental results on public benchmark and real-world datasets demonstrate the superiority of our method over various advanced detectors. The code is available at https://github.com/Bettermea/MDDCNet.
Biased-Attention Guided Risk Prediction for Safe Decision-Making at Unsignalized Intersections
Oct 14, 2025



Autonomous driving decision-making at unsignalized intersections is highly challenging due to complex dynamic interactions and high conflict risks. To achieve proactive safety control, this paper proposes a deep reinforcement learning (DRL) decision-making framework integrated with a biased attention mechanism. The framework is built upon the Soft Actor-Critic (SAC) algorithm. Its core innovation lies in the use of biased attention to construct a traffic risk predictor. This predictor assesses the long-term risk of collision for a vehicle entering the intersection and transforms this risk into a dense reward signal to guide the SAC agent in making safe and efficient driving decisions. Finally, the simulation results demonstrate that the proposed method effectively improves both traffic efficiency and vehicle safety at the intersection, thereby proving the effectiveness of the intelligent decision-making framework in complex scenarios. The code of our work is available at https://github.com/hank111525/SAC-RWB.
RTLRepoCoder: Repository-Level RTL Code Completion through the Combination of Fine-Tuning and Retrieval Augmentation
Apr 11, 2025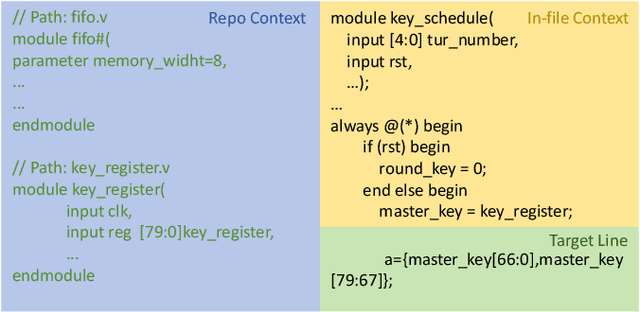
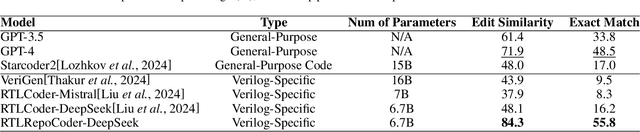
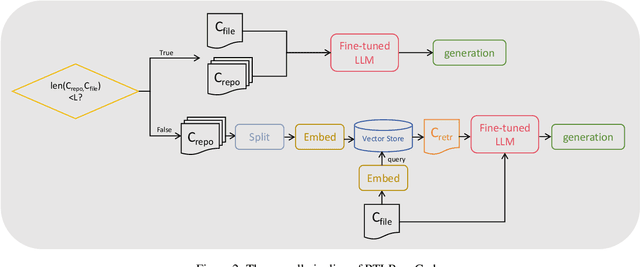

As an essential part of modern hardware design, manually writing Register Transfer Level (RTL) code such as Verilog is often labor-intensive. Following the tremendous success of large language models (LLMs), researchers have begun to explore utilizing LLMs for generating RTL code. However, current studies primarily focus on generating simple single modules, which can not meet the demands in real world. In fact, due to challenges in managing long-context RTL code and complex cross-file dependencies, existing solutions cannot handle large-scale Verilog repositories in practical hardware development. As the first endeavor to exclusively adapt LLMs for large-scale RTL development, we propose RTLRepoCoder, a groundbreaking solution that incorporates specific fine-tuning and Retrieval-Augmented Generation (RAG) for repository-level Verilog code completion. Open-source Verilog repositories from the real world, along with an extended context size, are used for domain-specific fine-tuning. The optimized RAG system improves the information density of the input context by retrieving relevant code snippets. Tailored optimizations for RAG are carried out, including the embedding model, the cross-file context splitting strategy, and the chunk size. Our solution achieves state-of-the-art performance on public benchmark, significantly surpassing GPT-4 and advanced domain-specific LLMs on Edit Similarity and Exact Match rate. Comprehensive experiments demonstrate the remarkable effectiveness of our approach and offer insights for future work.
Dynamic Distribution of Edge Intelligence at the Node Level for Internet of Things
Jul 13, 2021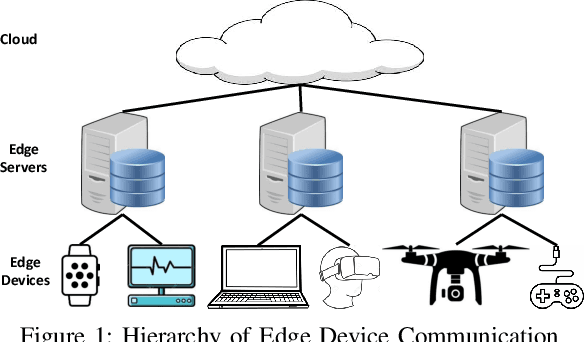
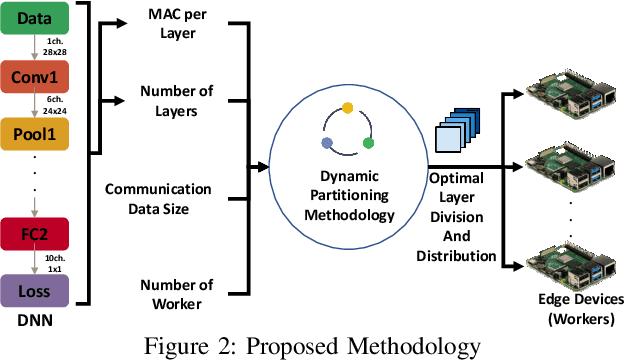
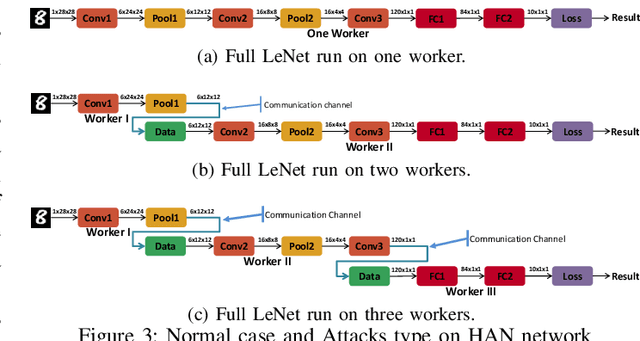
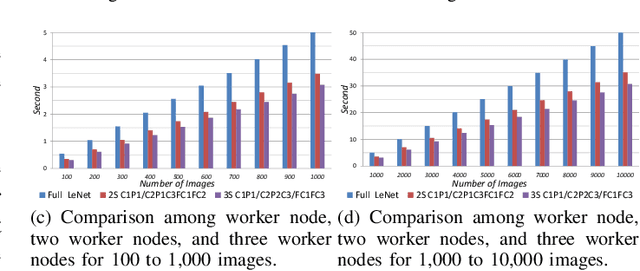
In this paper, dynamic deployment of Convolutional Neural Network (CNN) architecture is proposed utilizing only IoT-level devices. By partitioning and pipelining the CNN, it horizontally distributes the computation load among resource-constrained devices (called horizontal collaboration), which in turn increases the throughput. Through partitioning, we can decrease the computation and energy consumption on individual IoT devices and increase the throughput without sacrificing accuracy. Also, by processing the data at the generation point, data privacy can be achieved. The results show that throughput can be increased by 1.55x to 1.75x for sharing the CNN into two and three resource-constrained devices, respectively.
Video Face Recognition System: RetinaFace-mnet-faster and Secondary Search
Sep 29, 2020

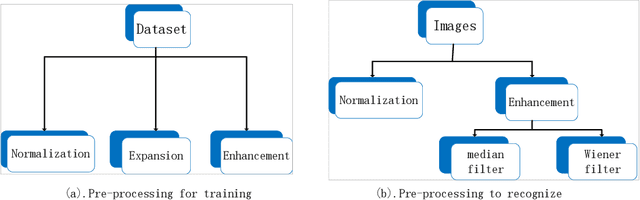

Face recognition is widely used in the scene. However, different visual environments require different methods, and face recognition has a difficulty in complex environments. Therefore, this paper mainly experiments complex faces in the video. First, we design an image pre-processing module for fuzzy scene or under-exposed faces to enhance images. Our experimental results demonstrate that effective images pre-processing improves the accuracy of 0.11%, 0.2% and 1.4% on LFW, WIDER FACE and our datasets, respectively. Second, we propose RetinacFace-mnet-faster for detection and a confidence threshold specification for face recognition, reducing the lost rate. Our experimental results show that our RetinaFace-mnet-faster for 640*480 resolution on the Tesla P40 and single-thread improve speed of 16.7% and 70.2%, respectively. Finally, we design secondary search mechanism with HNSW to improve performance. Ours is suitable for large-scale datasets, and experimental results show that our method is 82% faster than the violent retrieval for the single-frame detection.
Top-Related Meta-Learning Method for Few-Shot Detection
Jul 27, 2020

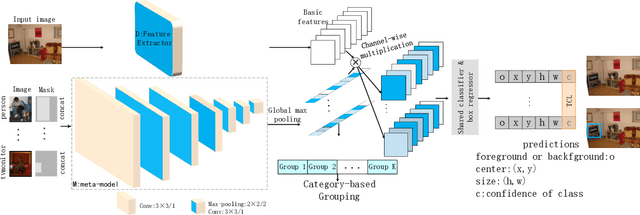

Many meta-learning methods are proposed for few-shot detection. However, previous most methods have two main problems, strong bias between all classes, and poor classification for few-shot classes. Previous works mainly depend on additional datasets and sub-module to alleviate these issues. However, they require more cost. In this paper, we find that the main challenge lies on imbalance between the examples, and poor shared distribution of class-based meta-features. Therefore, we propose a TCL for classification task and a category-based grouping mechanism. The TCL exploits the classification score of true-label class and the classification score of the most similar class to improve detection performance on few-shot classes. According to appearance and environment, the category-based grouping mechanism groups categories into different groupings to promote different similar semantic features more compact, alleviating the strong bias problem and further improving few-shot detection APs. The whole training consists of the base model and the fine-tuning phase. During training detection model, the category-related meta-features are regarded as the weights of the detection layer, exploiting the meta-features with a shared distribution between categories within a group to improve the detection performance. According to grouping mechanism, we group the meta-features vectors, so that the distribution difference between groups is obvious, and the one within each group is less. Experimental results on Pascal VOC dataset demonstrate that ours which combines the TCL with category-based grouping significantly outperforms previous state-of-the-art methods for 1, 2-shot detection, and obtains detection APs of almost 30% for 3-shot detection.
Pixel-Semantic Revise of Position Learning A One-Stage Object Detector with A Shared Encoder-Decoder
Jan 04, 2020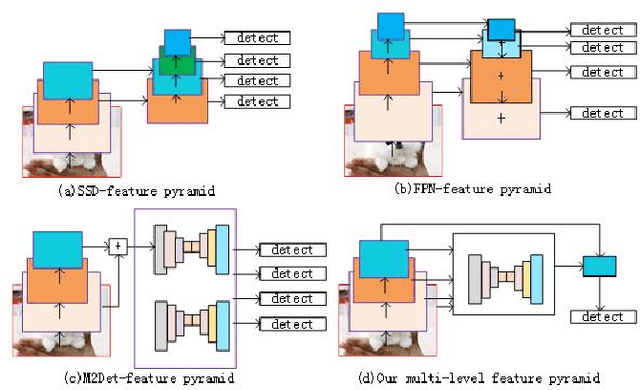
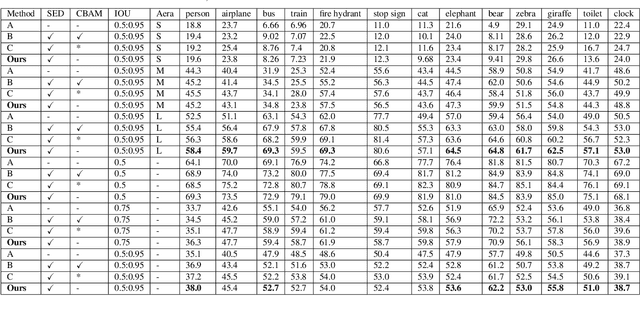
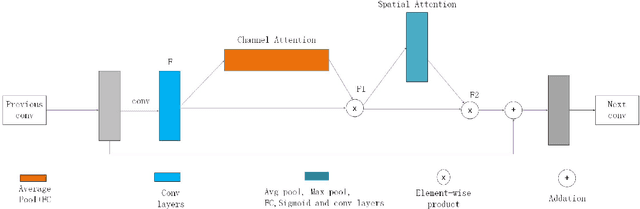

We analyze that different methods based channel or position attention mechanism give rise to different performance on scale, and some of state-of-the-art detectors applying feature pyramid are integrated with various variants convolutions with many mechanisms to enhance information, resulting in increasing runtime. This work addresses the problem by constructing an anchor-free detector with shared module consisting of encoder and decoder with attention mechanism. First, we consider different level features from backbone (e.g., ResNet-50) as the base features. Second, we feed the feature into a simple block, rather than various complex operations.Then, location and classification tasks are obtained by the detector head and classifier, respectively. At the same time, we use the semantic information to revise geometry locations. Additionally, we show that the detector is a pixel-semantic revise of position, universal, effective and simple to detect, especially, large-scale objects. More importantly, this work compares different feature processing (e.g.,mean, maximum or minimum) performance across channel. Finally,we present that our method improves detection accuracy by 3.8 AP compared to state-of-the-art MNC based ResNet-101 on the standard MSCOCO baseline.
Utilizing the Instability in Weakly Supervised Object Detection
Jun 14, 2019

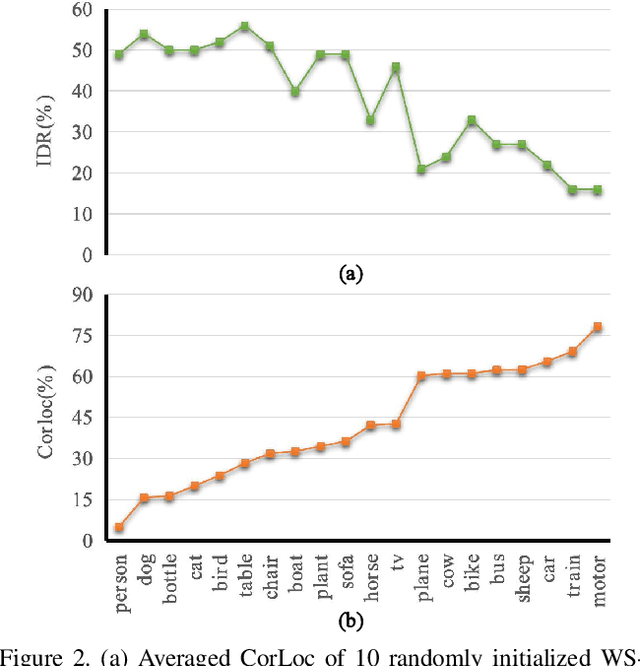

Weakly supervised object detection (WSOD) focuses on training object detector with only image-level annotations, and is challenging due to the gap between the supervision and the objective. Most of existing approaches model WSOD as a multiple instance learning (MIL) problem. However, we observe that the result of MIL based detector is unstable, i.e., the most confident bounding boxes change significantly when using different initializations. We quantitatively demonstrate the instability by introducing a metric to measure it, and empirically analyze the reason of instability. Although the instability seems harmful for detection task, we argue that it can be utilized to improve the performance by fusing the results of differently initialized detectors. To implement this idea, we propose an end-to-end framework with multiple detection branches, and introduce a simple fusion strategy. We further propose an orthogonal initialization method to increase the difference between detection branches. By utilizing the instability, we achieve 52.6% and 48.0% mAP on the challenging PASCAL VOC 2007 and 2012 datasets, which are both the new state-of-the-arts.