 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Enabling Dynamic Convolution Neural Network Inference for Edge Intelligence
Feb 18, 2022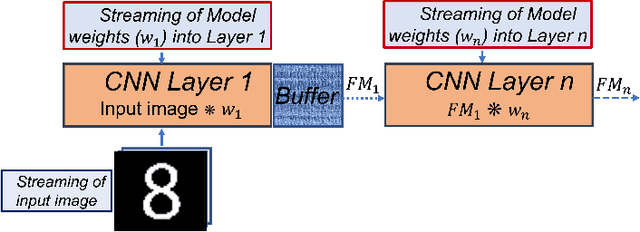
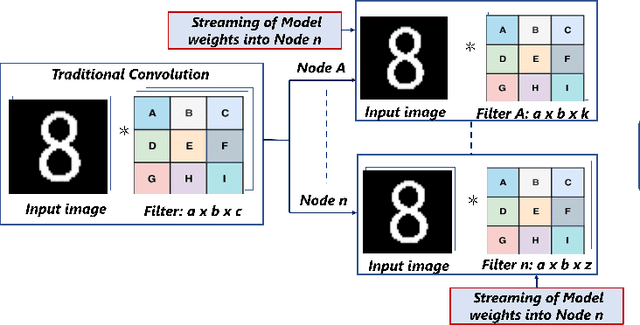
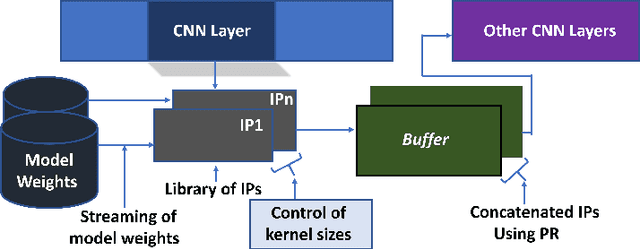
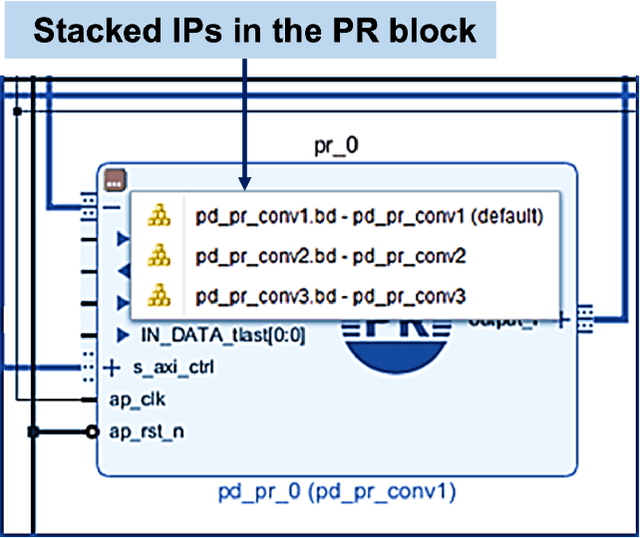
Deep learning applications have achieved great success in numerous real-world applications. Deep learning models, especially Convolution Neural Networks (CNN) are often prototyped using FPGA because it offers high power efficiency and reconfigurability. The deployment of CNNs on FPGAs follows a design cycle that requires saving of model parameters in the on-chip memory during High-level synthesis (HLS). Recent advances in edge intelligence require CNN inference on edge network to increase throughput and reduce latency. To provide flexibility, dynamic parameter allocation to different mobile devices is required to implement either a predefined or defined on-the-fly CNN architecture. In this study, we present novel methodologies for dynamically streaming the model parameters at run-time to implement a traditional CNN architecture. We further propose a library-based approach to design scalable and dynamic distributed CNN inference on the fly leveraging partial-reconfiguration techniques, which is particularly suitable for resource-constrained edge devices. The proposed techniques are implemented on the Xilinx PYNQ-Z2 board to prove the concept by utilizing the LeNet-5 CNN model. The results show that the proposed methodologies are effective, with classification accuracy rates of 92%, 86%, and 94% respectively
Security Analysis of Capsule Network Inference using Horizontal Collaboration
Sep 22, 2021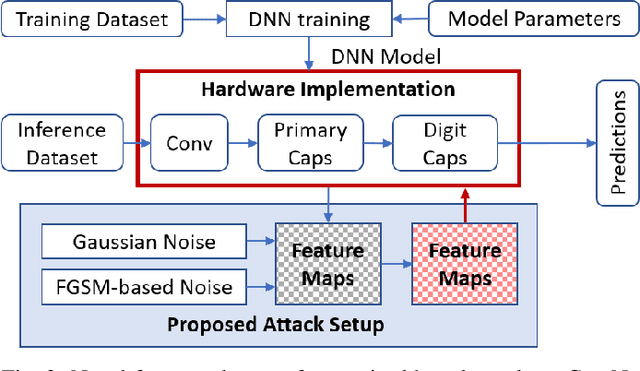
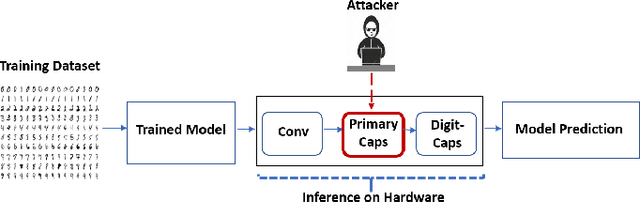

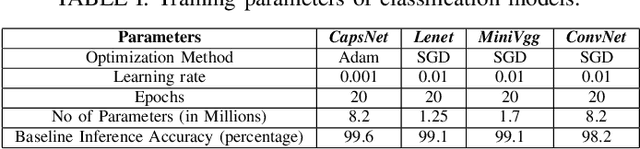
The traditional convolution neural networks (CNN) have several drawbacks like the Picasso effect and the loss of information by the pooling layer. The Capsule network (CapsNet) was proposed to address these challenges because its architecture can encode and preserve the spatial orientation of input images. Similar to traditional CNNs, CapsNet is also vulnerable to several malicious attacks, as studied by several researchers in the literature. However, most of these studies focus on single-device-based inference, but horizontally collaborative inference in state-of-the-art systems, like intelligent edge services in self-driving cars, voice controllable systems, and drones, nullify most of these analyses. Horizontal collaboration implies partitioning the trained CNN models or CNN tasks to multiple end devices or edge nodes. Therefore, it is imperative to examine the robustness of the CapsNet against malicious attacks when deployed in horizontally collaborative environments. Towards this, we examine the robustness of the CapsNet when subjected to noise-based inference attacks in a horizontal collaborative environment. In this analysis, we perturbed the feature maps of the different layers of four DNN models, i.e., CapsNet, Mini-VGG, LeNet, and an in-house designed CNN (ConvNet) with the same number of parameters as CapsNet, using two types of noised-based attacks, i.e., Gaussian Noise Attack and FGSM noise attack. The experimental results show that similar to the traditional CNNs, depending upon the access of the attacker to the DNN layer, the classification accuracy of the CapsNet drops significantly. For example, when Gaussian Noise Attack classification is performed at the DigitCap layer of the CapsNet, the maximum classification accuracy drop is approximately 97%.
Dynamic Distribution of Edge Intelligence at the Node Level for Internet of Things
Jul 13, 2021
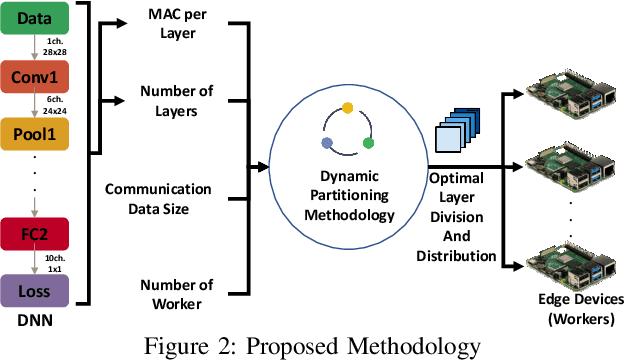
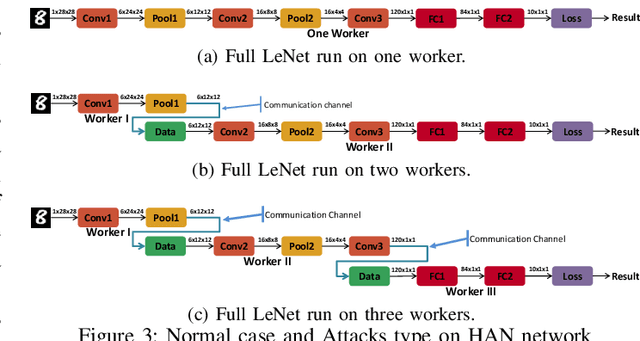
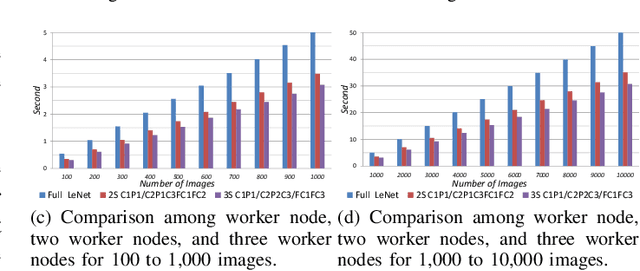
In this paper, dynamic deployment of Convolutional Neural Network (CNN) architecture is proposed utilizing only IoT-level devices. By partitioning and pipelining the CNN, it horizontally distributes the computation load among resource-constrained devices (called horizontal collaboration), which in turn increases the throughput. Through partitioning, we can decrease the computation and energy consumption on individual IoT devices and increase the throughput without sacrificing accuracy. Also, by processing the data at the generation point, data privacy can be achieved. The results show that throughput can be increased by 1.55x to 1.75x for sharing the CNN into two and three resource-constrained devices, respectively.
SoWaF: Shuffling of Weights and Feature Maps: A Novel Hardware Intrinsic Attack on Convolutional Neural Network
Mar 16, 2021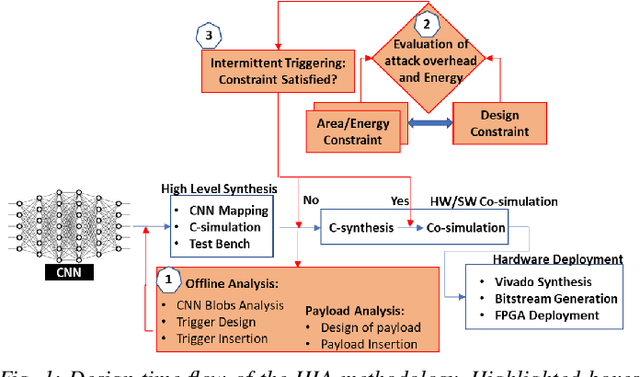
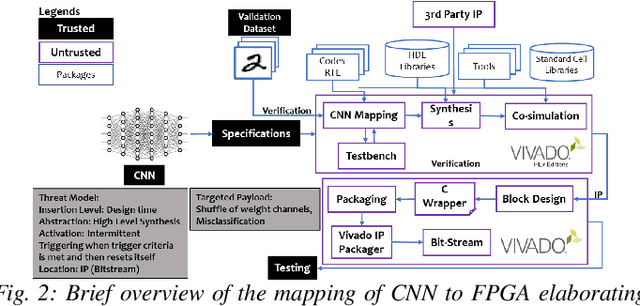
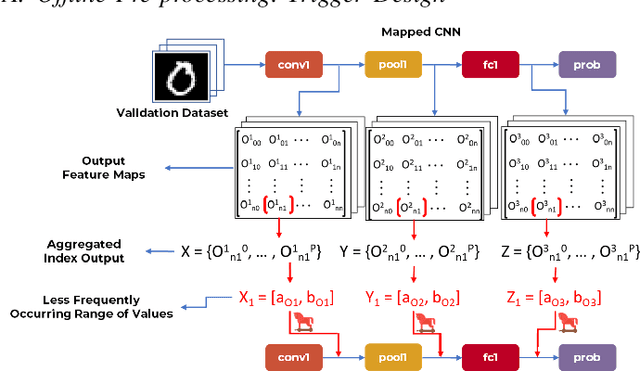
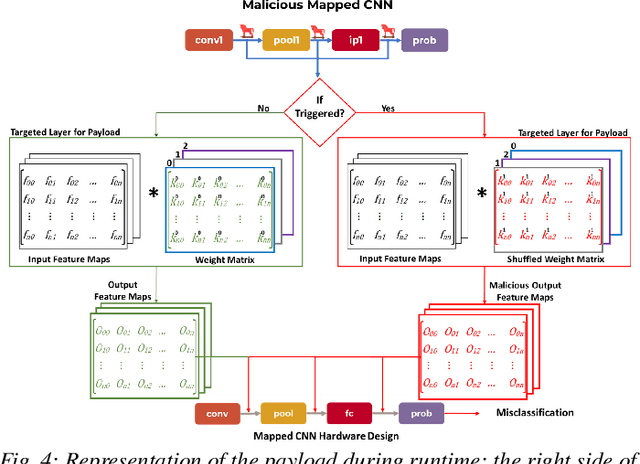
Security of inference phase deployment of Convolutional neural network (CNN) into resource constrained embedded systems (e.g. low end FPGAs) is a growing research area. Using secure practices, third party FPGA designers can be provided with no knowledge of initial and final classification layers. In this work, we demonstrate that hardware intrinsic attack (HIA) in such a "secure" design is still possible. Proposed HIA is inserted inside mathematical operations of individual layers of CNN, which propagates erroneous operations in all the subsequent CNN layers that lead to misclassification. The attack is non-periodic and completely random, hence it becomes difficult to detect. Five different attack scenarios with respect to each CNN layer are designed and evaluated based on the overhead resources and the rate of triggering in comparison to the original implementation. Our results for two CNN architectures show that in all the attack scenarios, additional latency is negligible (<0.61%), increment in DSP, LUT, FF is also less than 2.36%. Three attack scenarios do not require any additional BRAM resources, while in two scenarios BRAM increases, which compensates with the corresponding decrease in FF and LUTs. To the authors' best knowledge this work is the first to address the hardware intrinsic CNN attack with the attacker does not have knowledge of the full CNN.
How Secure is Distributed Convolutional Neural Network on IoT Edge Devices?
Jun 16, 2020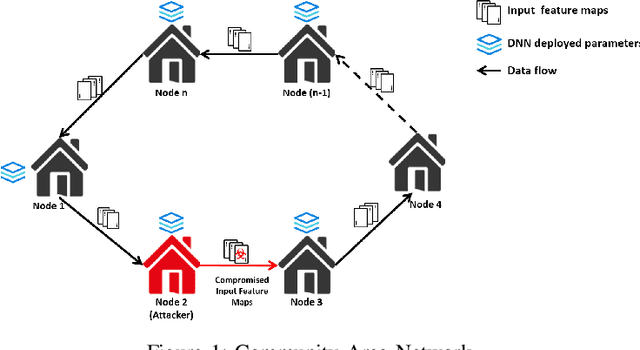

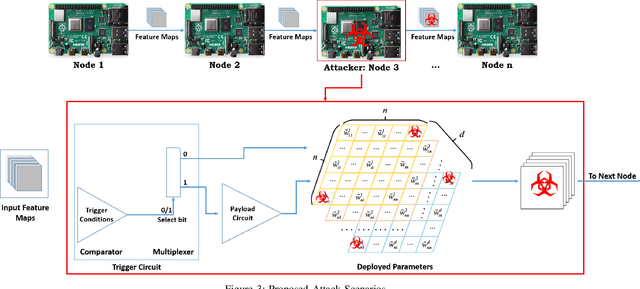
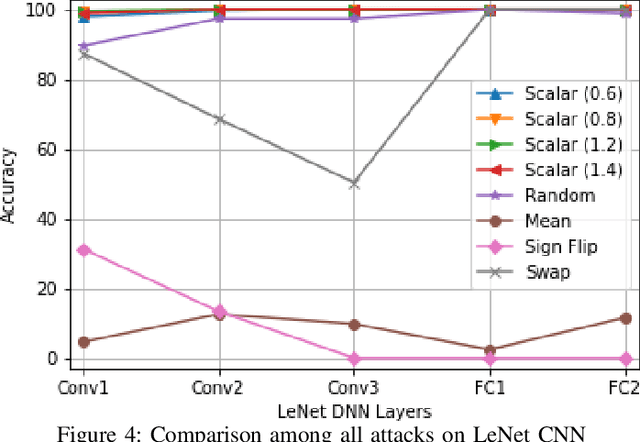
Convolutional Neural Networks (CNN) has found successful adoption in many applications. The deployment of CNN on resource-constrained edge devices have proved challenging. CNN distributed deployment across different edge devices has been adopted. In this paper, we propose Trojan attacks on CNN deployed across a distributed edge network across different nodes. We propose five stealthy attack scenarios for distributed CNN inference. These attacks are divided into trigger and payload circuitry. These attacks are tested on deep learning models (LeNet, AlexNet). The results show how the degree of vulnerability of individual layers and how critical they are to the final classification.
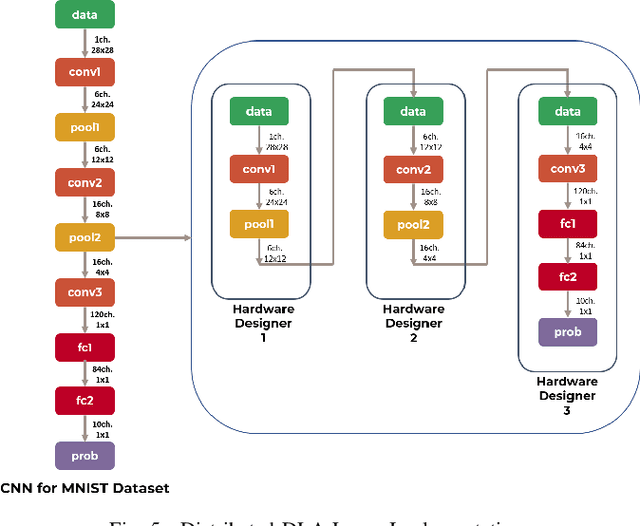
2L-3W: 2-Level 3-Way Hardware-Software Co-Verification for the Mapping of Deep Learning Architecture onto FPGA Boards
Nov 14, 2019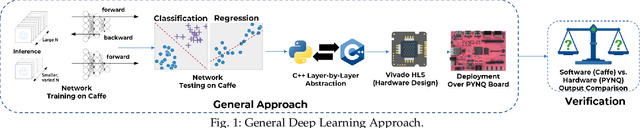
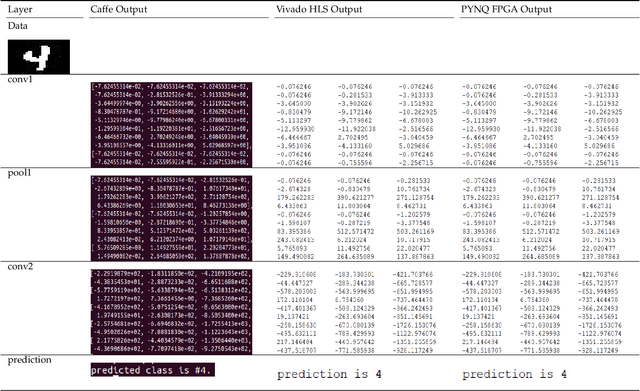
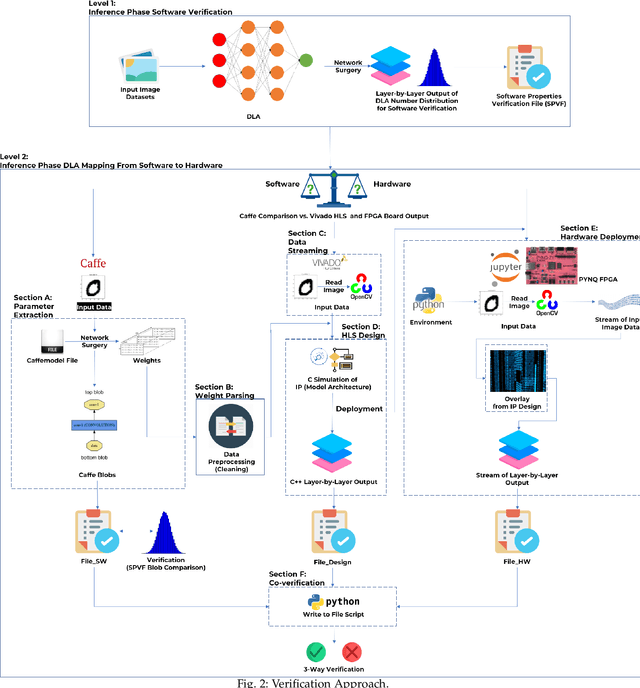
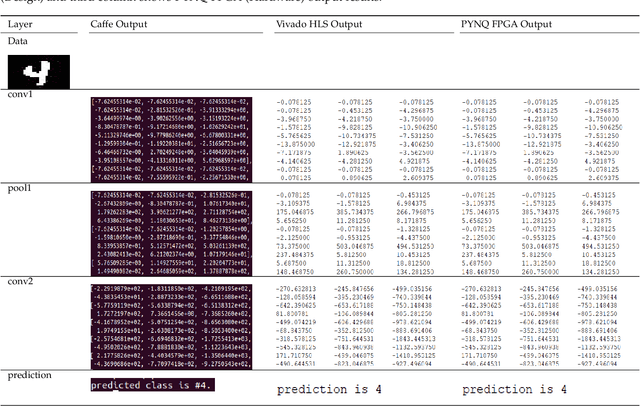
FPGAs have become a popular choice for deploying deep learning architectures (DLA). There are many researchers that have explored the deployment and mapping of DLA on FPGA. However, there has been a growing need to do design-time hardware-software co-verification of these deployments. To the best of our knowledge this is the first work that proposes a 2-Level 3-Way (2L-3W) hardware-software co-verification methodology and provides a step-by-step guide for the successful mapping, deployment and verification of DLA on FPGA boards. The 2-Level verification is to make sure the implementation in each stage (software and hardware) are following the desired behavior. The 3-Way co-verification provides a cross-paradigm (software, design and hardware) layer-by-layer parameter check to assure the correct implementation and mapping of the DLA onto FPGA boards. The proposed 2L-3W co-verification methodology has been evaluated over several test cases. In each case, the prediction and layer-by-layer output of the DLA deployed on PYNQ FPGA board (hardware) alongside with the intermediate design results of the layer-by-layer output of the DLA implemented on Vivado HLS and the prediction and layer-by-layer output of the software level (Caffe deep learning framework) are compared to obtain a layer-by-layer similarity score. The comparison is achieved using a completely automated Python script. The comparison provides a layer-by-layer similarity score that informs us the degree of success of the DLA mapping to the FPGA or help identify in design time the layer to be debugged in the case of unsuccessful mapping. We demonstrated our technique on LeNet DLA and Caffe inspired Cifar-10 DLA and the co-verification results yielded layer-by-layer similarity scores of 99\% accuracy.
A Scalable Multilabel Classification to Deploy Deep Learning Architectures For Edge Devices
Nov 07, 2019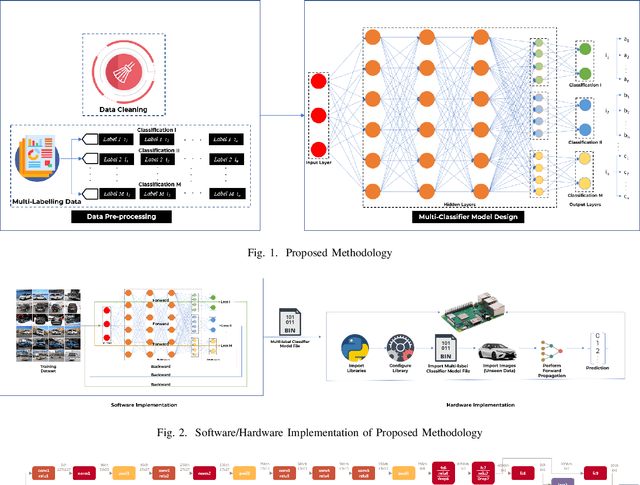


Convolution Neural Networks (CNN) have performed well in many applications such as object detection, pattern recognition, video surveillance and so on. CNN carryout feature extraction on labelled data to perform classification. Multi-label classification assigns more than one label to a particular data sample in a data set. In multi-label classification, properties of a data point that are considered to be mutually exclusive are classified. However, existing multi-label classification requires some form of data pre-processing that involves image training data cropping or image tiling. The computation and memory requirement of these multi-label CNN models makes their deployment on edge devices challenging. In this paper, we propose a methodology that solves this problem by extending the capability of existing multi-label classification and provide models with lower latency that requires smaller memory size when deployed on edge devices. We make use of a single CNN model designed with multiple loss layers and multiple accuracy layers. This methodology is tested on state-of-the-art deep learning algorithms such as AlexNet, GoogleNet and SqueezeNet using the Stanford Cars Dataset and deployed on Raspberry Pi3. From the results the proposed methodology achieves comparable accuracy with 1.8x less MACC operation, 0.97x reduction in latency and 0.5x, 0.84x and 0.97x reduction in size for the generated AlexNet, GoogleNet and SqueezeNet CNN models respectively when compared to conventional ways of achieving multi-label classification like hard-coding multi-label instances into single labels. The methodology also yields CNN models that achieve 50\% less MACC operations, 50% reduction in latency and size of generated versions of AlexNet, GoogleNet and SqueezeNet respectively when compared to conventional ways using 2 different single-labelled models to achieve multi-label classification.
A Stealthy Hardware Trojan Exploiting the Architectural Vulnerability of Deep Learning Architectures: Input Interception Attack (IIA)
Nov 02, 2019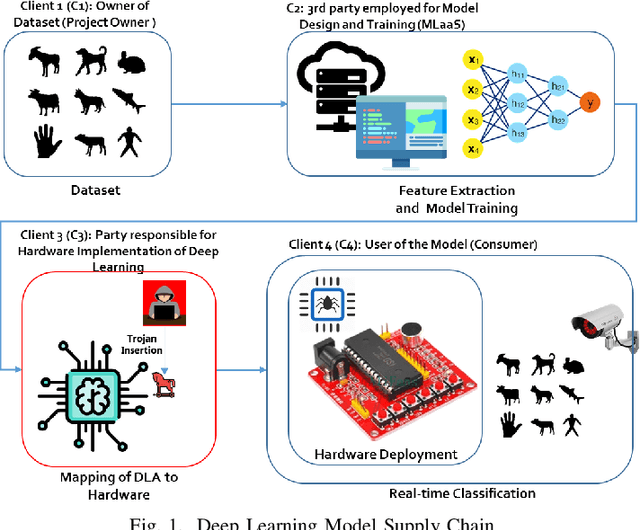

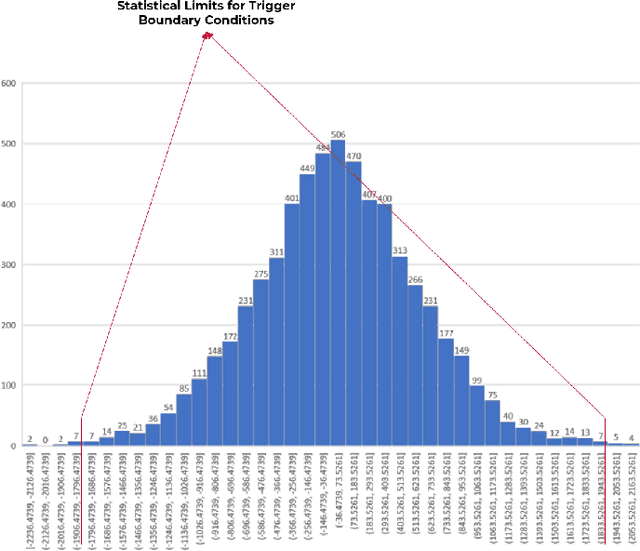
Deep learning architectures (DLA) have shown impressive performance in computer vision, natural language processing and so on. Many DLA make use of cloud computing to achieve classification due to the high computation and memory requirements. Privacy and latency concerns resulting from cloud computing has inspired the deployment of DLA on embedded hardware accelerators. To achieve short time-to-market and have access to global experts, state-of-the-art techniques of DLA deployment on hardware accelerators are outsourced to untrusted third parties. This outsourcing raises security concerns as hardware Trojans can be inserted into the hardware design of the mapped DLA of the hardware accelerator. We argue that existing hardware Trojan attacks highlighted in literature have no qualitative means how definite they are of the triggering of the Trojan. Also, most inserted Trojans show a obvious spike in the number of hardware resources utilized on the accelerator at the time of triggering the Trojan or when the payload is active. In this paper, we propose a hardware Trojan attack called Input Interception Attack (IIA). In this attack we make use of the statistical properties of layer-by-layer output to make sure that asides from being stealthy, our IIA is able to trigger with some measure of definiteness. This IIA attack is tested on DLA used to classify MNIST and Cifar-10 data sets. The attacked design utilizes approximately up to 2% more LUTs respectively compared to the un-compromised designs. This paper also discusses potential defensive mechanisms that could be used to combat such hardware Trojans based attack in hardware accelerators for DLA.