 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Enabling Dynamic Convolution Neural Network Inference for Edge Intelligence
Paper and Code
Feb 18, 2022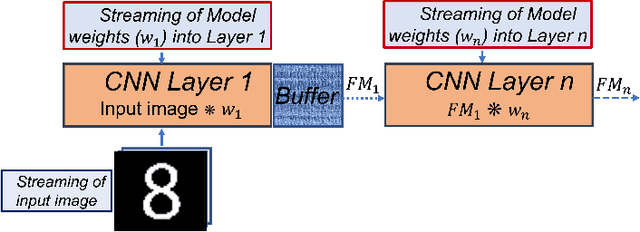
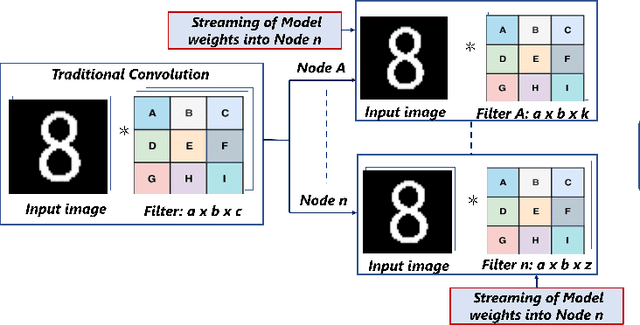
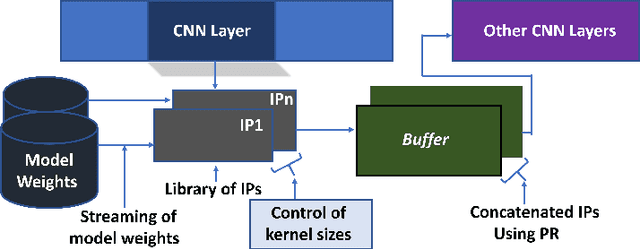
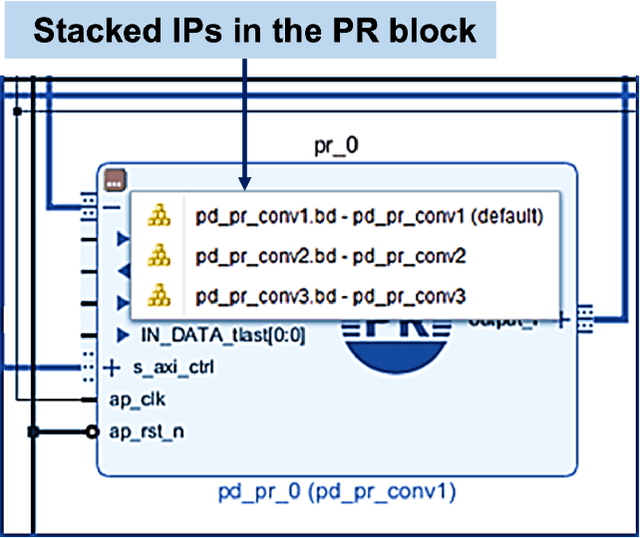
Deep learning applications have achieved great success in numerous real-world applications. Deep learning models, especially Convolution Neural Networks (CNN) are often prototyped using FPGA because it offers high power efficiency and reconfigurability. The deployment of CNNs on FPGAs follows a design cycle that requires saving of model parameters in the on-chip memory during High-level synthesis (HLS). Recent advances in edge intelligence require CNN inference on edge network to increase throughput and reduce latency. To provide flexibility, dynamic parameter allocation to different mobile devices is required to implement either a predefined or defined on-the-fly CNN architecture. In this study, we present novel methodologies for dynamically streaming the model parameters at run-time to implement a traditional CNN architecture. We further propose a library-based approach to design scalable and dynamic distributed CNN inference on the fly leveraging partial-reconfiguration techniques, which is particularly suitable for resource-constrained edge devices. The proposed techniques are implemented on the Xilinx PYNQ-Z2 board to prove the concept by utilizing the LeNet-5 CNN model. The results show that the proposed methodologies are effective, with classification accuracy rates of 92%, 86%, and 94% respectively