 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Enabling Dynamic Convolution Neural Network Inference for Edge Intelligence
Feb 18, 2022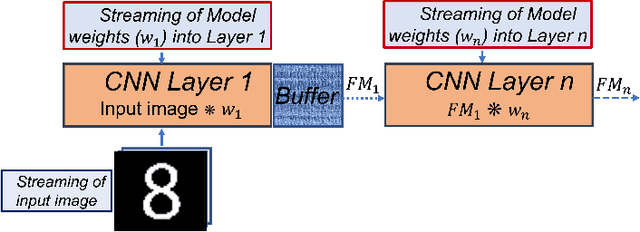
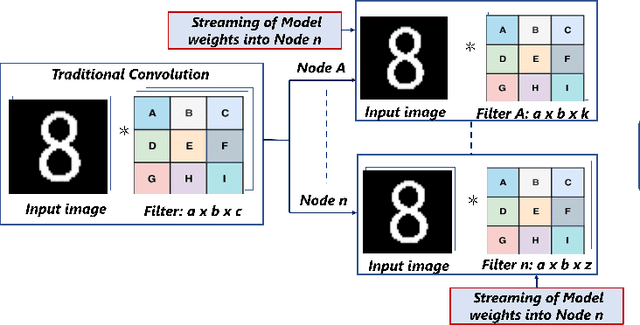
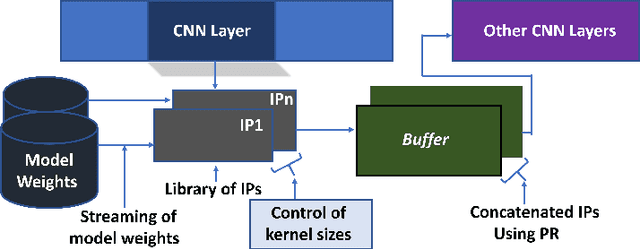
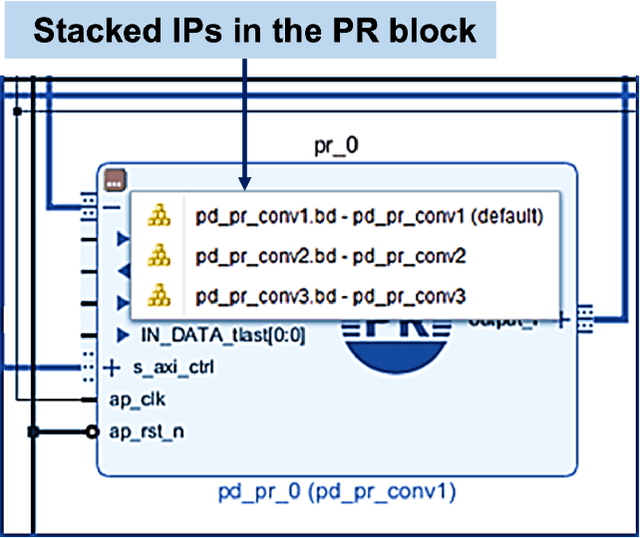
Deep learning applications have achieved great success in numerous real-world applications. Deep learning models, especially Convolution Neural Networks (CNN) are often prototyped using FPGA because it offers high power efficiency and reconfigurability. The deployment of CNNs on FPGAs follows a design cycle that requires saving of model parameters in the on-chip memory during High-level synthesis (HLS). Recent advances in edge intelligence require CNN inference on edge network to increase throughput and reduce latency. To provide flexibility, dynamic parameter allocation to different mobile devices is required to implement either a predefined or defined on-the-fly CNN architecture. In this study, we present novel methodologies for dynamically streaming the model parameters at run-time to implement a traditional CNN architecture. We further propose a library-based approach to design scalable and dynamic distributed CNN inference on the fly leveraging partial-reconfiguration techniques, which is particularly suitable for resource-constrained edge devices. The proposed techniques are implemented on the Xilinx PYNQ-Z2 board to prove the concept by utilizing the LeNet-5 CNN model. The results show that the proposed methodologies are effective, with classification accuracy rates of 92%, 86%, and 94% respectively
FeSHI: Feature Map Based Stealthy Hardware Intrinsic Attack
Jun 13, 2021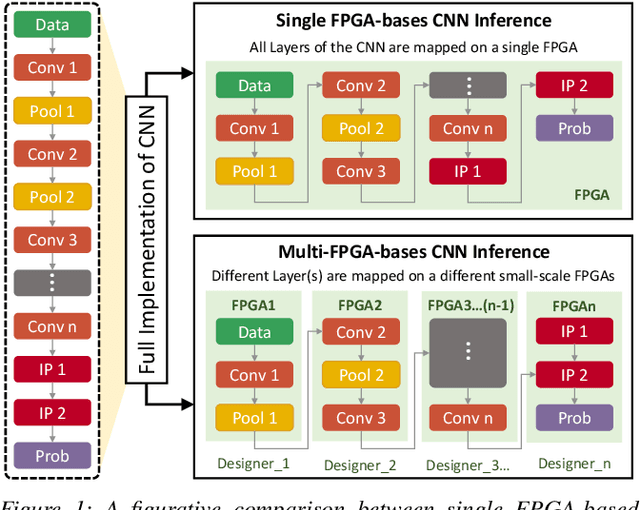

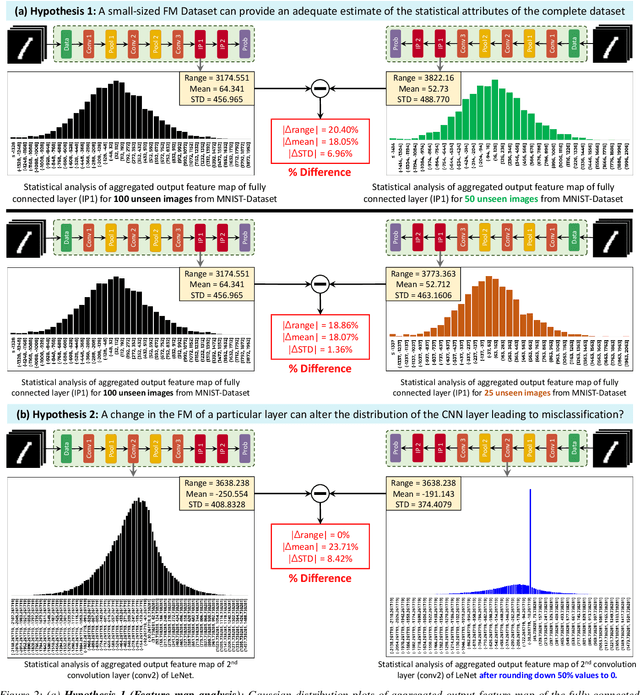
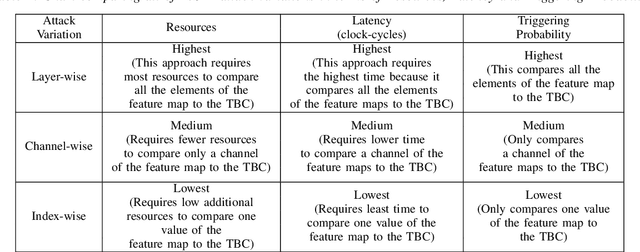
Convolutional Neural Networks (CNN) have shown impressive performance in computer vision, natural language processing, and many other applications, but they exhibit high computations and substantial memory requirements. To address these limitations, especially in resource-constrained devices, the use of cloud computing for CNNs is becoming more popular. This comes with privacy and latency concerns that have motivated the designers to develop embedded hardware accelerators for CNNs. However, designing a specialized accelerator increases the time-to-market and cost of production. Therefore, to reduce the time-to-market and access to state-of-the-art techniques, CNN hardware mapping and deployment on embedded accelerators are often outsourced to untrusted third parties, which is going to be more prevalent in futuristic artificial intelligence of things (AIoT) systems. These AIoT systems anticipate horizontal collaboration among different resource-constrained AIoT node devices, where CNN layers are partitioned and these devices collaboratively compute complex CNN tasks Therefore, there is a dire need to explore this attack surface for designing secure embedded hardware accelerators for CNNs. Towards this goal, in this paper, we exploited this attack surface to propose an HT-based attack called FeSHI. This attack exploits the statistical distribution i.e., Gaussian distribution, of the layer-by-layer feature maps of the CNN to design two triggers for stealthy HT with a very low probability of triggering. To illustrate the effectiveness of the proposed attack, we deployed the LeNet and LeNet-3D on PYNQ to classify the MNIST and CIFAR-10 datasets, respectively, and tested FeSHI. The experimental results show that FeSHI utilizes up to 2% extra LUTs, and the overall resource overhead is less than 1% compared to the original designs