 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Analysis of Capsule Network Inference using Horizontal Collaboration
Sep 22, 2021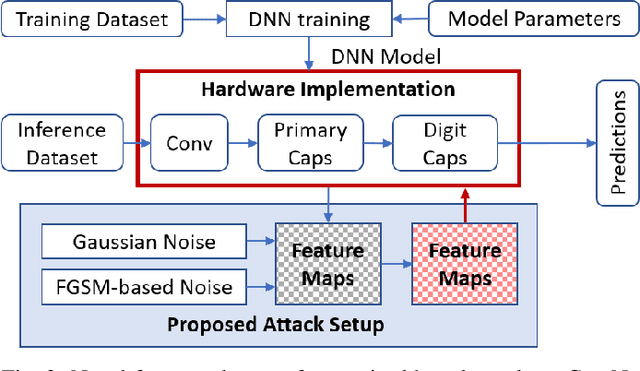
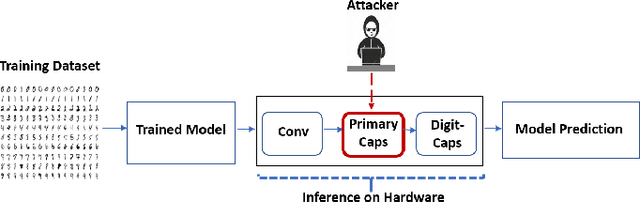

The traditional convolution neural networks (CNN) have several drawbacks like the Picasso effect and the loss of information by the pooling layer. The Capsule network (CapsNet) was proposed to address these challenges because its architecture can encode and preserve the spatial orientation of input images. Similar to traditional CNNs, CapsNet is also vulnerable to several malicious attacks, as studied by several researchers in the literature. However, most of these studies focus on single-device-based inference, but horizontally collaborative inference in state-of-the-art systems, like intelligent edge services in self-driving cars, voice controllable systems, and drones, nullify most of these analyses. Horizontal collaboration implies partitioning the trained CNN models or CNN tasks to multiple end devices or edge nodes. Therefore, it is imperative to examine the robustness of the CapsNet against malicious attacks when deployed in horizontally collaborative environments. Towards this, we examine the robustness of the CapsNet when subjected to noise-based inference attacks in a horizontal collaborative environment. In this analysis, we perturbed the feature maps of the different layers of four DNN models, i.e., CapsNet, Mini-VGG, LeNet, and an in-house designed CNN (ConvNet) with the same number of parameters as CapsNet, using two types of noised-based attacks, i.e., Gaussian Noise Attack and FGSM noise attack. The experimental results show that similar to the traditional CNNs, depending upon the access of the attacker to the DNN layer, the classification accuracy of the CapsNet drops significantly. For example, when Gaussian Noise Attack classification is performed at the DigitCap layer of the CapsNet, the maximum classification accuracy drop is approximately 97%.
FeSHI: Feature Map Based Stealthy Hardware Intrinsic Attack
Jun 13, 2021

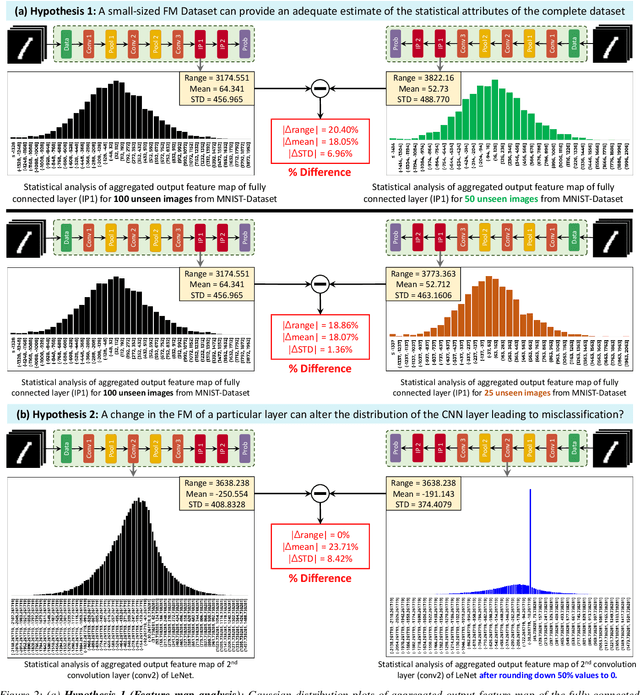
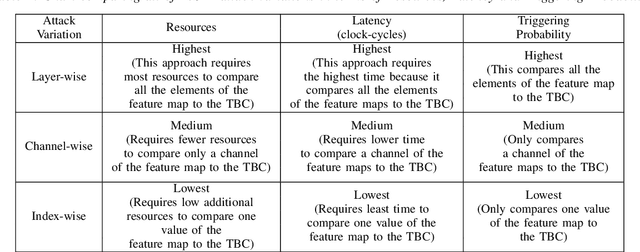
Convolutional Neural Networks (CNN) have shown impressive performance in computer vision, natural language processing, and many other applications, but they exhibit high computations and substantial memory requirements. To address these limitations, especially in resource-constrained devices, the use of cloud computing for CNNs is becoming more popular. This comes with privacy and latency concerns that have motivated the designers to develop embedded hardware accelerators for CNNs. However, designing a specialized accelerator increases the time-to-market and cost of production. Therefore, to reduce the time-to-market and access to state-of-the-art techniques, CNN hardware mapping and deployment on embedded accelerators are often outsourced to untrusted third parties, which is going to be more prevalent in futuristic artificial intelligence of things (AIoT) systems. These AIoT systems anticipate horizontal collaboration among different resource-constrained AIoT node devices, where CNN layers are partitioned and these devices collaboratively compute complex CNN tasks Therefore, there is a dire need to explore this attack surface for designing secure embedded hardware accelerators for CNNs. Towards this goal, in this paper, we exploited this attack surface to propose an HT-based attack called FeSHI. This attack exploits the statistical distribution i.e., Gaussian distribution, of the layer-by-layer feature maps of the CNN to design two triggers for stealthy HT with a very low probability of triggering. To illustrate the effectiveness of the proposed attack, we deployed the LeNet and LeNet-3D on PYNQ to classify the MNIST and CIFAR-10 datasets, respectively, and tested FeSHI. The experimental results show that FeSHI utilizes up to 2% extra LUTs, and the overall resource overhead is less than 1% compared to the original designs
Exploiting Vulnerabilities in Deep Neural Networks: Adversarial and Fault-Injection Attacks
May 05, 2021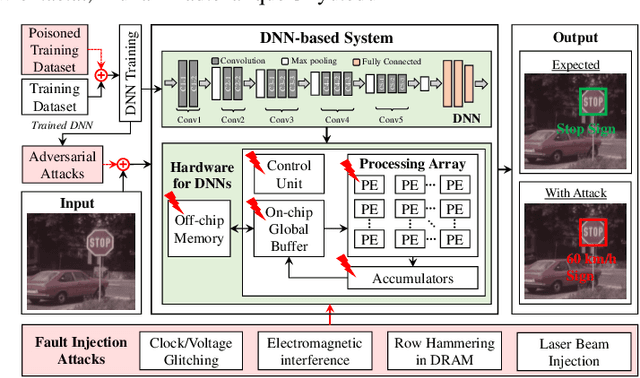
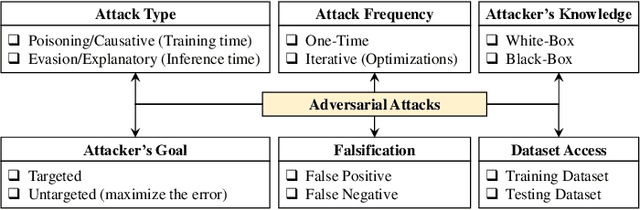
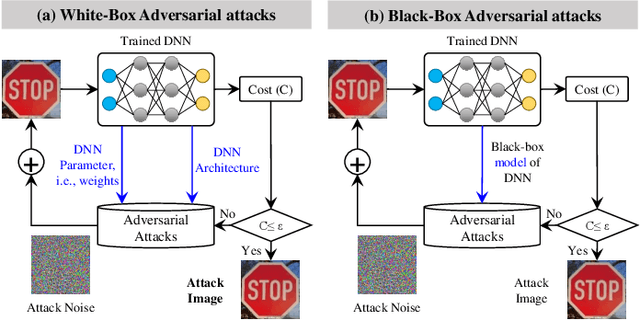

From tiny pacemaker chips to aircraft collision avoidance systems, the state-of-the-art Cyber-Physical Systems (CPS) have increasingly started to rely on Deep Neural Networks (DNNs). However, as concluded in various studies, DNNs are highly susceptible to security threats, including adversarial attacks. In this paper, we first discuss different vulnerabilities that can be exploited for generating security attacks for neural network-based systems. We then provide an overview of existing adversarial and fault-injection-based attacks on DNNs. We also present a brief analysis to highlight different challenges in the practical implementation of adversarial attacks. Finally, we also discuss various prospective ways to develop robust DNN-based systems that are resilient to adversarial and fault-injection attacks.
MacLeR: Machine Learning-based Run-Time Hardware Trojan Detection in Resource-Constrained IoT Edge Devices
Nov 21, 2020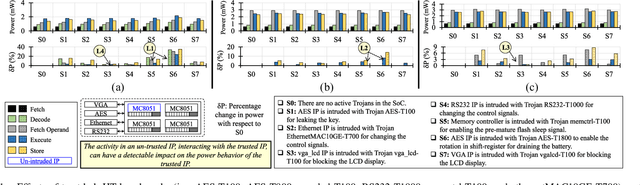
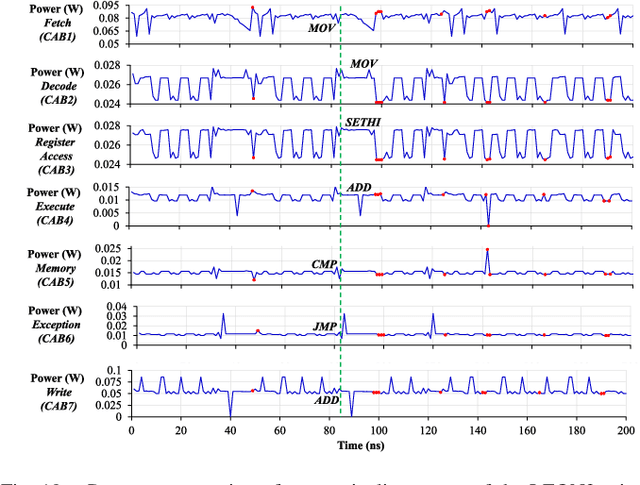
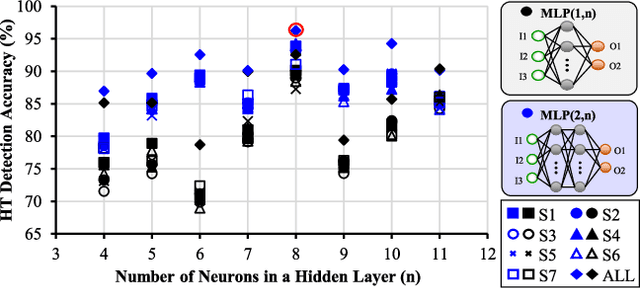
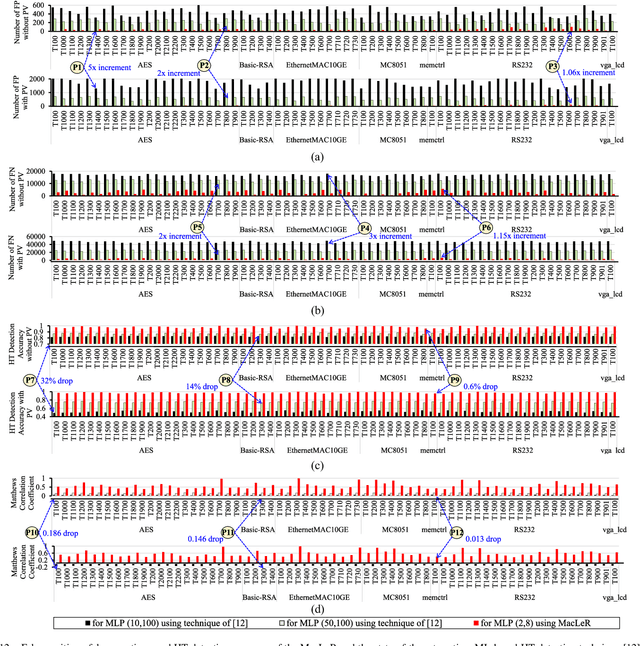
Traditional learning-based approaches for run-time Hardware Trojan detection require complex and expensive on-chip data acquisition frameworks and thus incur high area and power overhead. To address these challenges, we propose to leverage the power correlation between the executing instructions of a microprocessor to establish a machine learning-based run-time Hardware Trojan (HT) detection framework, called MacLeR. To reduce the overhead of data acquisition, we propose a single power-port current acquisition block using current sensors in time-division multiplexing, which increases accuracy while incurring reduced area overhead. We have implemented a practical solution by analyzing multiple HT benchmarks inserted in the RTL of a system-on-chip (SoC) consisting of four LEON3 processors integrated with other IPs like vga_lcd, RSA, AES, Ethernet, and memory controllers. Our experimental results show that compared to state-of-the-art HT detection techniques, MacLeR achieves 10\% better HT detection accuracy (i.e., 96.256%) while incurring a 7x reduction in area and power overhead (i.e., 0.025% of the area of the SoC and <0.07% of the power of the SoC). In addition, we also analyze the impact of process variation and aging on the extracted power profiles and the HT detection accuracy of MacLeR. Our analysis shows that variations in fine-grained power profiles due to the HTs are significantly higher compared to the variations in fine-grained power profiles caused by the process variations (PV) and aging effects. Moreover, our analysis demonstrates that, on average, the HT detection accuracy drop in MacLeR is less than 1% and 9% when considering only PV and PV with worst-case aging, respectively, which is ~10x less than in the case of the state-of-the-art ML-based HT detection technique.
FANNet: Formal Analysis of Noise Tolerance, Training Bias and Input Sensitivity in Neural Networks
Dec 03, 2019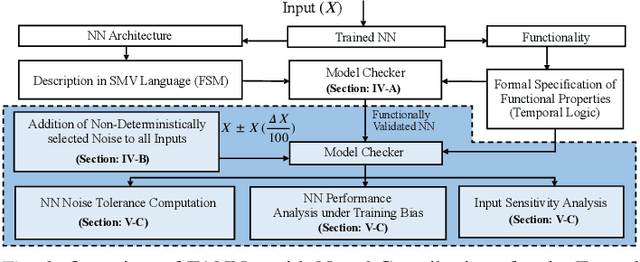
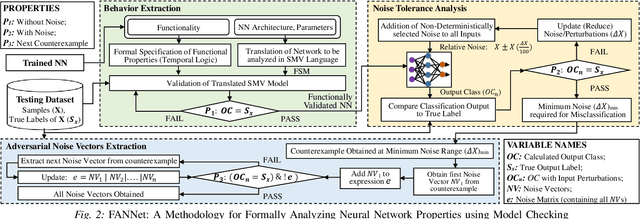
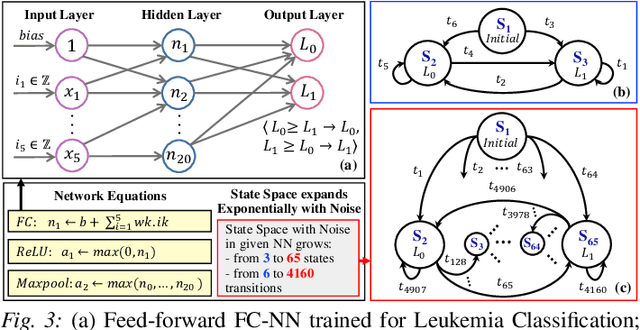
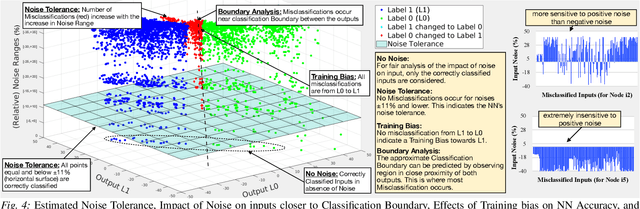
With a constant improvement in the network architectures and training methodologies, Neural Networks (NNs) are increasingly being deployed in real-world Machine Learning systems. However, despite their impressive performance on "known inputs", these NNs can fail absurdly on the "unseen inputs", especially if these real-time inputs deviate from the training dataset distributions, or contain certain types of input noise. This indicates the low noise tolerance of NNs, which is a major reason for the recent increase of adversarial attacks. This is a serious concern, particularly for safety-critical applications, where inaccurate results lead to dire consequences. We propose a novel methodology that leverages model checking for the Formal Analysis of Neural Network (FANNet) under different input noise ranges. Our methodology allows us to rigorously analyze the noise tolerance of NNs, their input node sensitivity, and the effects of training bias on their performance, e.g., in terms of classification accuracy. For evaluation, we use a feed-forward fully-connected NN architecture trained for the Leukemia classification. Our experimental results show $\pm 11\%$ noise tolerance for the given trained network, identify the most sensitive input nodes, and confirm the biasness of the available training dataset.
SNN under Attack: are Spiking Deep Belief Networks vulnerable to Adversarial Examples?
Feb 04, 2019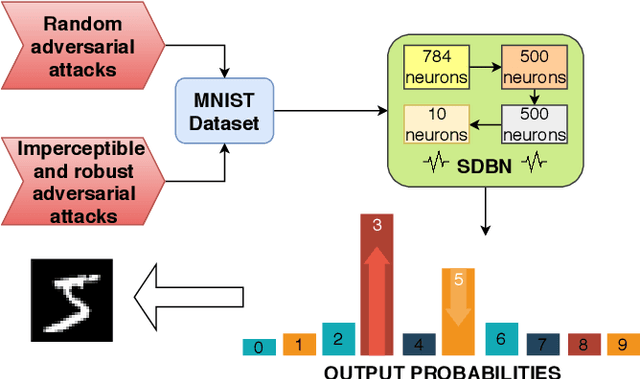
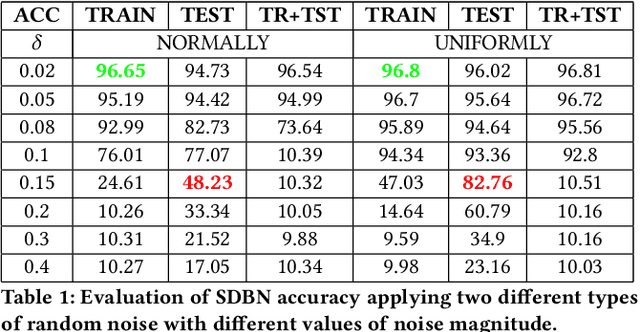
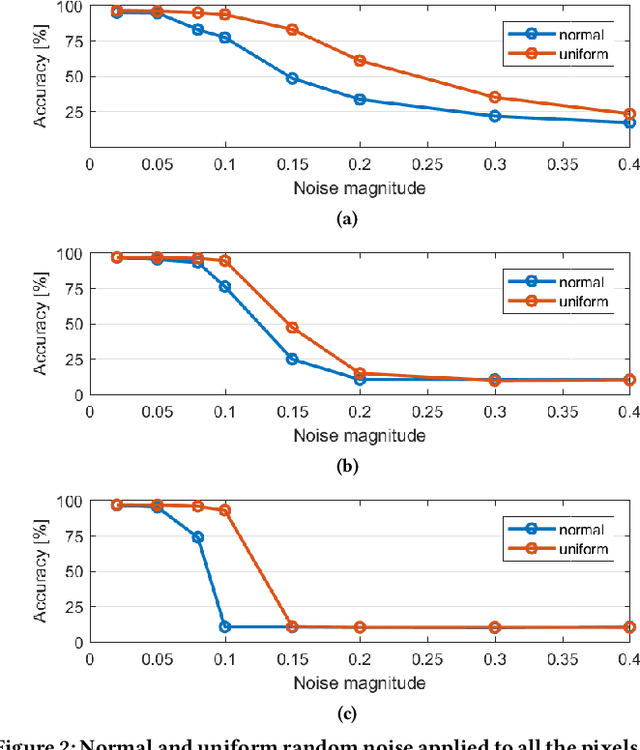
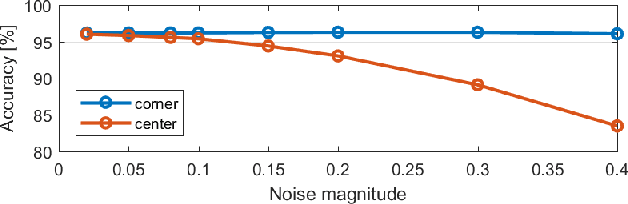
Recently, many adversarial examples have emerged for Deep Neural Networks (DNNs) causing misclassifications. However, in-depth work still needs to be performed to demonstrate such attacks and security vulnerabilities for spiking neural networks (SNNs), i.e. the 3rd generation NNs. This paper aims at addressing the fundamental questions:"Are SNNs vulnerable to the adversarial attacks as well?" and "if yes, to what extent?" Using a Spiking Deep Belief Network (SDBN) for the MNIST database classification, we show that the SNN accuracy decreases accordingly to the noise magnitude in data poisoning random attacks applied to the test images. Moreover, SDBNs generalization capabilities increase by applying noise to the training images. We develop a novel black box attack methodology to automatically generate imperceptible and robust adversarial examples through a greedy algorithm, which is first of its kind for SNNs.
RED-Attack: Resource Efficient Decision based Attack for Machine Learning
Jan 30, 2019

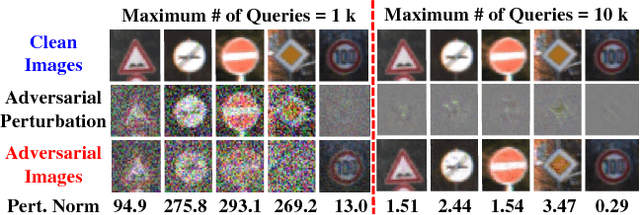
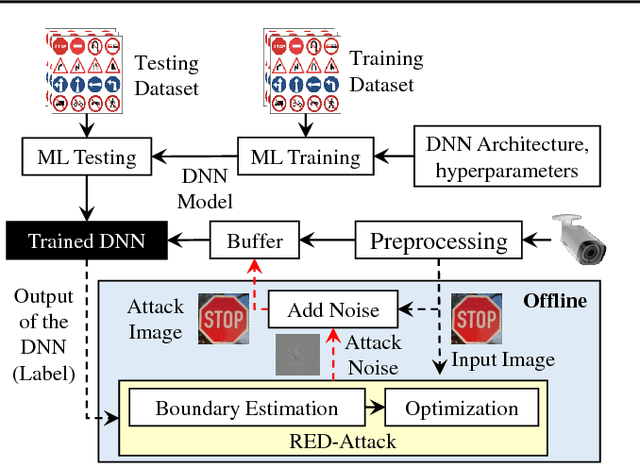
Due to data dependency and model leakage properties, Deep Neural Networks (DNNs) exhibit several security vulnerabilities. Several security attacks exploited them but most of them require the output probability vector. These attacks can be mitigated by concealing the output probability vector. To address this limitation, decision-based attacks have been proposed which can estimate the model but they require several thousand queries to generate a single untargeted attack image. However, in real-time attacks, resources and attack time are very crucial parameters. Therefore, in resource-constrained systems, e.g., autonomous vehicles where an untargeted attack can have a catastrophic effect, these attacks may not work efficiently. To address this limitation, we propose a resource efficient decision-based methodology which generates the imperceptible attack, i.e., the RED-Attack, for a given black-box model. The proposed methodology follows two main steps to generate the imperceptible attack, i.e., classification boundary estimation and adversarial noise optimization. Firstly, we propose a half-interval search-based algorithm for estimating a sample on the classification boundary using a target image and a randomly selected image from another class. Secondly, we propose an optimization algorithm which first, introduces a small perturbation in some randomly selected pixels of the estimated sample. Then to ensure imperceptibility, it optimizes the distance between the perturbed and target samples. For illustration, we evaluate it for CFAR-10 and German Traffic Sign Recognition (GTSR) using state-of-the-art networks.
CapsAttacks: Robust and Imperceptible Adversarial Attacks on Capsule Networks
Jan 28, 2019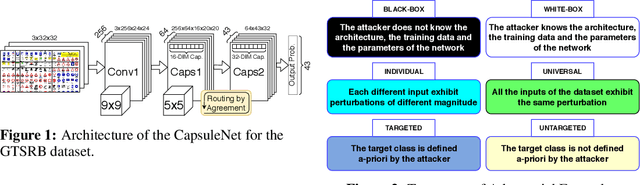


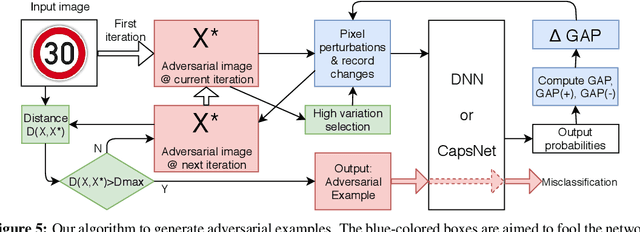
Capsule Networks envision an innovative point of view about the representation of the objects in the brain and preserve the hierarchical spatial relationships between them. This type of networks exhibits a huge potential for several Machine Learning tasks like image classification, while outperforming Convolutional Neural Networks (CNNs). A large body of work has explored adversarial examples for CNNs, but their efficacy to Capsule Networks is not well explored. In our work, we study the vulnerabilities in Capsule Networks to adversarial attacks. These perturbations, added to the test inputs, are small and imperceptible to humans, but fool the network to mis-predict. We propose a greedy algorithm to automatically generate targeted imperceptible adversarial examples in a black-box attack scenario. We show that this kind of attacks, when applied to the German Traffic Sign Recognition Benchmark (GTSRB), mislead Capsule Networks. Moreover, we apply the same kind of adversarial attacks to a 9-layer CNN and analyze the outcome, compared to the Capsule Networks to study their differences / commonalities.
A Roadmap Towards Resilient Internet of Things for Cyber-Physical Systems
Nov 06, 2018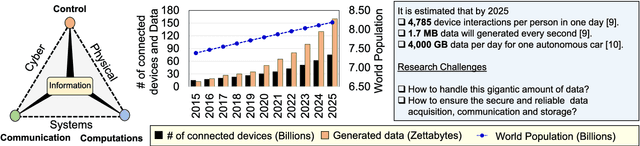
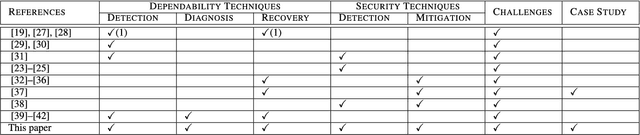
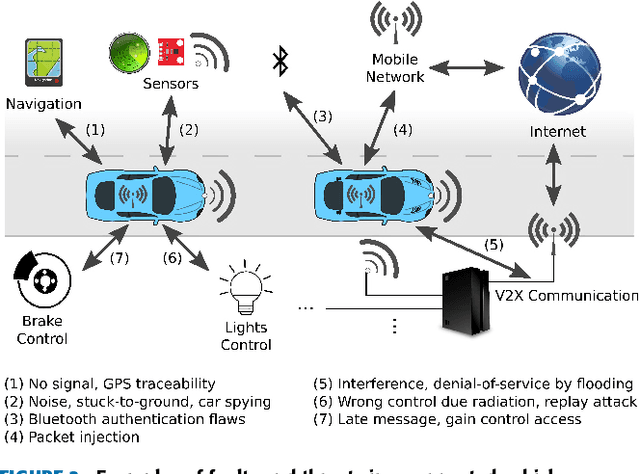

The Internet of Things (IoT) is a ubiquitous system connecting many different devices - the things - which can be accessed from the distance. The cyber-physical systems (CPS) monitor and control the things from the distance. As a result, the concepts of dependability and security get deeply intertwined. The increasing level of dynamicity, heterogeneity, and complexity adds to the system's vulnerability, and challenges its ability to react to faults. This paper summarizes state-of-the-art of existing work on anomaly detection, fault-tolerance and self-healing, and adds a number of other methods applicable to achieve resilience in an IoT. We particularly focus on non-intrusive methods ensuring data integrity in the network. Furthermore, this paper presents the main challenges in building a resilient IoT for CPS which is crucial in the era of smart CPS with enhanced connectivity (an excellent example of such a system is connected autonomous vehicles). It further summarizes our solutions, work-in-progress and future work to this topic to enable "Trustworthy IoT for CPS". Finally, this framework is illustrated on a selected use case: A smart sensor infrastructure in the transport domain.
Security for Machine Learning-based Systems: Attacks and Challenges during Training and Inference
Nov 05, 2018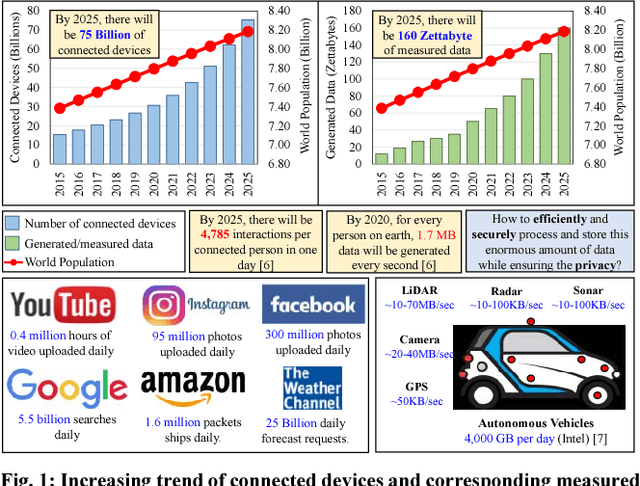
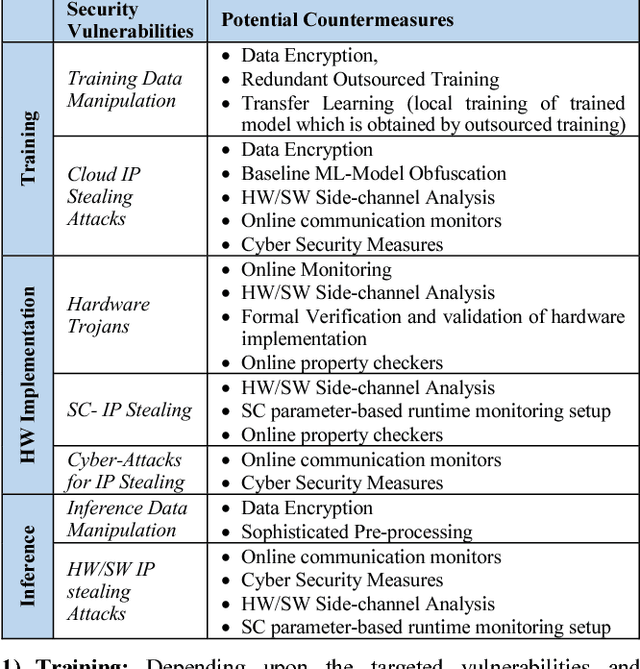
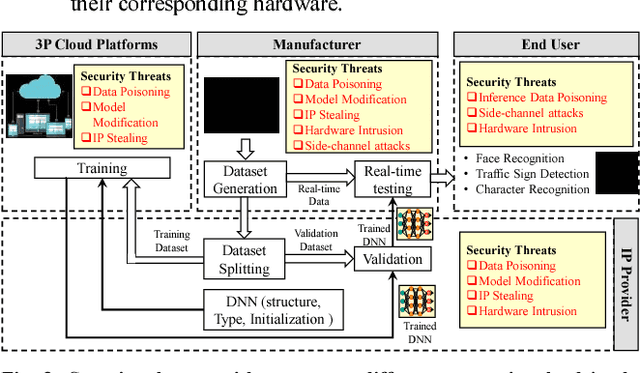
The exponential increase in dependencies between the cyber and physical world leads to an enormous amount of data which must be efficiently processed and stored. Therefore, computing paradigms are evolving towards machine learning (ML)-based systems because of their ability to efficiently and accurately process the enormous amount of data. Although ML-based solutions address the efficient computing requirements of big data, they introduce (new) security vulnerabilities into the systems, which cannot be addressed by traditional monitoring-based security measures. Therefore, this paper first presents a brief overview of various security threats in machine learning, their respective threat models and associated research challenges to develop robust security measures. To illustrate the security vulnerabilities of ML during training, inferencing and hardware implementation, we demonstrate some key security threats on ML using LeNet and VGGNet for MNIST and German Traffic Sign Recognition Benchmarks (GTSRB), respectively. Moreover, based on the security analysis of ML-training, we also propose an attack that has a very less impact on the inference accuracy. Towards the end, we highlight the associated research challenges in developing security measures and provide a brief overview of the techniques used to mitigate such security threats.