 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsAttacks: Robust and Imperceptible Adversarial Attacks on Capsule Networks
Paper and Code
Jan 28, 2019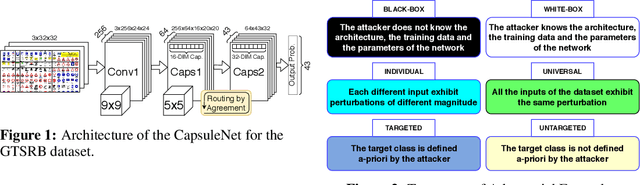


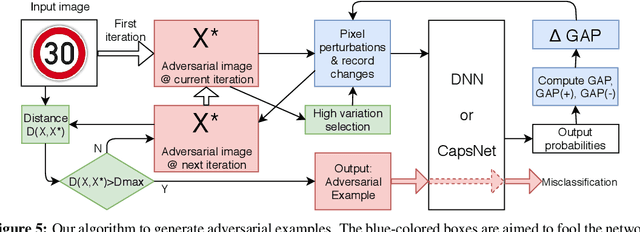
Capsule Networks envision an innovative point of view about the representation of the objects in the brain and preserve the hierarchical spatial relationships between them. This type of networks exhibits a huge potential for several Machine Learning tasks like image classification, while outperforming Convolutional Neural Networks (CNNs). A large body of work has explored adversarial examples for CNNs, but their efficacy to Capsule Networks is not well explored. In our work, we study the vulnerabilities in Capsule Networks to adversarial attacks. These perturbations, added to the test inputs, are small and imperceptible to humans, but fool the network to mis-predict. We propose a greedy algorithm to automatically generate targeted imperceptible adversarial examples in a black-box attack scenario. We show that this kind of attacks, when applied to the German Traffic Sign Recognition Benchmark (GTSRB), mislead Capsule Networks. Moreover, we apply the same kind of adversarial attacks to a 9-layer CNN and analyze the outcome, compared to the Capsule Networks to study their differences / commonalities.