 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyCL: An Efficient Hardware Architecture for Continual Learning on Autonomous Systems
Feb 15, 2024The Continuous Learning (CL) paradigm consists of continuously evolving the parameters of the Deep Neural Network (DNN) model to progressively learn to perform new tasks without reducing the performance on previous tasks, i.e., avoiding the so-called catastrophic forgetting. However, the DNN parameter update in CL-based autonomous systems is extremely resource-hungry. The existing DNN accelerators cannot be directly employed in CL because they only support the execution of the forward propagation. Only a few prior architectures execute the backpropagation and weight update, but they lack the control and management for CL. Towards this, we design a hardware architecture, TinyCL, to perform CL on resource-constrained autonomous systems. It consists of a processing unit that executes both forward and backward propagation, and a control unit that manages memory-based CL workload. To minimize the memory accesses, the sliding window of the convolutional layer moves in a snake-like fashion. Moreover, the Multiply-and-Accumulate units can be reconfigured at runtime to execute different operations. As per our knowledge, our proposed TinyCL represents the first hardware accelerator that executes CL on autonomous systems. We synthesize the complete TinyCL architecture in a 65 nm CMOS technology node with the conventional ASIC design flow. It executes 1 epoch of training on a Conv + ReLU + Dense model on the CIFAR10 dataset in 1.76 s, while 1 training epoch of the same model using an Nvidia Tesla P100 GPU takes 103 s, thus achieving a 58 x speedup, consuming 86 mW in a 4.74 mm2 die.
A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks
Aug 10, 2023Machine learning (ML) is widely used today, especially through deep neural networks (DNNs), however, increasing computational load and resource requirements have led to cloud-based solutions. To address this problem, a new generation of networks called Spiking Neural Networks (SNN) has emerged, which mimic the behavior of the human brain to improve efficiency and reduce energy consumption. These networks often process large amounts of sensitive information, such as confidential data, and thus privacy issues arise. Homomorphic encryption (HE) offers a solution, allowing calculations to be performed on encrypted data without decrypting it. This research compares traditional DNNs and SNNs using the Brakerski/Fan-Vercauteren (BFV) encryption scheme. The LeNet-5 model, a widely-used convolutional architecture, is used for both DNN and SNN models based on the LeNet-5 architecture, and the networks are trained and compared using the FashionMNIST dataset. The results show that SNNs using HE achieve up to 40% higher accuracy than DNNs for low values of the plaintext modulus t, although their execution time is longer due to their time-coding nature with multiple time-steps.
RobCaps: Evaluating the Robustness of Capsule Networks against Affine Transformations and Adversarial Attacks
Apr 25, 2023Capsule Networks (CapsNets) are able to hierarchically preserve the pose relationships between multiple objects for image classification tasks. Other than achieving high accuracy, another relevant factor in deploying CapsNets in safety-critical applications is the robustness against input transformations and malicious adversarial attacks. In this paper, we systematically analyze and evaluate different factors affecting the robustness of CapsNets, compared to traditional Convolutional Neural Networks (CNNs). Towards a comprehensive comparison, we test two CapsNet models and two CNN models on the MNIST, GTSRB, and CIFAR10 datasets, as well as on the affine-transformed versions of such datasets. With a thorough analysis, we show which properties of these architectures better contribute to increasing the robustness and their limitations. Overall, CapsNets achieve better robustness against adversarial examples and affine transformations, compared to a traditional CNN with a similar number of parameters. Similar conclusions have been derived for deeper versions of CapsNets and CNNs. Moreover, our results unleash a key finding that the dynamic routing does not contribute much to improving the CapsNets' robustness. Indeed, the main generalization contribution is due to the hierarchical feature learning through capsules.
SwiftTron: An Efficient Hardware Accelerator for Quantized Transformers
Apr 25, 2023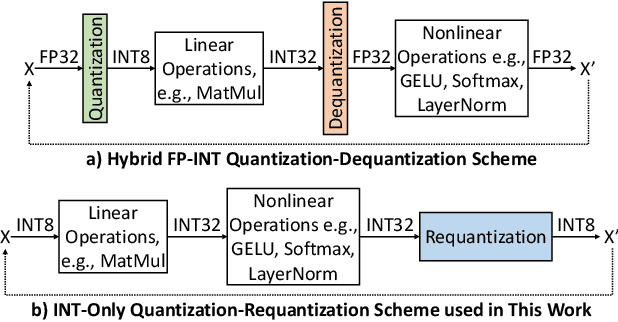
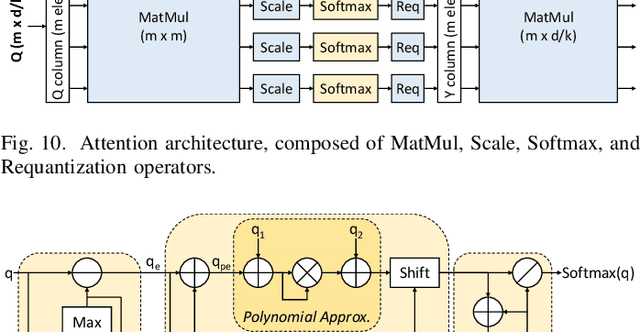
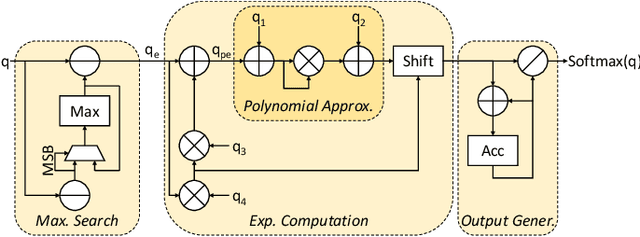

Transformers' compute-intensive operations pose enormous challenges for their deployment in resource-constrained EdgeAI / tinyML devices. As an established neural network compression technique, quantization reduces the hardware computational and memory resources. In particular, fixed-point quantization is desirable to ease the computations using lightweight blocks, like adders and multipliers, of the underlying hardware. However, deploying fully-quantized Transformers on existing general-purpose hardware, generic AI accelerators, or specialized architectures for Transformers with floating-point units might be infeasible and/or inefficient. Towards this, we propose SwiftTron, an efficient specialized hardware accelerator designed for Quantized Transformers. SwiftTron supports the execution of different types of Transformers' operations (like Attention, Softmax, GELU, and Layer Normalization) and accounts for diverse scaling factors to perform correct computations. We synthesize the complete SwiftTron architecture in a $65$ nm CMOS technology with the ASIC design flow. Our Accelerator executes the RoBERTa-base model in 1.83 ns, while consuming 33.64 mW power, and occupying an area of 273 mm^2. To ease the reproducibility, the RTL of our SwiftTron architecture is released at https://github.com/albertomarchisio/SwiftTron.
AccelAT: A Framework for Accelerating the Adversarial Training of Deep Neural Networks through Accuracy Gradient
Oct 13, 2022
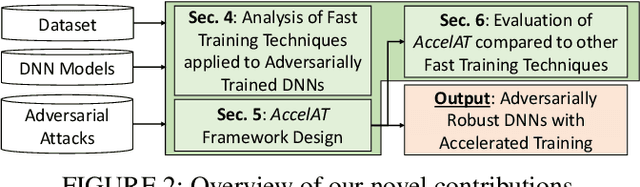

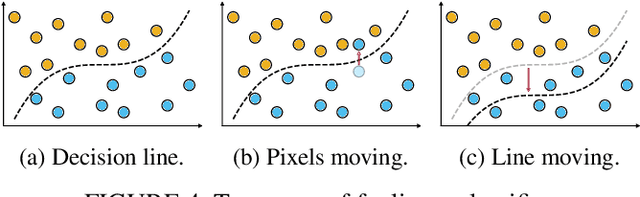
Adversarial training is exploited to develop a robust Deep Neural Network (DNN) model against the malicious altered data. These attacks may have catastrophic effects on DNN models but are indistinguishable for a human being. For example, an external attack can modify an image adding noises invisible for a human eye, but a DNN model misclassified the image. A key objective for developing robust DNN models is to use a learning algorithm that is fast but can also give model that is robust against different types of adversarial attacks. Especially for adversarial training, enormously long training times are needed for obtaining high accuracy under many different types of adversarial samples generated using different adversarial attack techniques. This paper aims at accelerating the adversarial training to enable fast development of robust DNN models against adversarial attacks. The general method for improving the training performance is the hyperparameters fine-tuning, where the learning rate is one of the most crucial hyperparameters. By modifying its shape (the value over time) and value during the training, we can obtain a model robust to adversarial attacks faster than standard training. First, we conduct experiments on two different datasets (CIFAR10, CIFAR100), exploring various techniques. Then, this analysis is leveraged to develop a novel fast training methodology, AccelAT, which automatically adjusts the learning rate for different epochs based on the accuracy gradient. The experiments show comparable results with the related works, and in several experiments, the adversarial training of DNNs using our AccelAT framework is conducted up to 2 times faster than the existing techniques. Thus, our findings boost the speed of adversarial training in an era in which security and performance are fundamental optimization objectives in DNN-based applications.
RoHNAS: A Neural Architecture Search Framework with Conjoint Optimization for Adversarial Robustness and Hardware Efficiency of Convolutional and Capsule Networks
Oct 11, 2022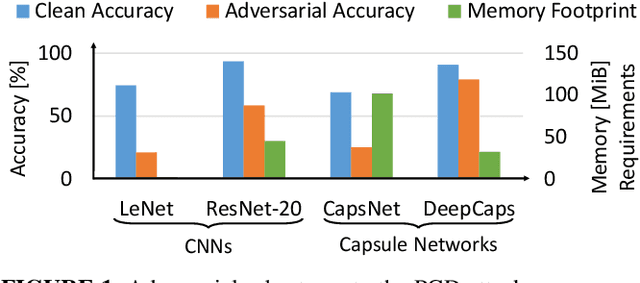


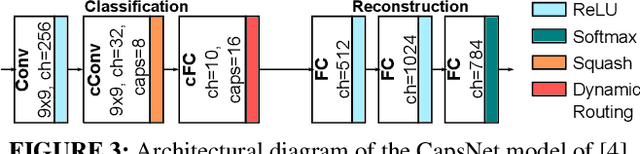
Neural Architecture Search (NAS) algorithms aim at finding efficient Deep Neural Network (DNN) architectures for a given application under given system constraints. DNNs are computationally-complex as well as vulnerable to adversarial attacks. In order to address multiple design objectives, we propose RoHNAS, a novel NAS framework that jointly optimizes for adversarial-robustness and hardware-efficiency of DNNs executed on specialized hardware accelerators. Besides the traditional convolutional DNNs, RoHNAS additionally accounts for complex types of DNNs such as Capsule Networks. For reducing the exploration time, RoHNAS analyzes and selects appropriate values of adversarial perturbation for each dataset to employ in the NAS flow. Extensive evaluations on multi - Graphics Processing Unit (GPU) - High Performance Computing (HPC) nodes provide a set of Pareto-optimal solutions, leveraging the tradeoff between the above-discussed design objectives. For example, a Pareto-optimal DNN for the CIFAR-10 dataset exhibits 86.07% accuracy, while having an energy of 38.63 mJ, a memory footprint of 11.85 MiB, and a latency of 4.47 ms.
LaneSNNs: Spiking Neural Networks for Lane Detection on the Loihi Neuromorphic Processor
Aug 03, 2022


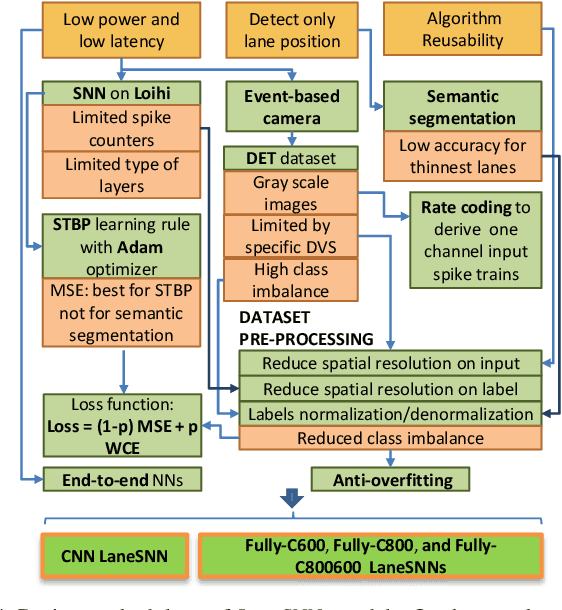
Autonomous Driving (AD) related features represent important elements for the next generation of mobile robots and autonomous vehicles focused on increasingly intelligent, autonomous, and interconnected systems. The applications involving the use of these features must provide, by definition, real-time decisions, and this property is key to avoid catastrophic accidents. Moreover, all the decision processes must require low power consumption, to increase the lifetime and autonomy of battery-driven systems. These challenges can be addressed through efficient implementations of Spiking Neural Networks (SNNs) on Neuromorphic Chips and the use of event-based cameras instead of traditional frame-based cameras. In this paper, we present a new SNN-based approach, called LaneSNN, for detecting the lanes marked on the streets using the event-based camera input. We develop four novel SNN models characterized by low complexity and fast response, and train them using an offline supervised learning rule. Afterward, we implement and map the learned SNNs models onto the Intel Loihi Neuromorphic Research Chip. For the loss function, we develop a novel method based on the linear composition of Weighted binary Cross Entropy (WCE) and Mean Squared Error (MSE) measures. Our experimental results show a maximum Intersection over Union (IoU) measure of about 0.62 and very low power consumption of about 1 W. The best IoU is achieved with an SNN implementation that occupies only 36 neurocores on the Loihi processor while providing a low latency of less than 8 ms to recognize an image, thereby enabling real-time performance. The IoU measures provided by our networks are comparable with the state-of-the-art, but at a much low power consumption of 1 W.
CoNLoCNN: Exploiting Correlation and Non-Uniform Quantization for Energy-Efficient Low-precision Deep Convolutional Neural Networks
Jul 31, 2022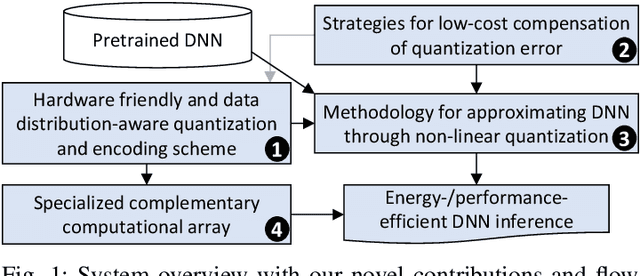



In today's era of smart cyber-physical systems, Deep Neural Networks (DNNs) have become ubiquitous due to their state-of-the-art performance in complex real-world applications. The high computational complexity of these networks, which translates to increased energy consumption, is the foremost obstacle towards deploying large DNNs in resource-constrained systems. Fixed-Point (FP) implementations achieved through post-training quantization are commonly used to curtail the energy consumption of these networks. However, the uniform quantization intervals in FP restrict the bit-width of data structures to large values due to the need to represent most of the numbers with sufficient resolution and avoid high quantization errors. In this paper, we leverage the key insight that (in most of the scenarios) DNN weights and activations are mostly concentrated near zero and only a few of them have large magnitudes. We propose CoNLoCNN, a framework to enable energy-efficient low-precision deep convolutional neural network inference by exploiting: (1) non-uniform quantization of weights enabling simplification of complex multiplication operations; and (2) correlation between activation values enabling partial compensation of quantization errors at low cost without any run-time overheads. To significantly benefit from non-uniform quantization, we also propose a novel data representation format, Encoded Low-Precision Binary Signed Digit, to compress the bit-width of weights while ensuring direct use of the encoded weight for processing using a novel multiply-and-accumulate (MAC) unit design.
Enabling Capsule Networks at the Edge through Approximate Softmax and Squash Operations
Jun 21, 2022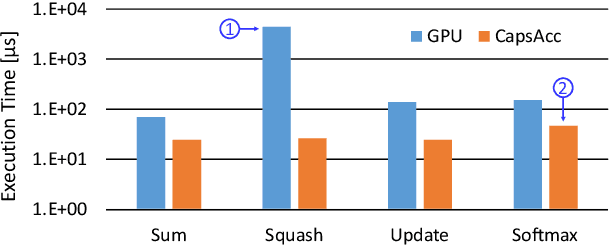
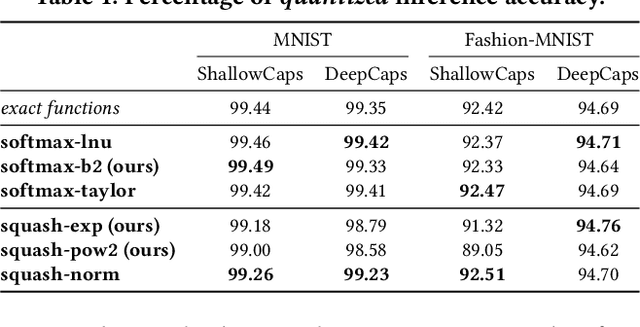
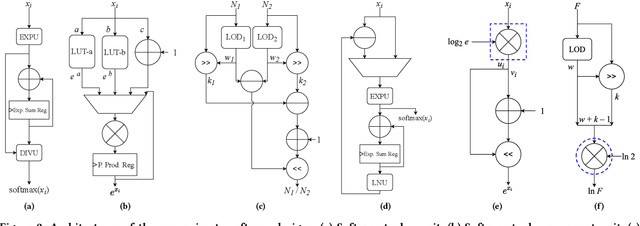
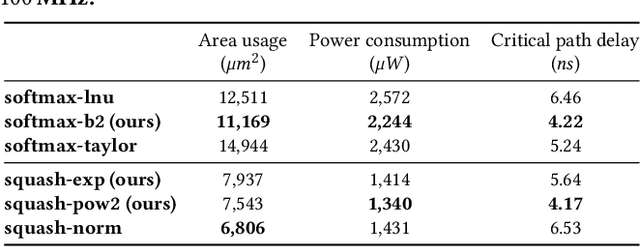
Complex Deep Neural Networks such as Capsule Networks (CapsNets) exhibit high learning capabilities at the cost of compute-intensive operations. To enable their deployment on edge devices, we propose to leverage approximate computing for designing approximate variants of the complex operations like softmax and squash. In our experiments, we evaluate tradeoffs between area, power consumption, and critical path delay of the designs implemented with the ASIC design flow, and the accuracy of the quantized CapsNets, compared to the exact functions.
fakeWeather: Adversarial Attacks for Deep Neural Networks Emulating Weather Conditions on the Camera Lens of Autonomous Systems
May 27, 2022

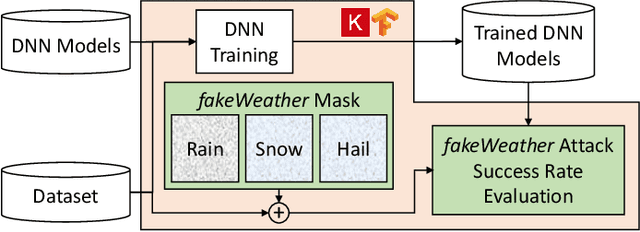

Recently, Deep Neural Networks (DNNs) have achieved remarkable performances in many applications, while several studies have enhanced their vulnerabilities to malicious attacks. In this paper, we emulate the effects of natural weather conditions to introduce plausible perturbations that mislead the DNNs. By observing the effects of such atmospheric perturbations on the camera lenses, we model the patterns to create different masks that fake the effects of rain, snow, and hail. Even though the perturbations introduced by our attacks are visible, their presence remains unnoticed due to their association with natural events, which can be especially catastrophic for fully-autonomous and unmanned vehicles. We test our proposed fakeWeather attacks on multiple Convolutional Neural Network and Capsule Network models, and report noticeable accuracy drops in the presence of such adversarial perturbations. Our work introduces a new security threat for DNNs, which is especially severe for safety-critical applications and autonomous systems.