 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrary Precision Printed Ternary Neural Networks with Holistic Evolutionary Approximation
Aug 27, 2025Printed electronics offer a promising alternative for applications beyond silicon-based systems, requiring properties like flexibility, stretchability, conformality, and ultra-low fabrication costs. Despite the large feature sizes in printed electronics, printed neural networks have attracted attention for meeting target application requirements, though realizing complex circuits remains challenging. This work bridges the gap between classification accuracy and area efficiency in printed neural networks, covering the entire processing-near-sensor system design and co-optimization from the analog-to-digital interface-a major area and power bottleneck-to the digital classifier. We propose an automated framework for designing printed Ternary Neural Networks with arbitrary input precision, utilizing multi-objective optimization and holistic approximation. Our circuits outperform existing approximate printed neural networks by 17x in area and 59x in power on average, being the first to enable printed-battery-powered operation with under 5% accuracy loss while accounting for analog-to-digital interfacing costs.
ApproxDARTS: Differentiable Neural Architecture Search with Approximate Multipliers
Apr 08, 2024
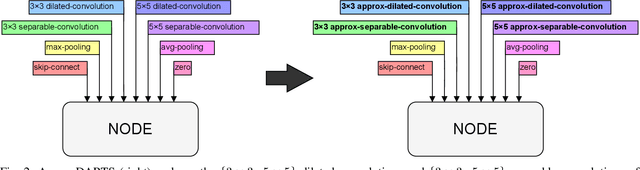


Integrating the principles of approximate computing into the design of hardware-aware deep neural networks (DNN) has led to DNNs implementations showing good output quality and highly optimized hardware parameters such as low latency or inference energy. In this work, we present ApproxDARTS, a neural architecture search (NAS) method enabling the popular differentiable neural architecture search method called DARTS to exploit approximate multipliers and thus reduce the power consumption of generated neural networks. We showed on the CIFAR-10 data set that the ApproxDARTS is able to perform a complete architecture search within less than $10$ GPU hours and produce competitive convolutional neural networks (CNN) containing approximate multipliers in convolutional layers. For example, ApproxDARTS created a CNN showing an energy consumption reduction of (a) $53.84\%$ in the arithmetic operations of the inference phase compared to the CNN utilizing the native $32$-bit floating-point multipliers and (b) $5.97\%$ compared to the CNN utilizing the exact $8$-bit fixed-point multipliers, in both cases with a negligible accuracy drop. Moreover, the ApproxDARTS is $2.3\times$ faster than a similar but evolutionary algorithm-based method called EvoApproxNAS.
Exploring Quantization and Mapping Synergy in Hardware-Aware Deep Neural Network Accelerators
Apr 08, 2024Energy efficiency and memory footprint of a convolutional neural network (CNN) implemented on a CNN inference accelerator depend on many factors, including a weight quantization strategy (i.e., data types and bit-widths) and mapping (i.e., placement and scheduling of DNN elementary operations on hardware units of the accelerator). We show that enabling rich mixed quantization schemes during the implementation can open a previously hidden space of mappings that utilize the hardware resources more effectively. CNNs utilizing quantized weights and activations and suitable mappings can significantly improve trade-offs among the accuracy, energy, and memory requirements compared to less carefully optimized CNN implementations. To find, analyze, and exploit these mappings, we: (i) extend a general-purpose state-of-the-art mapping tool (Timeloop) to support mixed quantization, which is not currently available; (ii) propose an efficient multi-objective optimization algorithm to find the most suitable bit-widths and mapping for each DNN layer executed on the accelerator; and (iii) conduct a detailed experimental evaluation to validate the proposed method. On two CNNs (MobileNetV1 and MobileNetV2) and two accelerators (Eyeriss and Simba) we show that for a given quality metric (such as the accuracy on ImageNet), energy savings are up to 37% without any accuracy drop.
RoHNAS: A Neural Architecture Search Framework with Conjoint Optimization for Adversarial Robustness and Hardware Efficiency of Convolutional and Capsule Networks
Oct 11, 2022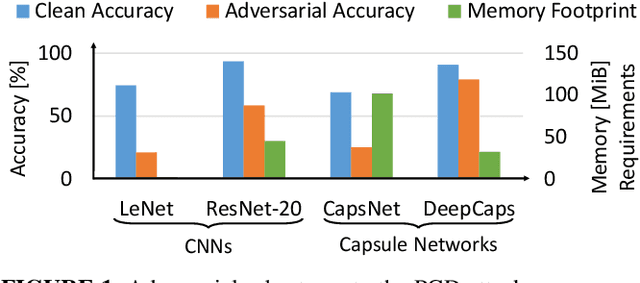


Neural Architecture Search (NAS) algorithms aim at finding efficient Deep Neural Network (DNN) architectures for a given application under given system constraints. DNNs are computationally-complex as well as vulnerable to adversarial attacks. In order to address multiple design objectives, we propose RoHNAS, a novel NAS framework that jointly optimizes for adversarial-robustness and hardware-efficiency of DNNs executed on specialized hardware accelerators. Besides the traditional convolutional DNNs, RoHNAS additionally accounts for complex types of DNNs such as Capsule Networks. For reducing the exploration time, RoHNAS analyzes and selects appropriate values of adversarial perturbation for each dataset to employ in the NAS flow. Extensive evaluations on multi - Graphics Processing Unit (GPU) - High Performance Computing (HPC) nodes provide a set of Pareto-optimal solutions, leveraging the tradeoff between the above-discussed design objectives. For example, a Pareto-optimal DNN for the CIFAR-10 dataset exhibits 86.07% accuracy, while having an energy of 38.63 mJ, a memory footprint of 11.85 MiB, and a latency of 4.47 ms.
Evolutionary Neural Architecture Search Supporting Approximate Multipliers
Jan 28, 2021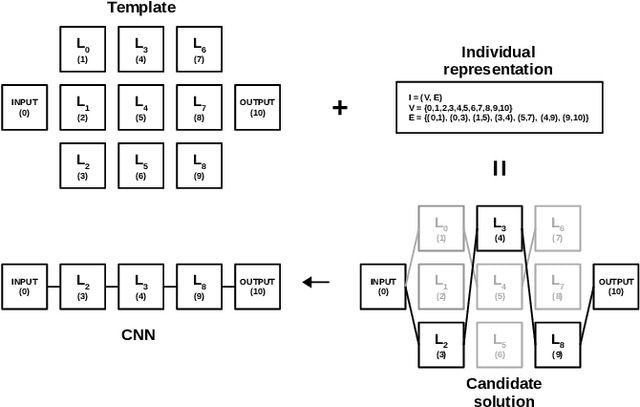
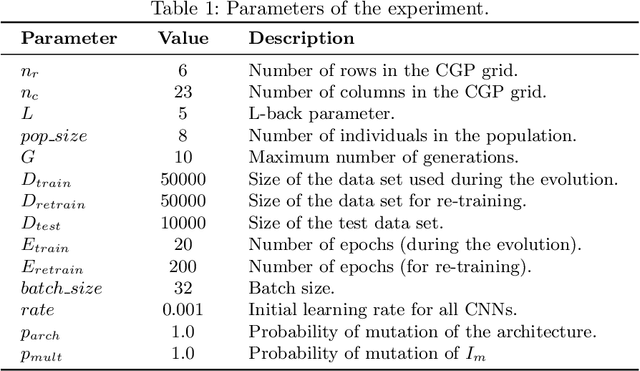
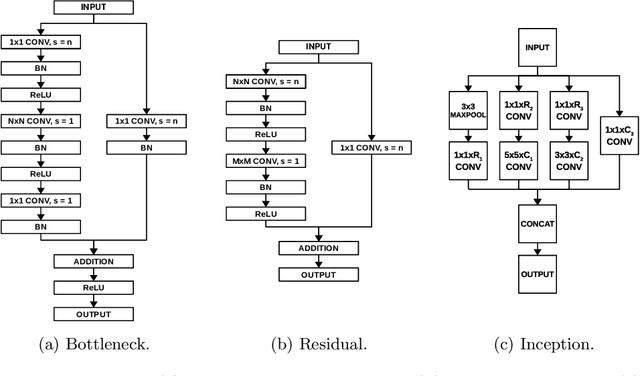
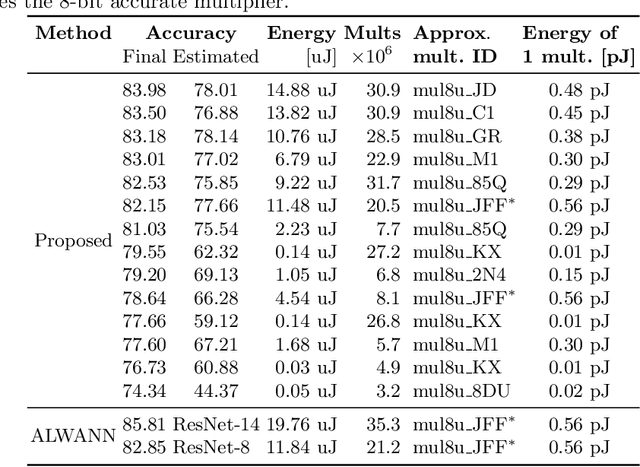
There is a growing interest in automated neural architecture search (NAS) methods. They are employed to routinely deliver high-quality neural network architectures for various challenging data sets and reduce the designer's effort. The NAS methods utilizing multi-objective evolutionary algorithms are especially useful when the objective is not only to minimize the network error but also to minimize the number of parameters (weights) or power consumption of the inference phase. We propose a multi-objective NAS method based on Cartesian genetic programming for evolving convolutional neural networks (CNN). The method allows approximate operations to be used in CNNs to reduce the power consumption of a target hardware implementation. During the NAS process, a suitable CNN architecture is evolved together with approximate multipliers to deliver the best trade-offs between the accuracy, network size, and power consumption. The most suitable approximate multipliers are automatically selected from a library of approximate multipliers. Evolved CNNs are compared with common human-created CNNs of a similar complexity on the CIFAR-10 benchmark problem.
DESCNet: Developing Efficient Scratchpad Memories for Capsule Network Hardware
Oct 12, 2020
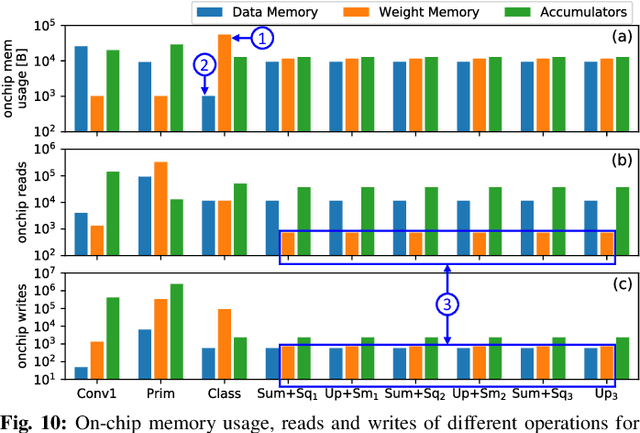
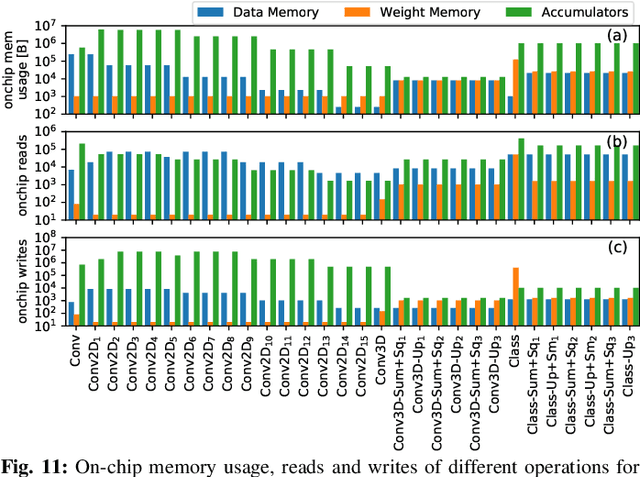
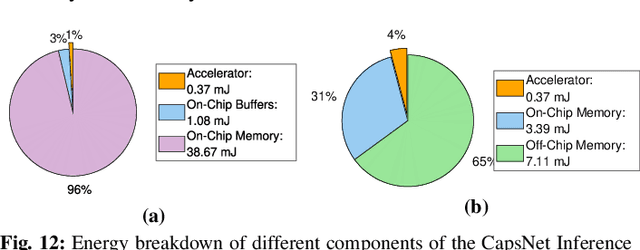
Deep Neural Networks (DNNs) have been established as the state-of-the-art algorithm for advanced machine learning applications. Recently proposed by the Google Brain's team, the Capsule Networks (CapsNets) have improved the generalization ability, as compared to DNNs, due to their multi-dimensional capsules and preserving the spatial relationship between different objects. However, they pose significantly high computational and memory requirements, making their energy-efficient inference a challenging task. This paper provides, for the first time, an in-depth analysis to highlight the design and management related challenges for the (on-chip) memories deployed in hardware accelerators executing fast CapsNets inference. To enable an efficient design, we propose an application-specific memory hierarchy, which minimizes the off-chip memory accesses, while efficiently feeding the data to the hardware accelerator. We analyze the corresponding on-chip memory requirements and leverage it to propose a novel methodology to explore different scratchpad memory designs and their energy/area trade-offs. Afterwards, an application-specific power-gating technique is proposed to further reduce the energy consumption, depending upon the utilization across different operations of the CapsNets. Our results for a selected Pareto-optimal solution demonstrate no performance loss and an energy reduction of 79% for the complete accelerator, including computational units and memories, when compared to a state-of-the-art design executing Google's CapsNet model for the MNIST dataset.
NASCaps: A Framework for Neural Architecture Search to Optimize the Accuracy and Hardware Efficiency of Convolutional Capsule Networks
Aug 19, 2020

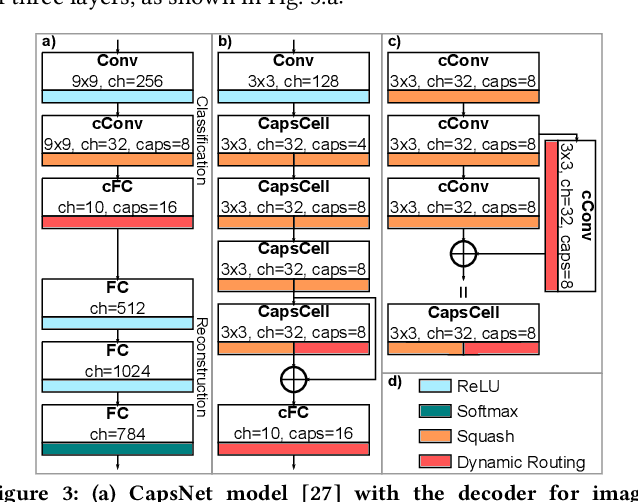
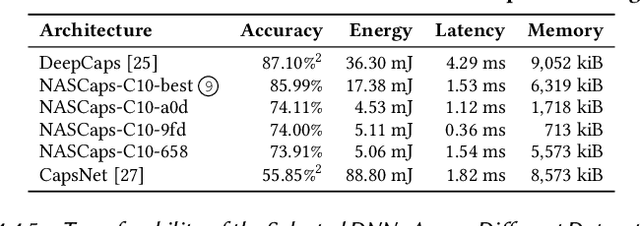
Deep Neural Networks (DNNs) have made significant improvements to reach the desired accuracy to be employed in a wide variety of Machine Learning (ML) applications. Recently the Google Brain's team demonstrated the ability of Capsule Networks (CapsNets) to encode and learn spatial correlations between different input features, thereby obtaining superior learning capabilities compared to traditional (i.e., non-capsule based) DNNs. However, designing CapsNets using conventional methods is a tedious job and incurs significant training effort. Recent studies have shown that powerful methods to automatically select the best/optimal DNN model configuration for a given set of applications and a training dataset are based on the Neural Architecture Search (NAS) algorithms. Moreover, due to their extreme computational and memory requirements, DNNs are employed using the specialized hardware accelerators in IoT-Edge/CPS devices. In this paper, we propose NASCaps, an automated framework for the hardware-aware NAS of different types of DNNs, covering both traditional convolutional DNNs and CapsNets. We study the efficacy of deploying a multi-objective Genetic Algorithm (e.g., based on the NSGA-II algorithm). The proposed framework can jointly optimize the network accuracy and the corresponding hardware efficiency, expressed in terms of energy, memory, and latency of a given hardware accelerator executing the DNN inference. Besides supporting the traditional DNN layers, our framework is the first to model and supports the specialized capsule layers and dynamic routing in the NAS-flow. We evaluate our framework on different datasets, generating different network configurations, and demonstrate the tradeoffs between the different output metrics. We will open-source the complete framework and configurations of the Pareto-optimal architectures at https://github.com/ehw-fit/nascaps.
Semantically-Oriented Mutation Operator in Cartesian Genetic Programming for Evolutionary Circuit Design
Apr 23, 2020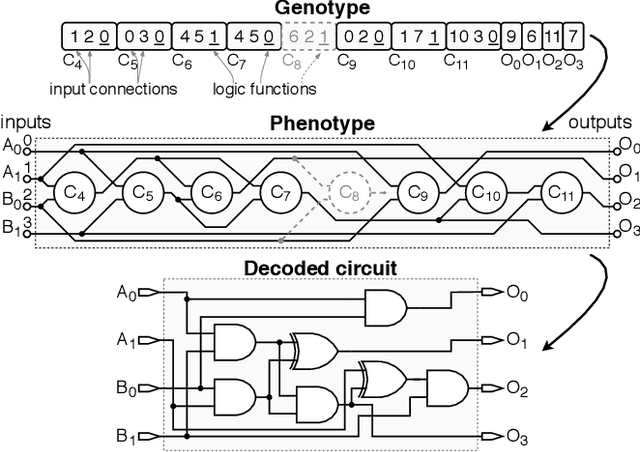


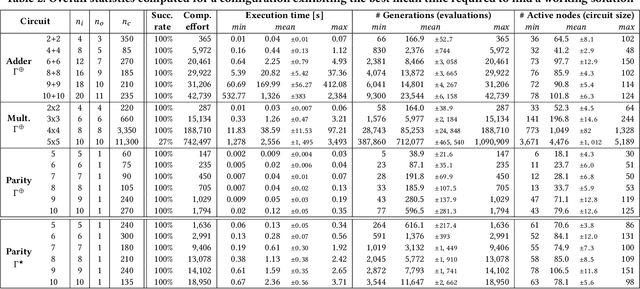
Despite many successful applications, Cartesian Genetic Programming (CGP) suffers from limited scalability, especially when used for evolutionary circuit design. Considering the multiplier design problem, for example, the 5x5-bit multiplier represents the most complex circuit evolved from a randomly generated initial population. The efficiency of CGP highly depends on the performance of the point mutation operator, however, this operator is purely stochastic. This contrasts with the recent developments in Genetic Programming (GP), where advanced informed approaches such as semantic-aware operators are incorporated to improve the search space exploration capability of GP. In this paper, we propose a semantically-oriented mutation operator (SOMO) suitable for the evolutionary design of combinational circuits. SOMO uses semantics to determine the best value for each mutated gene. Compared to the common CGP and its variants as well as the recent versions of Semantic GP, the proposed method converges on common Boolean benchmarks substantially faster while keeping the phenotype size relatively small. The successfully evolved instances presented in this paper include 10-bit parity, 10+10-bit adder and 5x5-bit multiplier. The most complex circuits were evolved in less than one hour with a single-thread implementation running on a common CPU.
Adaptive Verifiability-Driven Strategy for Evolutionary Approximation of Arithmetic Circuits
Mar 05, 2020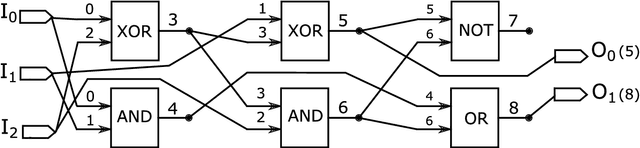

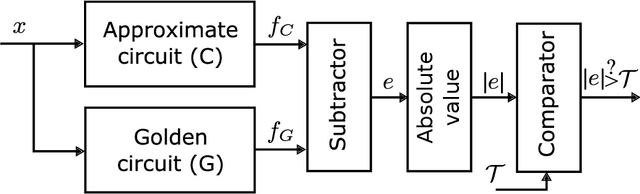
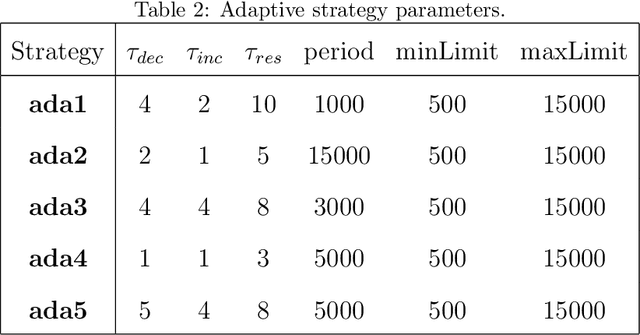
We present a novel approach for designing complex approximate arithmetic circuits that trade correctness for power consumption and play important role in many energy-aware applications. Our approach integrates in a unique way formal methods providing formal guarantees on the approximation error into an evolutionary circuit optimisation algorithm. The key idea is to employ a novel adaptive search strategy that drives the evolution towards promptly verifiable approximate circuits. As demonstrated in an extensive experimental evaluation including several structurally different arithmetic circuits and target precisions, the search strategy provides superior scalability and versatility with respect to various approximation scenarios. Our approach significantly improves capabilities of the existing methods and paves a way towards an automated design process of provably-correct circuit approximations.
TFApprox: Towards a Fast Emulation of DNN Approximate Hardware Accelerators on GPU
Feb 21, 2020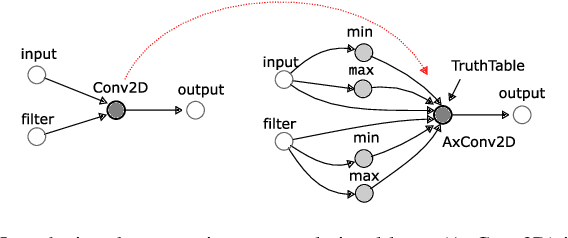
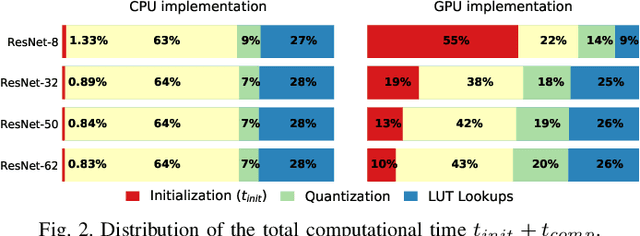
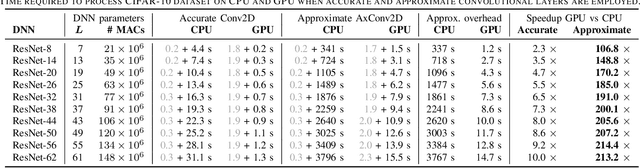
Energy efficiency of hardware accelerators of deep neural networks (DNN) can be improved by introducing approximate arithmetic circuits. In order to quantify the error introduced by using these circuits and avoid the expensive hardware prototyping, a software emulator of the DNN accelerator is usually executed on CPU or GPU. However, this emulation is typically two or three orders of magnitude slower than a software DNN implementation running on CPU or GPU and operating with standard floating point arithmetic instructions and common DNN libraries. The reason is that there is no hardware support for approximate arithmetic operations on common CPUs and GPUs and these operations have to be expensively emulated. In order to address this issue, we propose an efficient emulation method for approximate circuits utilized in a given DNN accelerator which is emulated on GPU. All relevant approximate circuits are implemented as look-up tables and accessed through a texture memory mechanism of CUDA capable GPUs. We exploit the fact that the texture memory is optimized for irregular read-only access and in some GPU architectures is even implemented as a dedicated cache. This technique allowed us to reduce the inference time of the emulated DNN accelerator approximately 200 times with respect to an optimized CPU version on complex DNNs such as ResNet. The proposed approach extends the TensorFlow library and is available online at https://github.com/ehw-fit/tf-approximate.