 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDESCNet: Developing Efficient Scratchpad Memories for Capsule Network Hardware
Paper and Code
Oct 12, 2020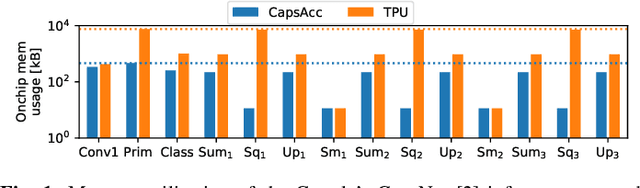
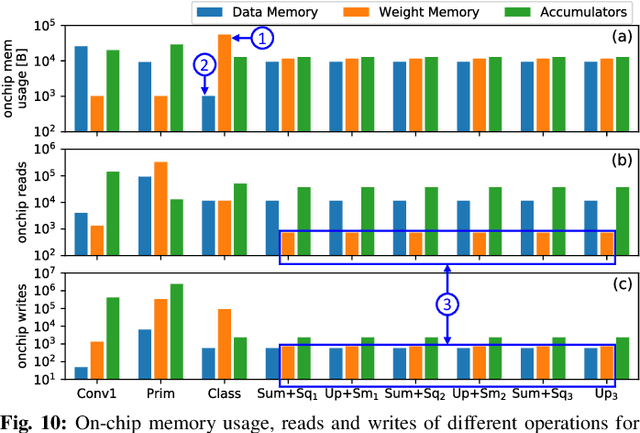
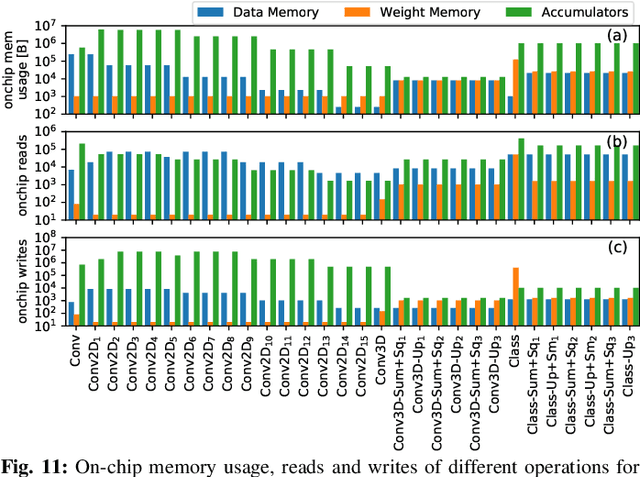
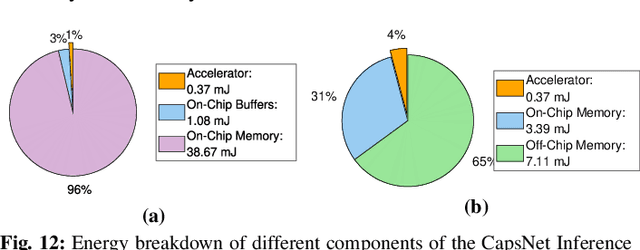
Deep Neural Networks (DNNs) have been established as the state-of-the-art algorithm for advanced machine learning applications. Recently proposed by the Google Brain's team, the Capsule Networks (CapsNets) have improved the generalization ability, as compared to DNNs, due to their multi-dimensional capsules and preserving the spatial relationship between different objects. However, they pose significantly high computational and memory requirements, making their energy-efficient inference a challenging task. This paper provides, for the first time, an in-depth analysis to highlight the design and management related challenges for the (on-chip) memories deployed in hardware accelerators executing fast CapsNets inference. To enable an efficient design, we propose an application-specific memory hierarchy, which minimizes the off-chip memory accesses, while efficiently feeding the data to the hardware accelerator. We analyze the corresponding on-chip memory requirements and leverage it to propose a novel methodology to explore different scratchpad memory designs and their energy/area trade-offs. Afterwards, an application-specific power-gating technique is proposed to further reduce the energy consumption, depending upon the utilization across different operations of the CapsNets. Our results for a selected Pareto-optimal solution demonstrate no performance loss and an energy reduction of 79% for the complete accelerator, including computational units and memories, when compared to a state-of-the-art design executing Google's CapsNet model for the MNIST dataset.