 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproxDARTS: Differentiable Neural Architecture Search with Approximate Multipliers
Apr 08, 2024
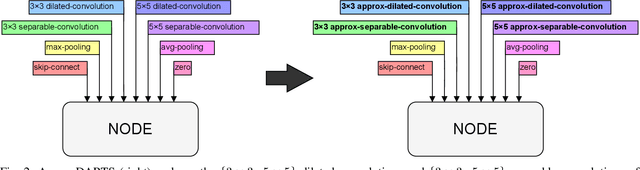


Integrating the principles of approximate computing into the design of hardware-aware deep neural networks (DNN) has led to DNNs implementations showing good output quality and highly optimized hardware parameters such as low latency or inference energy. In this work, we present ApproxDARTS, a neural architecture search (NAS) method enabling the popular differentiable neural architecture search method called DARTS to exploit approximate multipliers and thus reduce the power consumption of generated neural networks. We showed on the CIFAR-10 data set that the ApproxDARTS is able to perform a complete architecture search within less than $10$ GPU hours and produce competitive convolutional neural networks (CNN) containing approximate multipliers in convolutional layers. For example, ApproxDARTS created a CNN showing an energy consumption reduction of (a) $53.84\%$ in the arithmetic operations of the inference phase compared to the CNN utilizing the native $32$-bit floating-point multipliers and (b) $5.97\%$ compared to the CNN utilizing the exact $8$-bit fixed-point multipliers, in both cases with a negligible accuracy drop. Moreover, the ApproxDARTS is $2.3\times$ faster than a similar but evolutionary algorithm-based method called EvoApproxNAS.
Exploring Quantization and Mapping Synergy in Hardware-Aware Deep Neural Network Accelerators
Apr 08, 2024Energy efficiency and memory footprint of a convolutional neural network (CNN) implemented on a CNN inference accelerator depend on many factors, including a weight quantization strategy (i.e., data types and bit-widths) and mapping (i.e., placement and scheduling of DNN elementary operations on hardware units of the accelerator). We show that enabling rich mixed quantization schemes during the implementation can open a previously hidden space of mappings that utilize the hardware resources more effectively. CNNs utilizing quantized weights and activations and suitable mappings can significantly improve trade-offs among the accuracy, energy, and memory requirements compared to less carefully optimized CNN implementations. To find, analyze, and exploit these mappings, we: (i) extend a general-purpose state-of-the-art mapping tool (Timeloop) to support mixed quantization, which is not currently available; (ii) propose an efficient multi-objective optimization algorithm to find the most suitable bit-widths and mapping for each DNN layer executed on the accelerator; and (iii) conduct a detailed experimental evaluation to validate the proposed method. On two CNNs (MobileNetV1 and MobileNetV2) and two accelerators (Eyeriss and Simba) we show that for a given quality metric (such as the accuracy on ImageNet), energy savings are up to 37% without any accuracy drop.
Evolutionary Algorithms in Approximate Computing: A Survey
Aug 16, 2021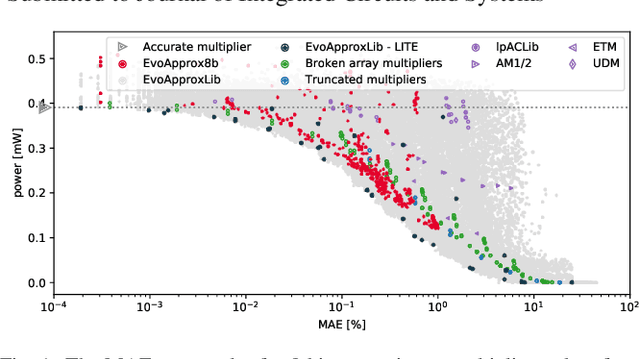


In recent years, many design automation methods have been developed to routinely create approximate implementations of circuits and programs that show excellent trade-offs between the quality of output and required resources. This paper deals with evolutionary approximation as one of the popular approximation methods. The paper provides the first survey of evolutionary algorithm (EA)-based approaches applied in the context of approximate computing. The survey reveals that EAs are primarily applied as multi-objective optimizers. We propose to divide these approaches into two main classes: (i) parameter optimization in which the EA optimizes a vector of system parameters, and (ii) synthesis and optimization in which EA is responsible for determining the architecture and parameters of the resulting system. The evolutionary approximation has been applied at all levels of design abstraction and in many different applications. The neural architecture search enabling the automated hardware-aware design of approximate deep neural networks was identified as a newly emerging topic in this area.
Evolutionary Neural Architecture Search Supporting Approximate Multipliers
Jan 28, 2021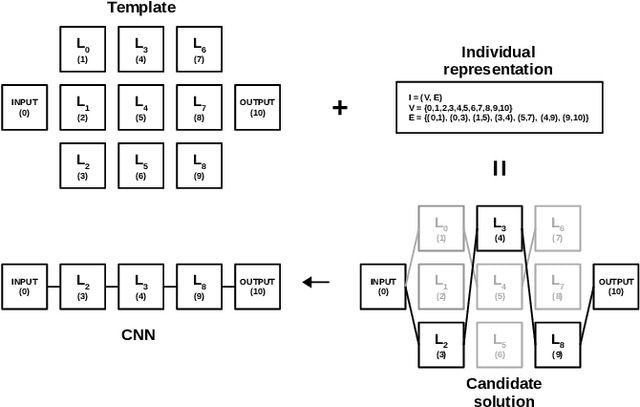
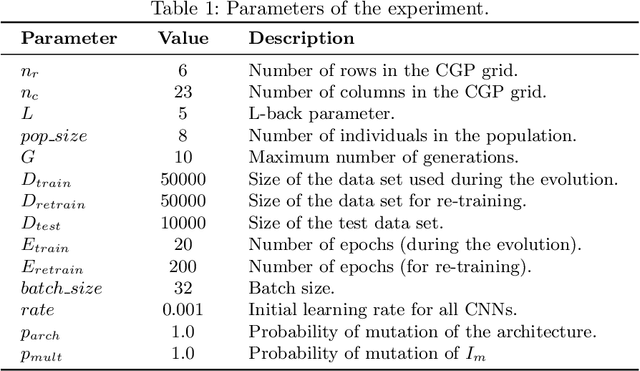
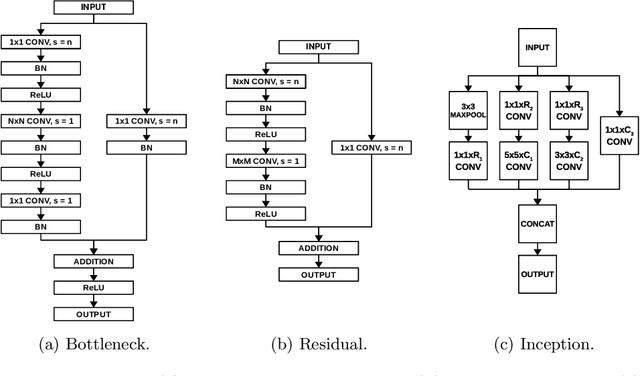
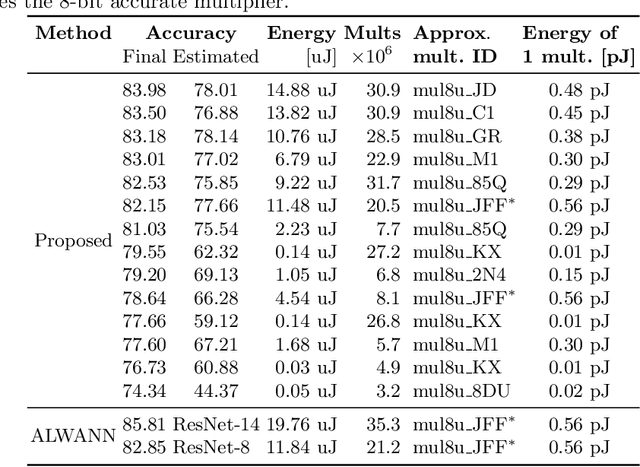
There is a growing interest in automated neural architecture search (NAS) methods. They are employed to routinely deliver high-quality neural network architectures for various challenging data sets and reduce the designer's effort. The NAS methods utilizing multi-objective evolutionary algorithms are especially useful when the objective is not only to minimize the network error but also to minimize the number of parameters (weights) or power consumption of the inference phase. We propose a multi-objective NAS method based on Cartesian genetic programming for evolving convolutional neural networks (CNN). The method allows approximate operations to be used in CNNs to reduce the power consumption of a target hardware implementation. During the NAS process, a suitable CNN architecture is evolved together with approximate multipliers to deliver the best trade-offs between the accuracy, network size, and power consumption. The most suitable approximate multipliers are automatically selected from a library of approximate multipliers. Evolved CNNs are compared with common human-created CNNs of a similar complexity on the CIFAR-10 benchmark problem.
Adaptive Verifiability-Driven Strategy for Evolutionary Approximation of Arithmetic Circuits
Mar 05, 2020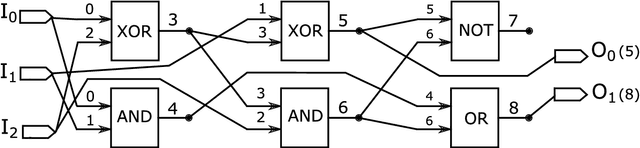

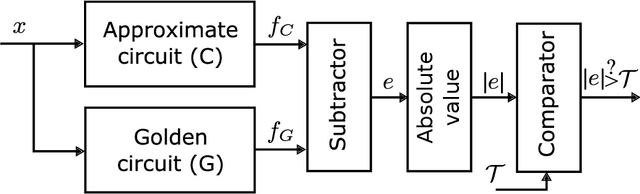
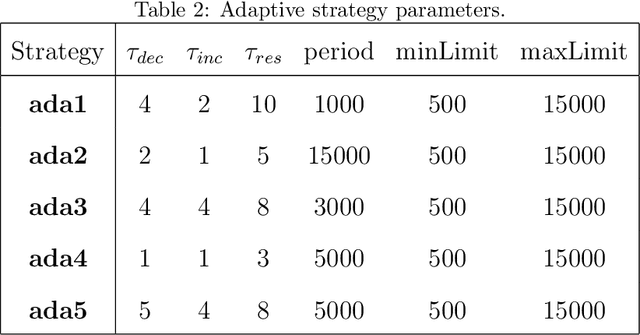
We present a novel approach for designing complex approximate arithmetic circuits that trade correctness for power consumption and play important role in many energy-aware applications. Our approach integrates in a unique way formal methods providing formal guarantees on the approximation error into an evolutionary circuit optimisation algorithm. The key idea is to employ a novel adaptive search strategy that drives the evolution towards promptly verifiable approximate circuits. As demonstrated in an extensive experimental evaluation including several structurally different arithmetic circuits and target precisions, the search strategy provides superior scalability and versatility with respect to various approximation scenarios. Our approach significantly improves capabilities of the existing methods and paves a way towards an automated design process of provably-correct circuit approximations.
TFApprox: Towards a Fast Emulation of DNN Approximate Hardware Accelerators on GPU
Feb 21, 2020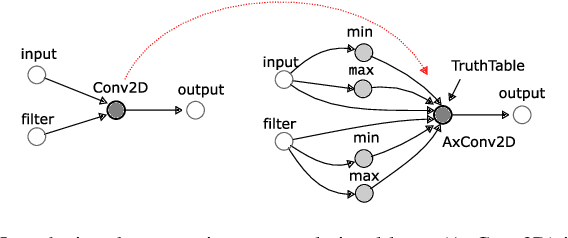
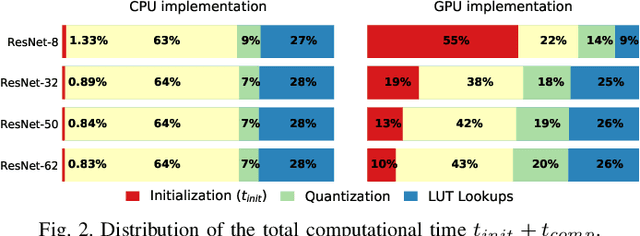
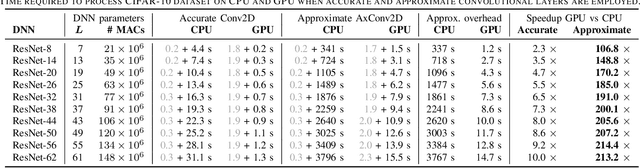
Energy efficiency of hardware accelerators of deep neural networks (DNN) can be improved by introducing approximate arithmetic circuits. In order to quantify the error introduced by using these circuits and avoid the expensive hardware prototyping, a software emulator of the DNN accelerator is usually executed on CPU or GPU. However, this emulation is typically two or three orders of magnitude slower than a software DNN implementation running on CPU or GPU and operating with standard floating point arithmetic instructions and common DNN libraries. The reason is that there is no hardware support for approximate arithmetic operations on common CPUs and GPUs and these operations have to be expensively emulated. In order to address this issue, we propose an efficient emulation method for approximate circuits utilized in a given DNN accelerator which is emulated on GPU. All relevant approximate circuits are implemented as look-up tables and accessed through a texture memory mechanism of CUDA capable GPUs. We exploit the fact that the texture memory is optimized for irregular read-only access and in some GPU architectures is even implemented as a dedicated cache. This technique allowed us to reduce the inference time of the emulated DNN accelerator approximately 200 times with respect to an optimized CPU version on complex DNNs such as ResNet. The proposed approach extends the TensorFlow library and is available online at https://github.com/ehw-fit/tf-approximate.
Optimizing Convolutional Neural Networks for Embedded Systems by Means of Neuroevolution
Oct 15, 2019

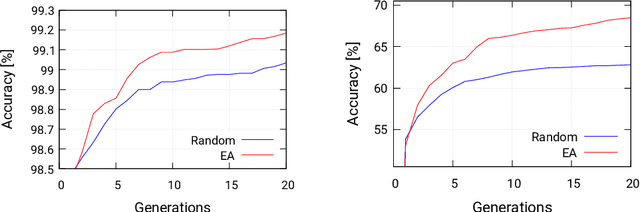

Automated design methods for convolutional neural networks (CNNs) have recently been developed in order to increase the design productivity. We propose a neuroevolution method capable of evolving and optimizing CNNs with respect to the classification error and CNN complexity (expressed as the number of tunable CNN parameters), in which the inference phase can partly be executed using fixed point operations to further reduce power consumption. Experimental results are obtained with TinyDNN framework and presented using two common image classification benchmark problems -- MNIST and CIFAR-10.
ALWANN: Automatic Layer-Wise Approximation of Deep Neural Network Accelerators without Retraining
Jul 25, 2019
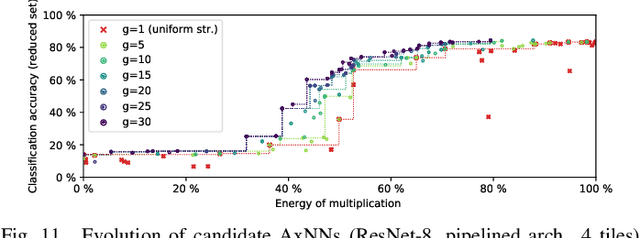
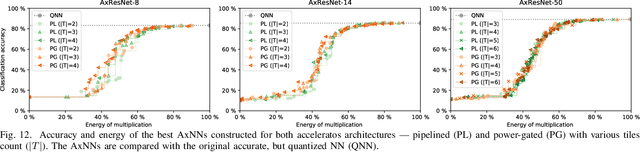

The state-of-the-art approaches employ approximate computing to reduce the energy consumption of DNN hardware. Approximate DNNs then require extensive retraining afterwards to recover from the accuracy loss caused by the use of approximate operations. However, retraining of complex DNNs does not scale well. In this paper, we demonstrate that efficient approximations can be introduced into the computational path of DNN accelerators while retraining can completely be avoided. ALWANN provides highly optimized implementations of DNNs for custom low-power accelerators in which the number of computing units is lower than the number of DNN layers. First, a fully trained DNN is converted to operate with 8-bit weights and 8-bit multipliers in convolutional layers. A suitable approximate multiplier is then selected for each computing element from a library of approximate multipliers in such a way that (i) one approximate multiplier serves several layers, and (ii) the overall classification error and energy consumption are minimized. The optimizations including the multiplier selection problem are solved by means of a multiobjective optimization NSGA-II algorithm. In order to completely avoid the computationally expensive retraining of DNN, which is usually employed to improve the classification accuracy, we propose a simple weight updating scheme that compensates the inaccuracy introduced by employing approximate multipliers. The proposed approach is evaluated for two architectures of DNN accelerators with approximate multipliers from the open-source "EvoApprox" library. We report that the proposed approach saves 30% of energy needed for multiplication in convolutional layers of ResNet-50 while the accuracy is degraded by only 0.6%. The proposed technique and approximate layers are available as an open-source extension of TensorFlow at https://github.com/ehw-fit/tf-approximate.
autoAx: An Automatic Design Space Exploration and Circuit Building Methodology utilizing Libraries of Approximate Components
Apr 01, 2019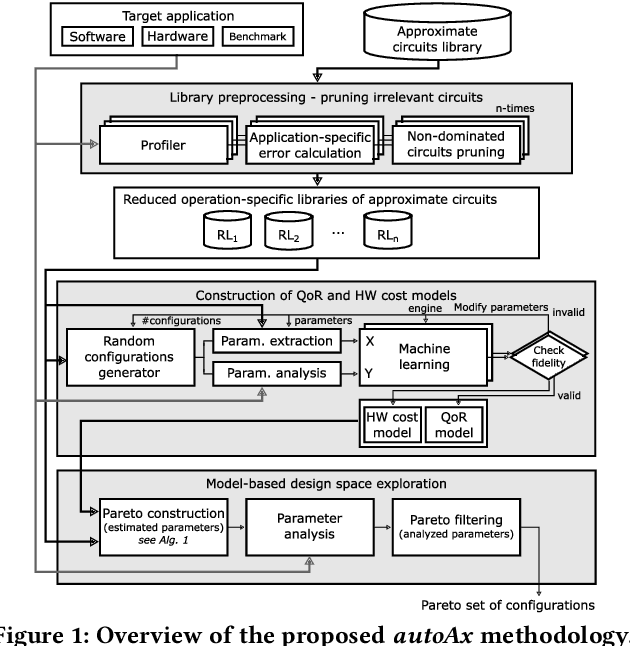


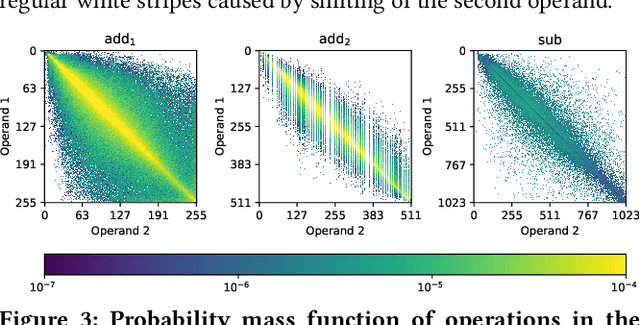
Approximate computing is an emerging paradigm for developing highly energy-efficient computing systems such as various accelerators. In the literature, many libraries of elementary approximate circuits have already been proposed to simplify the design process of approximate accelerators. Because these libraries contain from tens to thousands of approximate implementations for a single arithmetic operation it is intractable to find an optimal combination of approximate circuits in the library even for an application consisting of a few operations. An open problem is "how to effectively combine circuits from these libraries to construct complex approximate accelerators". This paper proposes a novel methodology for searching, selecting and combining the most suitable approximate circuits from a set of available libraries to generate an approximate accelerator for a given application. To enable fast design space generation and exploration, the methodology utilizes machine learning techniques to create computational models estimating the overall quality of processing and hardware cost without performing full synthesis at the accelerator level. Using the methodology, we construct hundreds of approximate accelerators (for a Sobel edge detector) showing different but relevant tradeoffs between the quality of processing and hardware cost and identify a corresponding Pareto-frontier. Furthermore, when searching for approximate implementations of a generic Gaussian filter consisting of 17 arithmetic operations, the proposed approach allows us to identify approximately $10^3$ highly important implementations from $10^{23}$ possible solutions in a few hours, while the exhaustive search would take four months on a high-end processor.
Automated Circuit Approximation Method Driven by Data Distribution
Mar 11, 2019

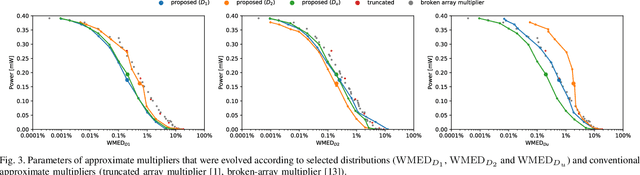

We propose an application-tailored data-driven fully automated method for functional approximation of combinational circuits. We demonstrate how an application-level error metric such as the classification accuracy can be translated to a component-level error metric needed for an efficient and fast search in the space of approximate low-level components that are used in the application. This is possible by employing a weighted mean error distance (WMED) metric for steering the circuit approximation process which is conducted by means of genetic programming. WMED introduces a set of weights (calculated from the data distribution measured on a selected signal in a given application) determining the importance of each input vector for the approximation process. The method is evaluated using synthetic benchmarks and application-specific approximate MAC (multiply-and-accumulate) units that are designed to provide the best trade-offs between the classification accuracy and power consumption of two image classifiers based on neural networks.