 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoHNAS: A Neural Architecture Search Framework with Conjoint Optimization for Adversarial Robustness and Hardware Efficiency of Convolutional and Capsule Networks
Oct 11, 2022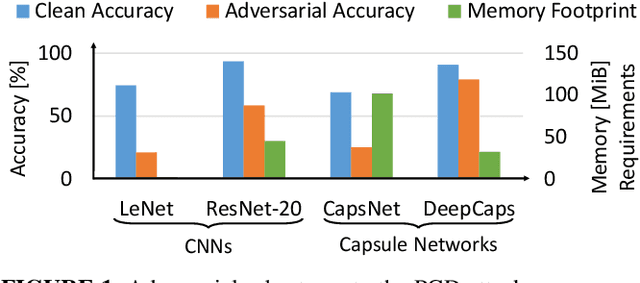


Neural Architecture Search (NAS) algorithms aim at finding efficient Deep Neural Network (DNN) architectures for a given application under given system constraints. DNNs are computationally-complex as well as vulnerable to adversarial attacks. In order to address multiple design objectives, we propose RoHNAS, a novel NAS framework that jointly optimizes for adversarial-robustness and hardware-efficiency of DNNs executed on specialized hardware accelerators. Besides the traditional convolutional DNNs, RoHNAS additionally accounts for complex types of DNNs such as Capsule Networks. For reducing the exploration time, RoHNAS analyzes and selects appropriate values of adversarial perturbation for each dataset to employ in the NAS flow. Extensive evaluations on multi - Graphics Processing Unit (GPU) - High Performance Computing (HPC) nodes provide a set of Pareto-optimal solutions, leveraging the tradeoff between the above-discussed design objectives. For example, a Pareto-optimal DNN for the CIFAR-10 dataset exhibits 86.07% accuracy, while having an energy of 38.63 mJ, a memory footprint of 11.85 MiB, and a latency of 4.47 ms.
Going Further With Winograd Convolutions: Tap-Wise Quantization for Efficient Inference on 4x4 Tile
Sep 26, 2022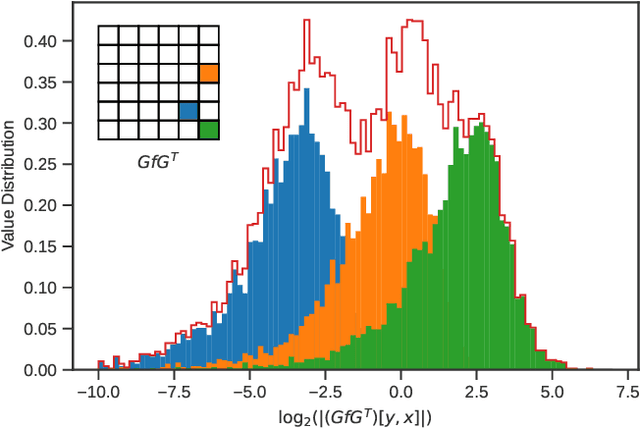

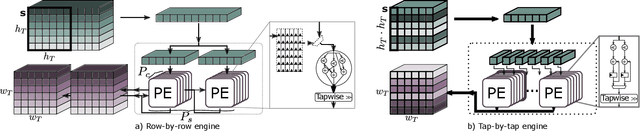
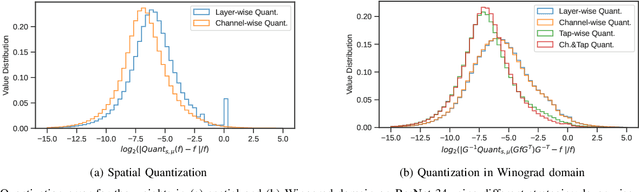
Most of today's computer vision pipelines are built around deep neural networks, where convolution operations require most of the generally high compute effort. The Winograd convolution algorithm computes convolutions with fewer MACs compared to the standard algorithm, reducing the operation count by a factor of 2.25x for 3x3 convolutions when using the version with 2x2-sized tiles $F_2$. Even though the gain is significant, the Winograd algorithm with larger tile sizes, i.e., $F_4$, offers even more potential in improving throughput and energy efficiency, as it reduces the required MACs by 4x. Unfortunately, the Winograd algorithm with larger tile sizes introduces numerical issues that prevent its use on integer domain-specific accelerators and higher computational overhead to transform input and output data between spatial and Winograd domains. To unlock the full potential of Winograd $F_4$, we propose a novel tap-wise quantization method that overcomes the numerical issues of using larger tiles, enabling integer-only inference. Moreover, we present custom hardware units that process the Winograd transformations in a power- and area-efficient way, and we show how to integrate such custom modules in an industrial-grade, programmable DSA. An extensive experimental evaluation on a large set of state-of-the-art computer vision benchmarks reveals that the tap-wise quantization algorithm makes the quantized Winograd $F_4$ network almost as accurate as the FP32 baseline. The Winograd-enhanced DSA achieves up to 1.85x gain in energy efficiency and up to 1.83x end-to-end speed-up for state-of-the-art segmentation and detection networks.
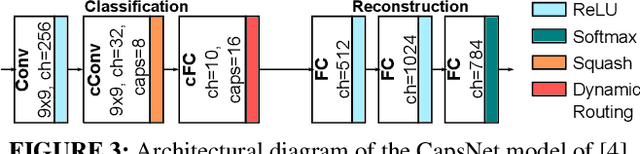
Enabling Capsule Networks at the Edge through Approximate Softmax and Squash Operations
Jun 21, 2022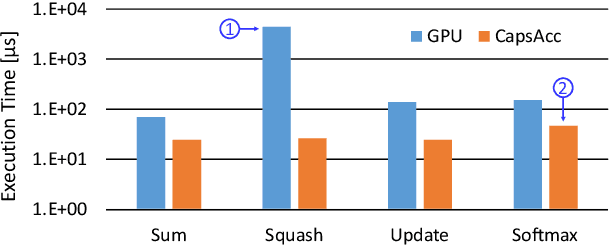
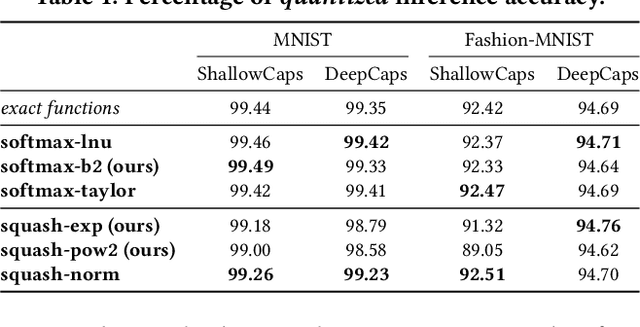
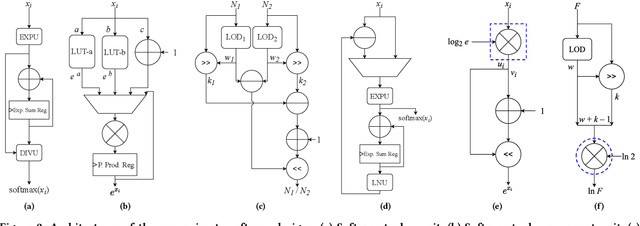
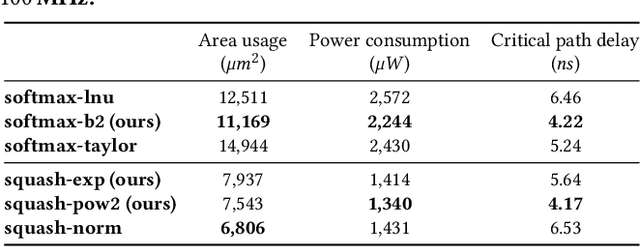
Complex Deep Neural Networks such as Capsule Networks (CapsNets) exhibit high learning capabilities at the cost of compute-intensive operations. To enable their deployment on edge devices, we propose to leverage approximate computing for designing approximate variants of the complex operations like softmax and squash. In our experiments, we evaluate tradeoffs between area, power consumption, and critical path delay of the designs implemented with the ASIC design flow, and the accuracy of the quantized CapsNets, compared to the exact functions.
Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead
Dec 21, 2020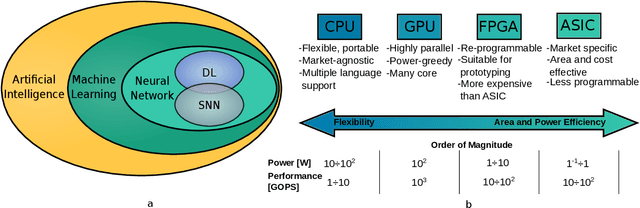


Currently, Machine Learning (ML) is becoming ubiquitous in everyday life. Deep Learning (DL) is already present in many applications ranging from computer vision for medicine to autonomous driving of modern cars as well as other sectors in security, healthcare, and finance. However, to achieve impressive performance, these algorithms employ very deep networks, requiring a significant computational power, both during the training and inference time. A single inference of a DL model may require billions of multiply-and-accumulated operations, making the DL extremely compute- and energy-hungry. In a scenario where several sophisticated algorithms need to be executed with limited energy and low latency, the need for cost-effective hardware platforms capable of implementing energy-efficient DL execution arises. This paper first introduces the key properties of two brain-inspired models like Deep Neural Network (DNN), and Spiking Neural Network (SNN), and then analyzes techniques to produce efficient and high-performance designs. This work summarizes and compares the works for four leading platforms for the execution of algorithms such as CPU, GPU, FPGA and ASIC describing the main solutions of the state-of-the-art, giving much prominence to the last two solutions since they offer greater design flexibility and bear the potential of high energy-efficiency, especially for the inference process. In addition to hardware solutions, this paper discusses some of the important security issues that these DNN and SNN models may have during their execution, and offers a comprehensive section on benchmarking, explaining how to assess the quality of different networks and hardware systems designed for them.
NASCaps: A Framework for Neural Architecture Search to Optimize the Accuracy and Hardware Efficiency of Convolutional Capsule Networks
Aug 19, 2020

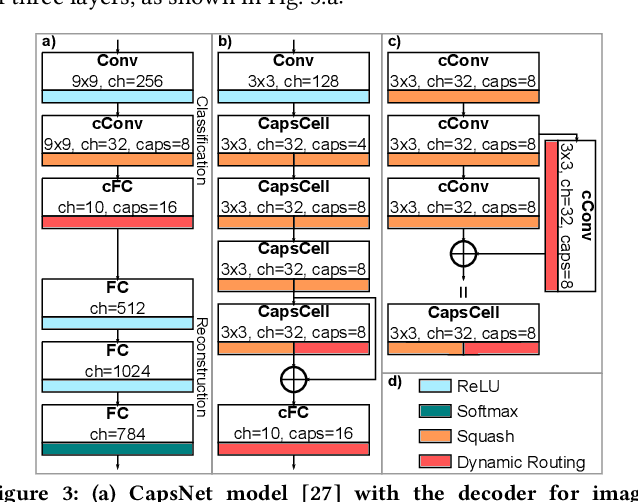
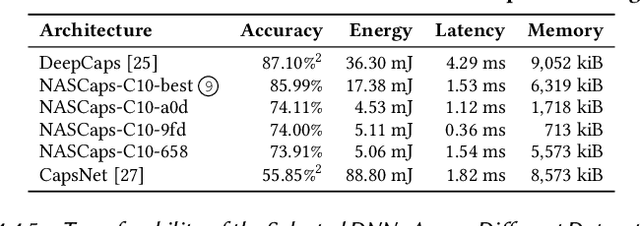
Deep Neural Networks (DNNs) have made significant improvements to reach the desired accuracy to be employed in a wide variety of Machine Learning (ML) applications. Recently the Google Brain's team demonstrated the ability of Capsule Networks (CapsNets) to encode and learn spatial correlations between different input features, thereby obtaining superior learning capabilities compared to traditional (i.e., non-capsule based) DNNs. However, designing CapsNets using conventional methods is a tedious job and incurs significant training effort. Recent studies have shown that powerful methods to automatically select the best/optimal DNN model configuration for a given set of applications and a training dataset are based on the Neural Architecture Search (NAS) algorithms. Moreover, due to their extreme computational and memory requirements, DNNs are employed using the specialized hardware accelerators in IoT-Edge/CPS devices. In this paper, we propose NASCaps, an automated framework for the hardware-aware NAS of different types of DNNs, covering both traditional convolutional DNNs and CapsNets. We study the efficacy of deploying a multi-objective Genetic Algorithm (e.g., based on the NSGA-II algorithm). The proposed framework can jointly optimize the network accuracy and the corresponding hardware efficiency, expressed in terms of energy, memory, and latency of a given hardware accelerator executing the DNN inference. Besides supporting the traditional DNN layers, our framework is the first to model and supports the specialized capsule layers and dynamic routing in the NAS-flow. We evaluate our framework on different datasets, generating different network configurations, and demonstrate the tradeoffs between the different output metrics. We will open-source the complete framework and configurations of the Pareto-optimal architectures at https://github.com/ehw-fit/nascaps.
Q-CapsNets: A Specialized Framework for Quantizing Capsule Networks
Apr 17, 2020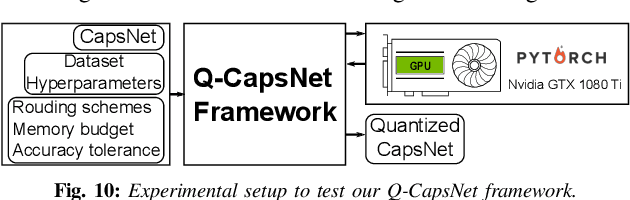
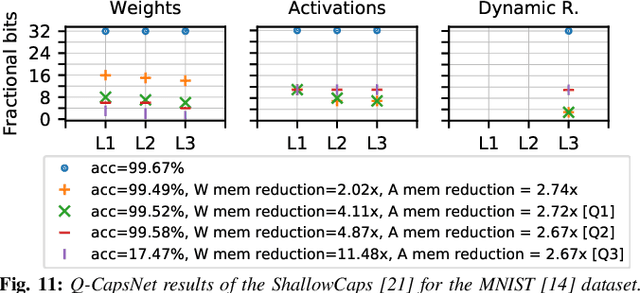
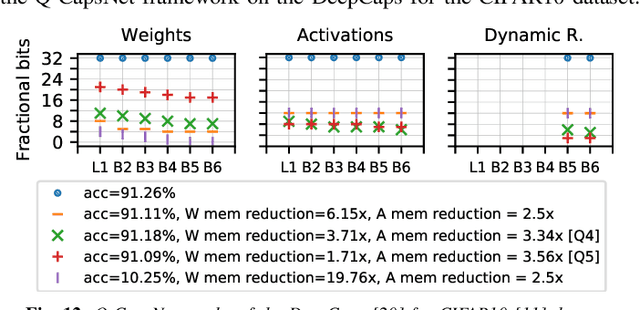
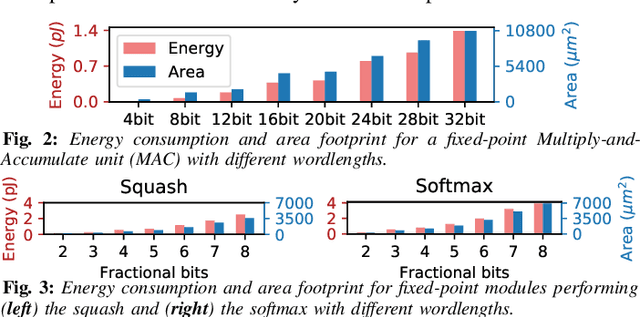
Capsule Networks (CapsNets), recently proposed by the Google Brain team, have superior learning capabilities in machine learning tasks, like image classification, compared to the traditional CNNs. However, CapsNets require extremely intense computations and are difficult to be deployed in their original form at the resource-constrained edge devices. This paper makes the first attempt to quantize CapsNet models, to enable their efficient edge implementations, by developing a specialized quantization framework for CapsNets. We evaluate our framework for several benchmarks. On a deep CapsNet model for the CIFAR10 dataset, the framework reduces the memory footprint by 6.2x, with only 0.15% accuracy loss. We will open-source our framework at https://git.io/JvDIF in August 2020.
X-TrainCaps: Accelerated Training of Capsule Nets through Lightweight Software Optimizations
May 24, 2019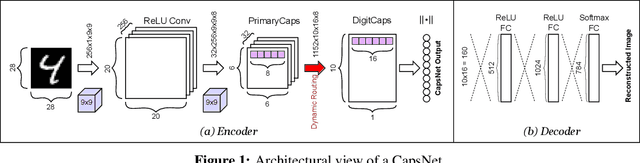
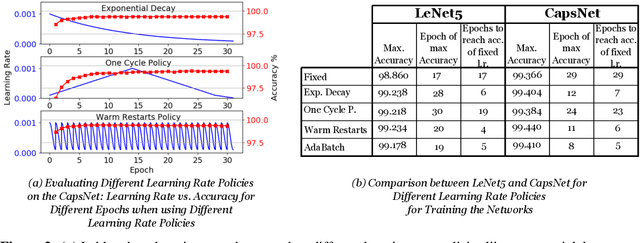
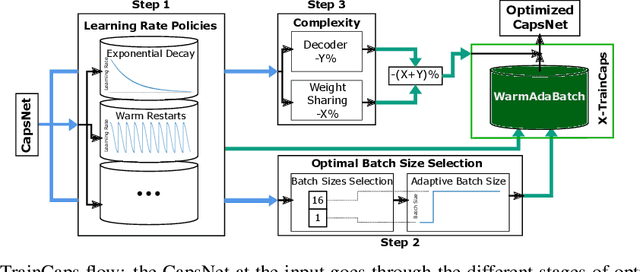
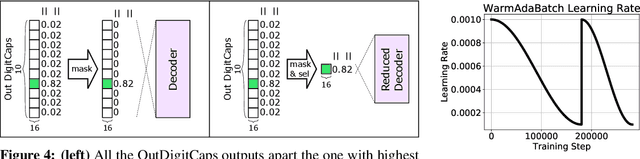
Convolutional Neural Networks (CNNs) are extensively in use due to their excellent results in various machine learning (ML) tasks like image classification and object detection. Recently, Capsule Networks (CapsNets) have shown improved performances compared to the traditional CNNs, by encoding and preserving spatial relationships between the detected features in a better way. This is achieved through the so-called Capsules (i.e., groups of neurons) that encode both the instantiation probability and the spatial information. However, one of the major hurdles in the wide adoption of CapsNets is its gigantic training time, which is primarily due to the relatively higher complexity of its constituting elements. In this paper, we illustrate how can we devise new optimizations in the training process to achieve fast training of CapsNets, and if such optimizations affect the network accuracy or not. Towards this, we propose a novel framework "X-TrainCaps" that employs lightweight software-level optimizations, including a novel learning rate policy called WarmAdaBatch that jointly performs warm restarts and adaptive batch size, as well as weight sharing for capsule layers to reduce the hardware requirements of CapsNets by removing unused/redundant connections and capsules, while keeping high accuracy through tests of different learning rate policies and batch sizes. We demonstrate that one of the solutions generated by X-TrainCaps framework can achieve 58.6% training time reduction while preserving the accuracy (even 0.9% accuracy improvement), compared to the CapsNet in the original paper by Sabour et al. (2017), while other Pareto-optimal solutions can be leveraged to realize trade-offs between training time and achieved accuracy.