 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffQ: Taming Structured Outliers in LLM Quantization by Offsetting
Jun 05, 2026Low-bit quantization has been widely adopted to accelerate the inference of large language models (LLMs) by significantly reducing computational cost and memory usage. However, activation outliers pose a major challenge to effective quantization, often leading to notable performance degradation. In this paper, we introduce OffQ, a method designed to mitigate activation outliers in low-bit quantization through a novel offsetting mechanism. Specifically, OffQ first identifies a low-dimensional outlier subspace in the activations using a proposed top-1 PCA, and then concentrates high-magnitude activations into 1 channel via rotation. OffQ then absorbs this concentrated outlier channel by converting its magnitude into a shared offset, thereby reducing the standard deviation of the activations. This offsetting strategy enables effective W4A4KV4 quantization of LLMs using deployment-friendly uniform-grid and uniform-precision quantization. Extensive experiments across diverse LLM architectures and benchmarks demonstrate that OffQ outperforms state-of-the-art baselines, consistently improving model accuracy while preserving low-bit efficiency.
KVarN: Variance-Normalized KV-Cache Quantization Mitigates Error Accumulation in Reasoning Tasks
Jun 02, 2026Test-time scaling is a powerful approach to obtain better reasoning in large language models, but it becomes memory-bottlenecked during long-horizon decoding, as the KV-cache grows. KV-cache quantization can help improve this, but current methods are evaluated under prefill-like settings and errors behave differently under autoregressive decoding. We show that in the latter regime, quantization errors accumulate across timesteps, driven primarily by incorrect token scales. We introduce KVarN, a calibration-free KV-cache quantizer that applies a Hadamard rotation followed by a dual-scaling variance normalization across both axes of the K and V matrices. We find that this combination fixes outlying token-scale errors and substantially reduces error accumulation over existing baselines. KVarN establishes a new state-of-theart for KV-cache quantization on generative benchmarks, including MATH500, AIME24 and HumanEval, at 2-bit precision. A vLLM implementation of the KVarN method is available at https://github.com/huawei-csl/KVarN
Don't be so Stief! Learning KV Cache low-rank approximation over the Stiefel manifold
Jan 29, 2026Key--value (KV) caching enables fast autoregressive decoding but at long contexts becomes a dominant bottleneck in High Bandwidth Memory (HBM) capacity and bandwidth. A common mitigation is to compress cached keys and values by projecting per-head matrixes to a lower rank, storing only the projections in the HBM. However, existing post-training approaches typically fit these projections using SVD-style proxy objectives, which may poorly reflect end-to-end reconstruction after softmax, value mixing, and subsequent decoder-layer transformations. For these reasons, we introduce StiefAttention, a post-training KV-cache compression method that learns \emph{orthonormal} projection bases by directly minimizing \emph{decoder-layer output reconstruction error}. StiefAttention additionally precomputes, for each layer, an error-rank profile over candidate ranks, enabling flexible layer-wise rank allocation under a user-specified error budget. Noteworthy, on Llama3-8B under the same conditions, StiefAttention outperforms EigenAttention by $11.9$ points on C4 perplexity and $5.4\%$ on 0-shot MMLU accuracy at iso-compression, yielding lower relative error and higher cosine similarity with respect to the original decoder-layer outputs.
Deep Recommender Models Inference: Automatic Asymmetric Data Flow Optimization
Jul 02, 2025Deep Recommender Models (DLRMs) inference is a fundamental AI workload accounting for more than 79% of the total AI workload in Meta's data centers. DLRMs' performance bottleneck is found in the embedding layers, which perform many random memory accesses to retrieve small embedding vectors from tables of various sizes. We propose the design of tailored data flows to speedup embedding look-ups. Namely, we propose four strategies to look up an embedding table effectively on one core, and a framework to automatically map the tables asymmetrically to the multiple cores of a SoC. We assess the effectiveness of our method using the Huawei Ascend AI accelerators, comparing it with the default Ascend compiler, and we perform high-level comparisons with Nvidia A100. Results show a speed-up varying from 1.5x up to 6.5x for real workload distributions, and more than 20x for extremely unbalanced distributions. Furthermore, the method proves to be much more independent of the query distribution than the baseline.
* 5 pages, 4 figures, conference: IEEE ICCD24
AC-LoRA: (Almost) Training-Free Access Control-Aware Multi-Modal LLMs
May 15, 2025



Corporate LLMs are gaining traction for efficient knowledge dissemination and management within organizations. However, as current LLMs are vulnerable to leaking sensitive information, it has proven difficult to apply them in settings where strict access control is necessary. To this end, we design AC-LoRA, an end-to-end system for access control-aware corporate LLM chatbots that maintains a strong information isolation guarantee. AC-LoRA maintains separate LoRA adapters for permissioned datasets, along with the document embedding they are finetuned on. AC-LoRA retrieves a precise set of LoRA adapters based on the similarity score with the user query and their permission. This similarity score is later used to merge the responses if more than one LoRA is retrieved, without requiring any additional training for LoRA routing. We provide an end-to-end prototype of AC-LoRA, evaluate it on two datasets, and show that AC-LoRA matches or even exceeds the performance of state-of-the-art LoRA mixing techniques while providing strong isolation guarantees. Furthermore, we show that AC-LoRA design can be directly applied to different modalities.
Late Breaking Results: The Art of Beating the Odds with Predictor-Guided Random Design Space Exploration
Feb 26, 2025



This work introduces an innovative method for improving combinational digital circuits through random exploration in MIG-based synthesis. High-quality circuits are crucial for performance, power, and cost, making this a critical area of active research. Our approach incorporates next-state prediction and iterative selection, significantly accelerating the synthesis process. This novel method achieves up to 14x synthesis speedup and up to 20.94% better MIG minimization on the EPFL Combinational Benchmark Suite compared to state-of-the-art techniques. We further explore various predictor models and show that increased prediction accuracy does not guarantee an equivalent increase in synthesis quality of results or speedup, observing that randomness remains a desirable factor.
Top-Theta Attention: Sparsifying Transformers by Compensated Thresholding
Feb 12, 2025The attention mechanism is essential for the impressive capabilities of transformer-based Large Language Models (LLMs). However, calculating attention is computationally intensive due to its quadratic dependency on the sequence length. We introduce a novel approach called Top-Theta Attention, or simply Top-$\theta$, which selectively prunes less essential attention elements by comparing them against carefully calibrated thresholds. This method greatly improves the efficiency of self-attention matrix multiplication while preserving model accuracy, reducing the number of required V cache rows by 3x during generative decoding and the number of attention elements by 10x during the prefill phase. Our method does not require model retraining; instead, it requires only a brief calibration phase to be resilient to distribution shifts, thus not requiring the thresholds for different datasets to be recalibrated. Unlike top-k attention, Top-$\theta$ eliminates full-vector dependency, making it suitable for tiling and scale-out and avoiding costly top-k search. A key innovation of our approach is the development of efficient numerical compensation techniques, which help preserve model accuracy even under aggressive pruning of attention scores.
PRESERVE: Prefetching Model Weights and KV-Cache in Distributed LLM Serving
Jan 14, 2025



Large language models (LLMs) are widely used across various applications, but their substantial computational requirements pose significant challenges, particularly in terms of HBM bandwidth bottlenecks and inter-device communication overhead. In this paper, we present PRESERVE, a novel prefetching framework designed to optimize LLM inference by overlapping memory reads for model weights and KV-cache with collective communication operations. Through extensive experiments conducted on commercial AI accelerators, we demonstrate up to 1.6x end-to-end speedup on state-of-the-art, open-source LLMs. Additionally, we perform a design space exploration that identifies the optimal hardware configuration for the proposed method, showing a further 1.25x improvement in performance per cost by selecting the optimal L2 cache size. Our results show that PRESERVE has the potential to mitigate the memory bottlenecks and communication overheads, offering a solution to improve the performance and scalability of the LLM inference systems.
SSSD: Simply-Scalable Speculative Decoding
Nov 08, 2024



Over the past year, Speculative Decoding has gained popularity as a technique for accelerating Large Language Model inference. While several methods have been introduced, most struggle to deliver satisfactory performance at batch sizes typical for data centers ($\geq 8$) and often involve significant deployment complexities. In this work, we offer a theoretical explanation of how Speculative Decoding can be effectively utilized with larger batch sizes. We also introduce a method that integrates seamlessly into existing systems without additional training or the complexity of deploying a small LLM. In a continuous batching setting, we achieve a 4x increase in throughput without any latency impact for short context generation, and a 1.7-2x improvement in both latency and throughput for longer contexts.
On-Device Domain Learning for Keyword Spotting on Low-Power Extreme Edge Embedded Systems
Mar 12, 2024


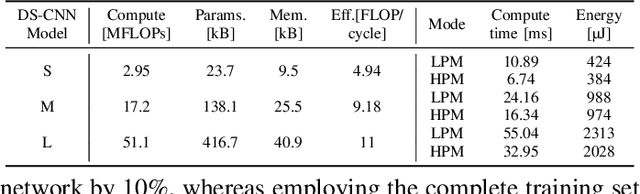
Keyword spotting accuracy degrades when neural networks are exposed to noisy environments. On-site adaptation to previously unseen noise is crucial to recovering accuracy loss, and on-device learning is required to ensure that the adaptation process happens entirely on the edge device. In this work, we propose a fully on-device domain adaptation system achieving up to 14% accuracy gains over already-robust keyword spotting models. We enable on-device learning with less than 10 kB of memory, using only 100 labeled utterances to recover 5% accuracy after adapting to the complex speech noise. We demonstrate that domain adaptation can be achieved on ultra-low-power microcontrollers with as little as 806 mJ in only 14 s on always-on, battery-operated devices.