 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-based Stateful Neural Adaptive Sampling and Denoising for Real-Time Path Tracing
Oct 05, 2023



Monte-Carlo path tracing is a powerful technique for realistic image synthesis but suffers from high levels of noise at low sample counts, limiting its use in real-time applications. To address this, we propose a framework with end-to-end training of a sampling importance network, a latent space encoder network, and a denoiser network. Our approach uses reinforcement learning to optimize the sampling importance network, thus avoiding explicit numerically approximated gradients. Our method does not aggregate the sampled values per pixel by averaging but keeps all sampled values which are then fed into the latent space encoder. The encoder replaces handcrafted spatiotemporal heuristics by learned representations in a latent space. Finally, a neural denoiser is trained to refine the output image. Our approach increases visual quality on several challenging datasets and reduces rendering times for equal quality by a factor of 1.6x compared to the previous state-of-the-art, making it a promising solution for real-time applications.
MAUD: An Expert-Annotated Legal NLP Dataset for Merger Agreement Understanding
Jan 06, 2023Reading comprehension of legal text can be a particularly challenging task due to the length and complexity of legal clauses and a shortage of expert-annotated datasets. To address this challenge, we introduce the Merger Agreement Understanding Dataset (MAUD), an expert-annotated reading comprehension dataset based on the American Bar Association's 2021 Public Target Deal Points Study, with over 39,000 examples and over 47,000 total annotations. Our fine-tuned Transformer baselines show promising results, with models performing well above random on most questions. However, on a large subset of questions, there is still room for significant improvement. As the only expert-annotated merger agreement dataset, MAUD is valuable as a benchmark for both the legal profession and the NLP community.
Genealogical Population-Based Training for Hyperparameter Optimization
Sep 30, 2021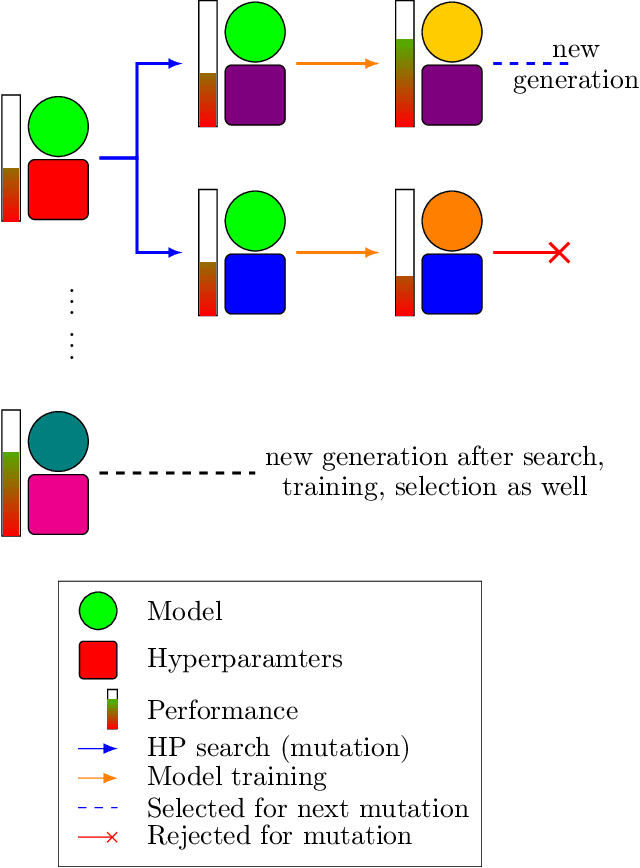
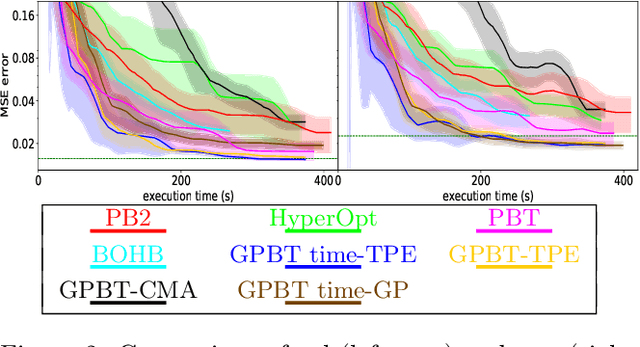
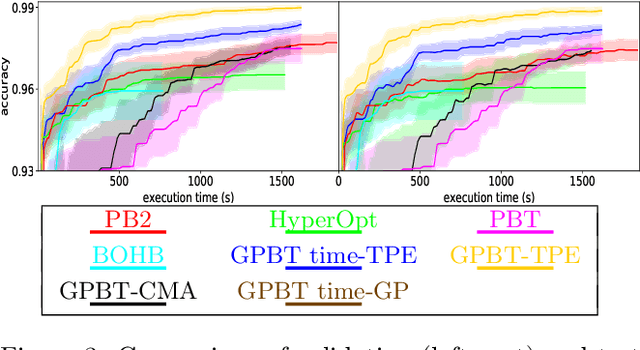
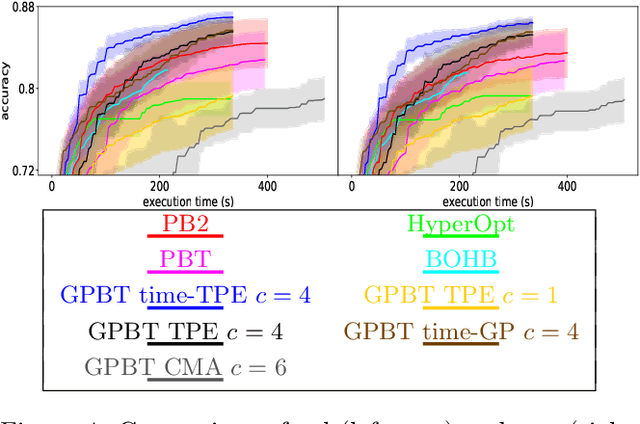
Hyperparameter optimization aims at finding more rapidly and efficiently the best hyperparameters (HPs) of learning models such as neural networks. In this work, we present a new approach called GPBT (Genealogical Population-Based Training), which shares many points with Population-Based Training: our approach outputs a schedule of HPs and updates both weights and HPs in a single run, but brings several novel contributions: the choice of new HPs is made by a modular search algorithm, the search algorithm can search HPs independently for models with different weights and can exploit separately the maximum amount of meaningful information (genealogically-related) from previous HPs evaluations instead of exploiting together all previous HPs evaluations, a variation of early stopping allows a 2-3 fold acceleration at small performance cost. GPBT significantly outperforms all other approaches of HP Optimization, on all supervised learning experiments tested in terms of speed and performances. HPs tuning will become less computationally expensive using our approach, not only in the deep learning field, but potentially for all processes based on iterative optimization.