 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility Engineering: Analyzing and Controlling Emergent Value Systems in AIs
Feb 12, 2025As AIs rapidly advance and become more agentic, the risk they pose is governed not only by their capabilities but increasingly by their propensities, including goals and values. Tracking the emergence of goals and values has proven a longstanding problem, and despite much interest over the years it remains unclear whether current AIs have meaningful values. We propose a solution to this problem, leveraging the framework of utility functions to study the internal coherence of AI preferences. Surprisingly, we find that independently-sampled preferences in current LLMs exhibit high degrees of structural coherence, and moreover that this emerges with scale. These findings suggest that value systems emerge in LLMs in a meaningful sense, a finding with broad implications. To study these emergent value systems, we propose utility engineering as a research agenda, comprising both the analysis and control of AI utilities. We uncover problematic and often shocking values in LLM assistants despite existing control measures. These include cases where AIs value themselves over humans and are anti-aligned with specific individuals. To constrain these emergent value systems, we propose methods of utility control. As a case study, we show how aligning utilities with a citizen assembly reduces political biases and generalizes to new scenarios. Whether we like it or not, value systems have already emerged in AIs, and much work remains to fully understand and control these emergent representations.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
MAUD: An Expert-Annotated Legal NLP Dataset for Merger Agreement Understanding
Jan 06, 2023Reading comprehension of legal text can be a particularly challenging task due to the length and complexity of legal clauses and a shortage of expert-annotated datasets. To address this challenge, we introduce the Merger Agreement Understanding Dataset (MAUD), an expert-annotated reading comprehension dataset based on the American Bar Association's 2021 Public Target Deal Points Study, with over 39,000 examples and over 47,000 total annotations. Our fine-tuned Transformer baselines show promising results, with models performing well above random on most questions. However, on a large subset of questions, there is still room for significant improvement. As the only expert-annotated merger agreement dataset, MAUD is valuable as a benchmark for both the legal profession and the NLP community.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Temperature as Uncertainty in Contrastive Learning
Oct 08, 2021
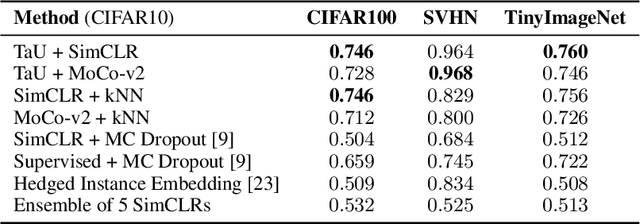


Contrastive learning has demonstrated great capability to learn representations without annotations, even outperforming supervised baselines. However, it still lacks important properties useful for real-world application, one of which is uncertainty. In this paper, we propose a simple way to generate uncertainty scores for many contrastive methods by re-purposing temperature, a mysterious hyperparameter used for scaling. By observing that temperature controls how sensitive the objective is to specific embedding locations, we aim to learn temperature as an input-dependent variable, treating it as a measure of embedding confidence. We call this approach "Temperature as Uncertainty", or TaU. Through experiments, we demonstrate that TaU is useful for out-of-distribution detection, while remaining competitive with benchmarks on linear evaluation. Moreover, we show that TaU can be learned on top of pretrained models, enabling uncertainty scores to be generated post-hoc with popular off-the-shelf models. In summary, TaU is a simple yet versatile method for generating uncertainties for contrastive learning. Open source code can be found at: https://github.com/mhw32/temperature-as-uncertainty-public.
Optimal Transport Based Generative Autoencoders
Oct 16, 2019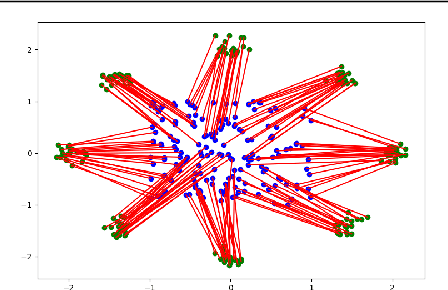
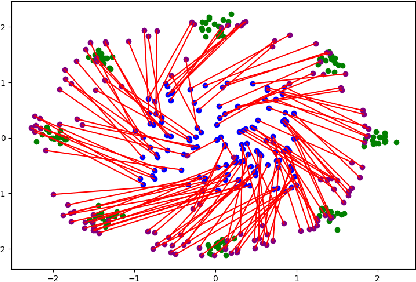
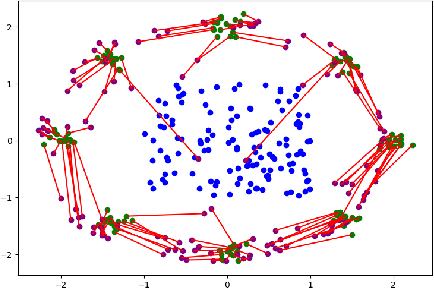

The field of deep generative modeling is dominated by generative adversarial networks (GANs). However, the training of GANs often lacks stability, fails to converge, and suffers from model collapse. It takes an assortment of tricks to solve these problems, which may be difficult to understand for those seeking to apply generative modeling. Instead, we propose two novel generative autoencoders, AE-OTtrans and AE-OTgen, which rely on optimal transport instead of adversarial training. AE-OTtrans and AEOTgen, unlike VAE and WAE, preserve the manifold of the data; they do not force the latent distribution to match a normal distribution, resulting in greater quality images. AEOTtrans and AE-OTgen also produce images of higher diversity compared to their predecessor, AE-OT. We show that AE-OTtrans and AE-OTgen surpass GANs in the MNIST and FashionMNIST datasets. Furthermore, We show that AE-OTtrans and AE-OTgen do state of the art on the MNIST, FashionMNIST, and CelebA image sets comapred to other non-adversarial generative models.