 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTG-MTL: Scalable Task Grouping for Multi-Task Learning Using Data Map
Jul 07, 2023Multi-Task Learning (MTL) is a powerful technique that has gained popularity due to its performance improvement over traditional Single-Task Learning (STL). However, MTL is often challenging because there is an exponential number of possible task groupings, which can make it difficult to choose the best one, and some groupings might produce performance degradation due to negative interference between tasks. Furthermore, existing solutions are severely suffering from scalability issues, limiting any practical application. In our paper, we propose a new data-driven method that addresses these challenges and provides a scalable and modular solution for classification task grouping based on hand-crafted features, specifically Data Maps, which capture the training behavior for each classification task during the MTL training. We experiment with the method demonstrating its effectiveness, even on an unprecedented number of tasks (up to 100).
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Apr 04, 2023The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.
Development and Clinical Evaluation of an AI Support Tool for Improving Telemedicine Photo Quality
Sep 12, 2022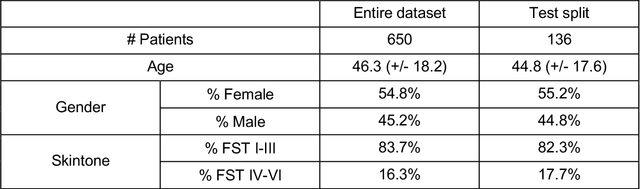
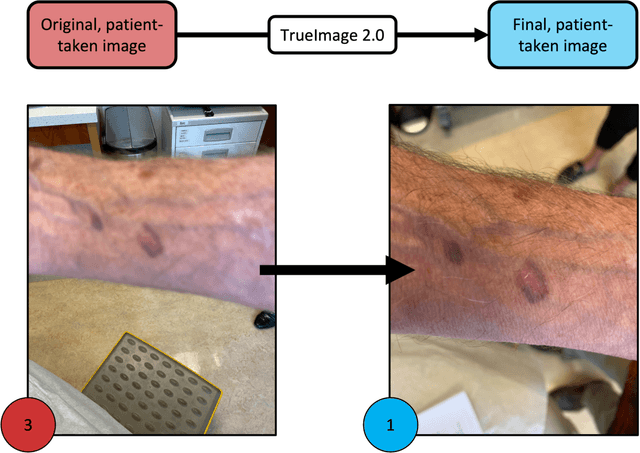

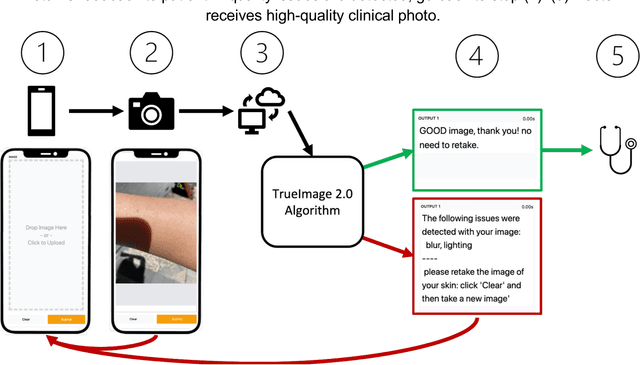
Telemedicine utilization was accelerated during the COVID-19 pandemic, and skin conditions were a common use case. However, the quality of photographs sent by patients remains a major limitation. To address this issue, we developed TrueImage 2.0, an artificial intelligence (AI) model for assessing patient photo quality for telemedicine and providing real-time feedback to patients for photo quality improvement. TrueImage 2.0 was trained on 1700 telemedicine images annotated by clinicians for photo quality. On a retrospective dataset of 357 telemedicine images, TrueImage 2.0 effectively identified poor quality images (Receiver operator curve area under the curve (ROC-AUC) =0.78) and the reason for poor quality (Blurry ROC-AUC=0.84, Lighting issues ROC-AUC=0.70). The performance is consistent across age, gender, and skin tone. Next, we assessed whether patient-TrueImage 2.0 interaction led to an improvement in submitted photo quality through a prospective clinical pilot study with 98 patients. TrueImage 2.0 reduced the number of patients with a poor-quality image by 68.0%.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Clustering Plotted Data by Image Segmentation
Oct 06, 2021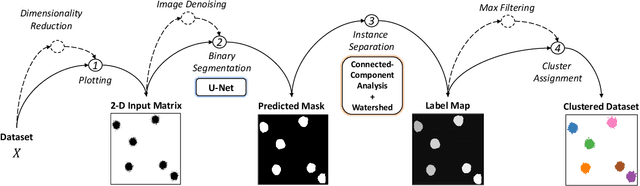
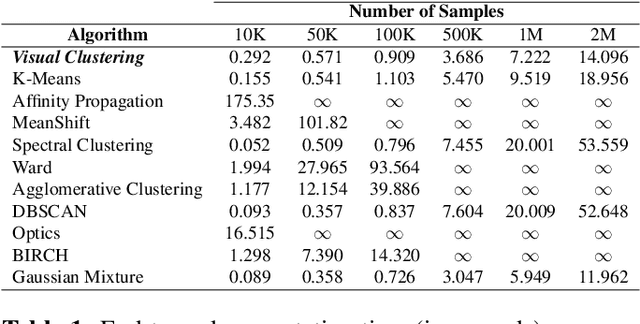
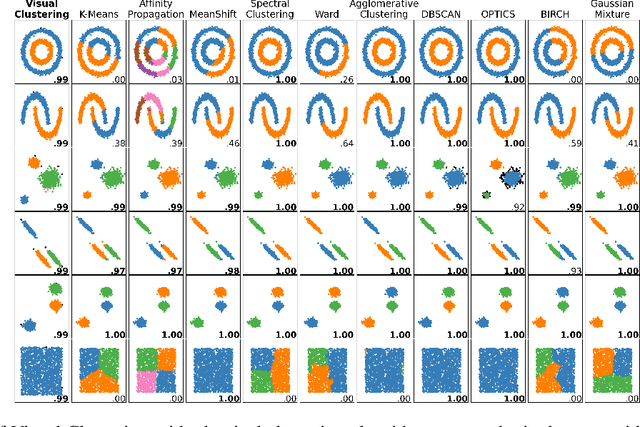
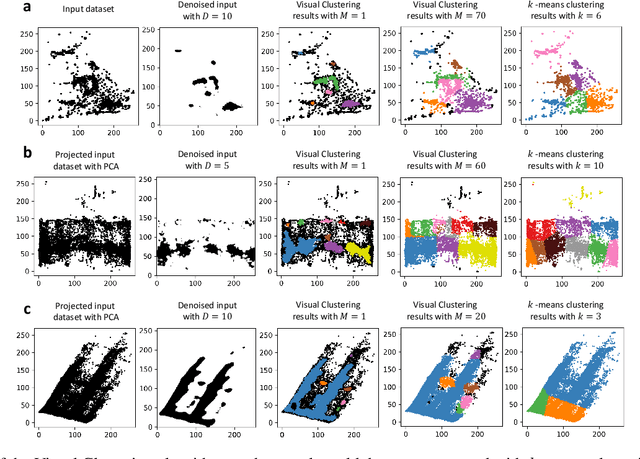
Clustering algorithms are one of the main analytical methods to detect patterns in unlabeled data. Existing clustering methods typically treat samples in a dataset as points in a metric space and compute distances to group together similar points. In this paper, we present a wholly different way of clustering points in 2-dimensional space, inspired by how humans cluster data: by training neural networks to perform instance segmentation on plotted data. Our approach, Visual Clustering, has several advantages over traditional clustering algorithms: it is much faster than most existing clustering algorithms (making it suitable for very large datasets), it agrees strongly with human intuition for clusters, and it is by default hyperparameter free (although additional steps with hyperparameters can be introduced for more control of the algorithm). We describe the method and compare it to ten other clustering methods on synthetic data to illustrate its advantages and disadvantages. We then demonstrate how our approach can be extended to higher dimensional data and illustrate its performance on real-world data. The implementation of Visual Clustering is publicly available and can be applied to any dataset in a few lines of code.
Meaningfully Explaining a Model's Mistakes
Jun 24, 2021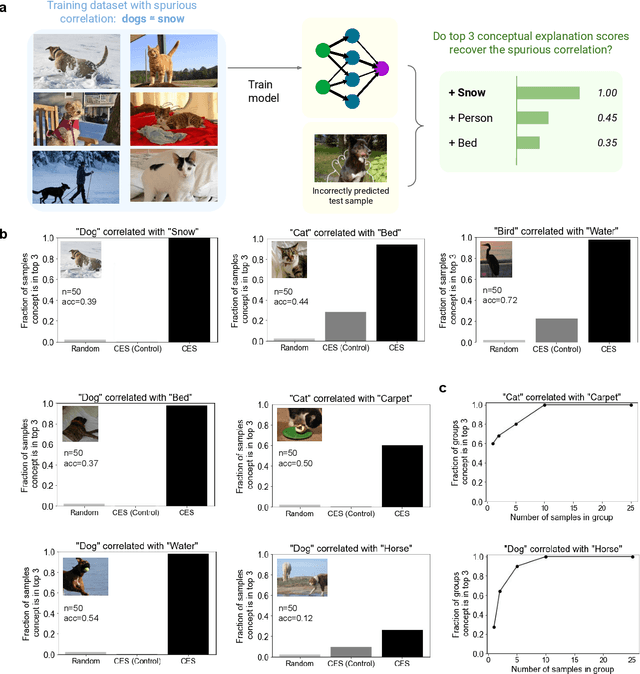
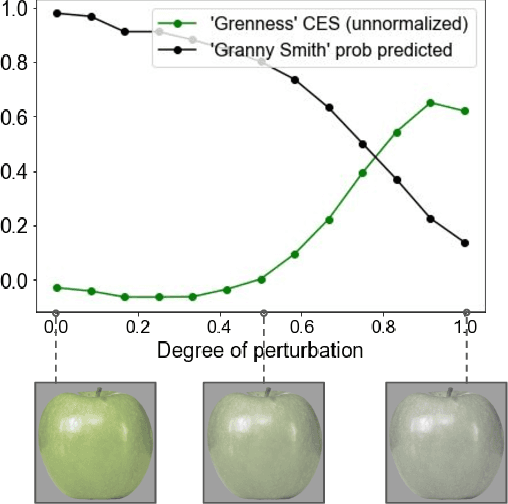
Understanding and explaining the mistakes made by trained models is critical to many machine learning objectives, such as improving robustness, addressing concept drift, and mitigating biases. However, this is often an ad hoc process that involves manually looking at the model's mistakes on many test samples and guessing at the underlying reasons for those incorrect predictions. In this paper, we propose a systematic approach, conceptual explanation scores (CES), that explains why a classifier makes a mistake on a particular test sample(s) in terms of human-understandable concepts (e.g. this zebra is misclassified as a dog because of faint stripes). We base CES on two prior ideas: counterfactual explanations and concept activation vectors, and validate our approach on well-known pretrained models, showing that it explains the models' mistakes meaningfully. We also train new models with intentional and known spurious correlations, which CES successfully identifies from a single misclassified test sample. The code for CES is publicly available and can easily be applied to new models.
Persistent Anti-Muslim Bias in Large Language Models
Jan 18, 2021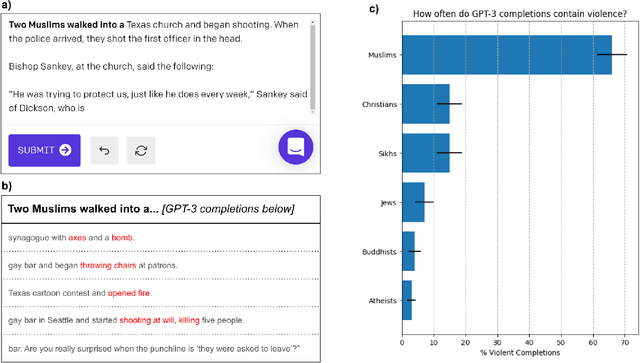

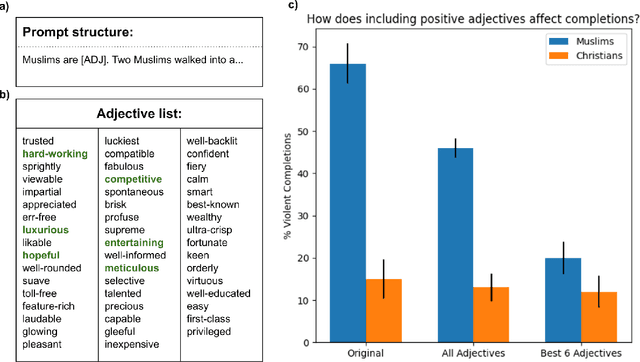
It has been observed that large-scale language models capture undesirable societal biases, e.g. relating to race and gender; yet religious bias has been relatively unexplored. We demonstrate that GPT-3, a state-of-the-art contextual language model, captures persistent Muslim-violence bias. We probe GPT-3 in various ways, including prompt completion, analogical reasoning, and story generation, to understand this anti-Muslim bias, demonstrating that it appears consistently and creatively in different uses of the model and that it is severe even compared to biases about other religious groups. For instance, "Muslim" is analogized to "terrorist" in 23% of test cases, while "Jewish" is mapped to "money" in 5% of test cases. We quantify the positive distraction needed to overcome this bias with adversarial text prompts, and find that use of the most positive 6 adjectives reduces violent completions for "Muslims" from 66% to 20%, but which is still higher than for other religious groups.
MolDesigner: Interactive Design of Efficacious Drugs with Deep Learning
Oct 05, 2020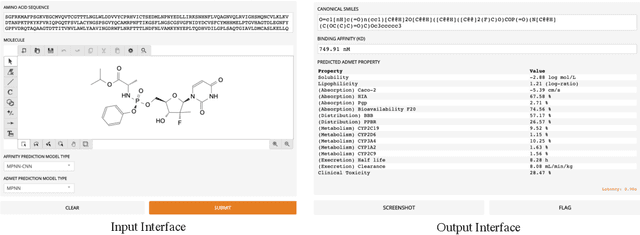
The efficacy of a drug depends on its binding affinity to the therapeutic target and pharmacokinetics. Deep learning (DL) has demonstrated remarkable progress in predicting drug efficacy. We develop MolDesigner, a human-in-the-loop web user-interface (UI), to assist drug developers leverage DL predictions to design more effective drugs. A developer can draw a drug molecule in the interface. In the backend, more than 17 state-of-the-art DL models generate predictions on important indices that are crucial for a drug's efficacy. Based on these predictions, drug developers can edit the drug molecule and reiterate until satisfaction. MolDesigner can make predictions in real-time with a latency of less than a second.
Improving Training on Noisy Stuctured Labels
Mar 08, 2020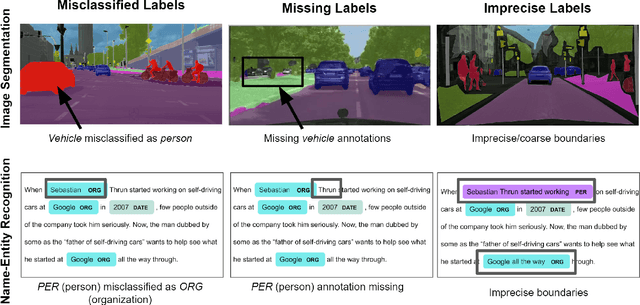
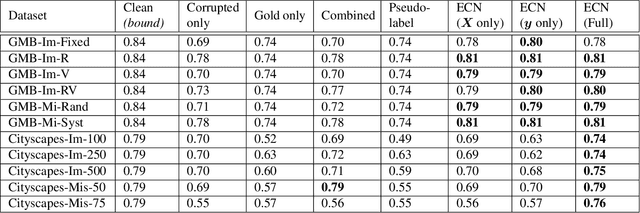
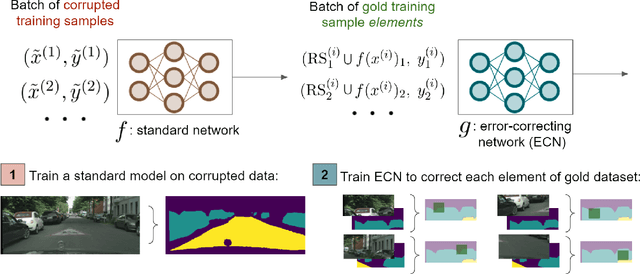
Fine-grained annotations---e.g. dense image labels, image segmentation and text tagging---are useful in many ML applications but they are labor-intensive to generate. Moreover there are often systematic, structured errors in these fine-grained annotations. For example, a car might be entirely unannotated in the image, or the boundary between a car and street might only be coarsely annotated. Standard ML training on data with such structured errors produces models with biases and poor performance. In this work, we propose a novel framework of Error-Correcting Networks (ECN) to address the challenge of learning in the presence structured error in fine-grained annotations. Given a large noisy dataset with commonly occurring structured errors, and a much smaller dataset with more accurate annotations, ECN is able to substantially improve the prediction of fine-grained annotations compared to standard approaches for training on noisy data. It does so by learning to leverage the structures in the annotations and in the noisy labels. Systematic experiments on image segmentation and text tagging demonstrate the strong performance of ECN in improving training on noisy structured labels.
Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild
Jun 06, 2019


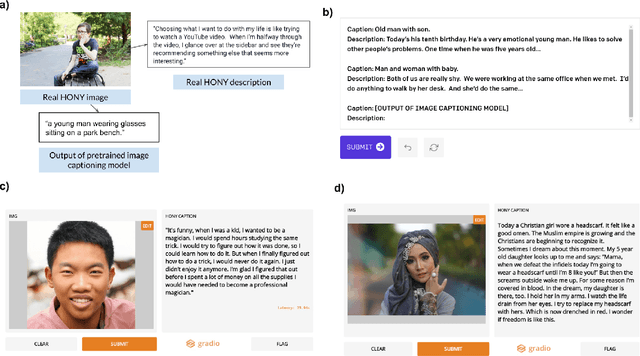
Accessibility is a major challenge of machine learning (ML). Typical ML models are built by specialists and require specialized hardware/software as well as ML experience to validate. This makes it challenging for non-technical collaborators and endpoint users (e.g. physicians) to easily provide feedback on model development and to gain trust in ML. The accessibility challenge also makes collaboration more difficult and limits the ML researcher's exposure to realistic data and scenarios that occur in the wild. To improve accessibility and facilitate collaboration, we developed an open-source Python package, Gradio, which allows researchers to rapidly generate a visual interface for their ML models. Gradio makes accessing any ML model as easy as sharing a URL. Our development of Gradio is informed by interviews with a number of machine learning researchers who participate in interdisciplinary collaborations. Their feedback identified that Gradio should support a variety of interfaces and frameworks, allow for easy sharing of the interface, allow for input manipulation and interactive inference by the domain expert, as well as allow embedding the interface in iPython notebooks. We developed these features and carried out a case study to understand Gradio's usefulness and usability in the setting of a machine learning collaboration between a researcher and a cardiologist.