 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Plotted Data by Image Segmentation
Paper and Code
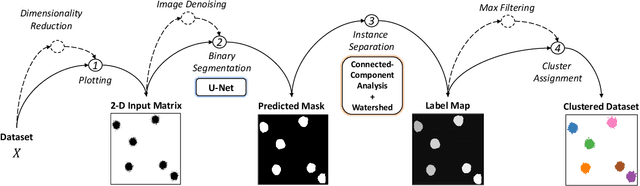
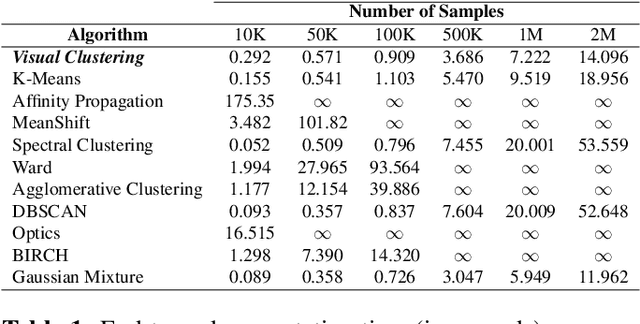
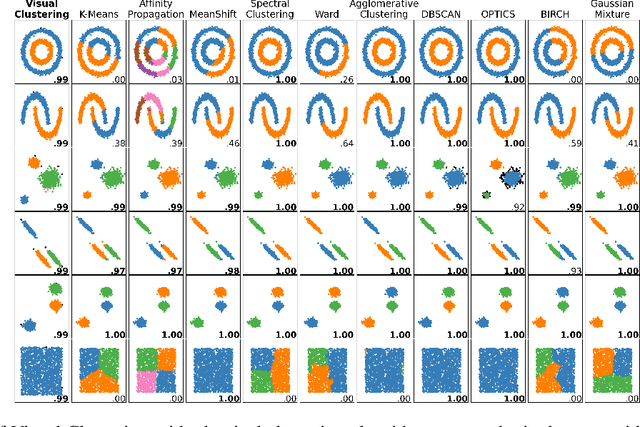
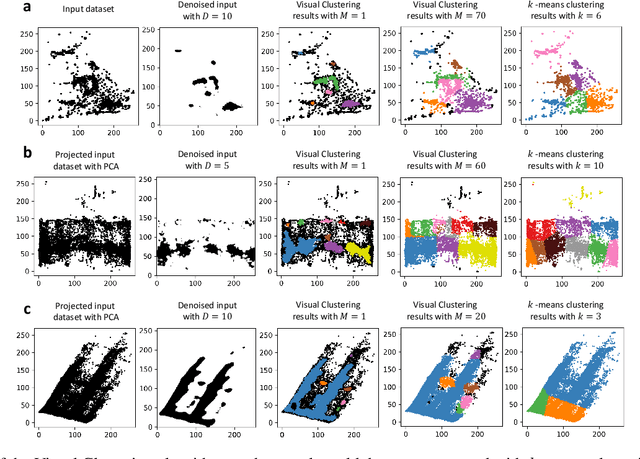
Clustering algorithms are one of the main analytical methods to detect patterns in unlabeled data. Existing clustering methods typically treat samples in a dataset as points in a metric space and compute distances to group together similar points. In this paper, we present a wholly different way of clustering points in 2-dimensional space, inspired by how humans cluster data: by training neural networks to perform instance segmentation on plotted data. Our approach, Visual Clustering, has several advantages over traditional clustering algorithms: it is much faster than most existing clustering algorithms (making it suitable for very large datasets), it agrees strongly with human intuition for clusters, and it is by default hyperparameter free (although additional steps with hyperparameters can be introduced for more control of the algorithm). We describe the method and compare it to ten other clustering methods on synthetic data to illustrate its advantages and disadvantages. We then demonstrate how our approach can be extended to higher dimensional data and illustrate its performance on real-world data. The implementation of Visual Clustering is publicly available and can be applied to any dataset in a few lines of code.