 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Canonical Basis of Human Preferences from Binary Ratings
Mar 31, 2025



Recent advances in generative AI have been driven by alignment techniques such as reinforcement learning from human feedback (RLHF). RLHF and related techniques typically involve constructing a dataset of binary or ranked choice human preferences and subsequently fine-tuning models to align with these preferences. This paper shifts the focus to understanding the preferences encoded in such datasets and identifying common human preferences. We find that a small subset of 21 preference categories (selected from a set of nearly 5,000 distinct preferences) captures >89% of preference variation across individuals. This small set of preferences is analogous to a canonical basis of human preferences, similar to established findings that characterize human variation in psychology or facial recognition studies. Through both synthetic and empirical evaluations, we confirm that our low-rank, canonical set of human preferences generalizes across the entire dataset and within specific topics. We further demonstrate our preference basis' utility in model evaluation, where our preference categories offer deeper insights into model alignment, and in model training, where we show that fine-tuning on preference-defined subsets successfully aligns the model accordingly.
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Oct 03, 2023



Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficult to obtain. Researchers who are more junior or from under-resourced settings have especially hard times getting timely feedback. With the breakthrough of large language models (LLM) such as GPT-4, there is growing interest in using LLMs to generate scientific feedback on research manuscripts. However, the utility of LLM-generated feedback has not been systematically studied. To address this gap, we created an automated pipeline using GPT-4 to provide comments on the full PDFs of scientific papers. We evaluated the quality of GPT-4's feedback through two large-scale studies. We first quantitatively compared GPT-4's generated feedback with human peer reviewer feedback in 15 Nature family journals (3,096 papers in total) and the ICLR machine learning conference (1,709 papers). The overlap in the points raised by GPT-4 and by human reviewers (average overlap 30.85% for Nature journals, 39.23% for ICLR) is comparable to the overlap between two human reviewers (average overlap 28.58% for Nature journals, 35.25% for ICLR). The overlap between GPT-4 and human reviewers is larger for the weaker papers. We then conducted a prospective user study with 308 researchers from 110 US institutions in the field of AI and computational biology to understand how researchers perceive feedback generated by our GPT-4 system on their own papers. Overall, more than half (57.4%) of the users found GPT-4 generated feedback helpful/very helpful and 82.4% found it more beneficial than feedback from at least some human reviewers. While our findings show that LLM-generated feedback can help researchers, we also identify several limitations.
ArtWhisperer: A Dataset for Characterizing Human-AI Interactions in Artistic Creations
Jun 13, 2023As generative AI becomes more prevalent, it is important to study how human users interact with such models. In this work, we investigate how people use text-to-image models to generate desired target images. To study this interaction, we created ArtWhisperer, an online game where users are given a target image and are tasked with iteratively finding a prompt that creates a similar-looking image as the target. Through this game, we recorded over 50,000 human-AI interactions; each interaction corresponds to one text prompt created by a user and the corresponding generated image. The majority of these are repeated interactions where a user iterates to find the best prompt for their target image, making this a unique sequential dataset for studying human-AI collaborations. In an initial analysis of this dataset, we identify several characteristics of prompt interactions and user strategies. People submit diverse prompts and are able to discover a variety of text descriptions that generate similar images. Interestingly, prompt diversity does not decrease as users find better prompts. We further propose to a new metric the study the steerability of AI using our dataset. We define steerability as the expected number of interactions required to adequately complete a task. We estimate this value by fitting a Markov chain for each target task and calculating the expected time to reach an adequate score in the Markov chain. We quantify and compare AI steerability across different types of target images and two different models, finding that images of cities and natural world images are more steerable than artistic and fantasy images. These findings provide insights into human-AI interaction behavior, present a concrete method of assessing AI steerability, and demonstrate the general utility of the ArtWhisperer dataset.
Development and Clinical Evaluation of an AI Support Tool for Improving Telemedicine Photo Quality
Sep 12, 2022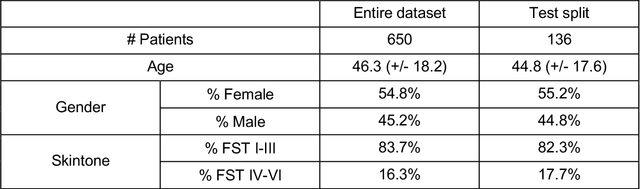
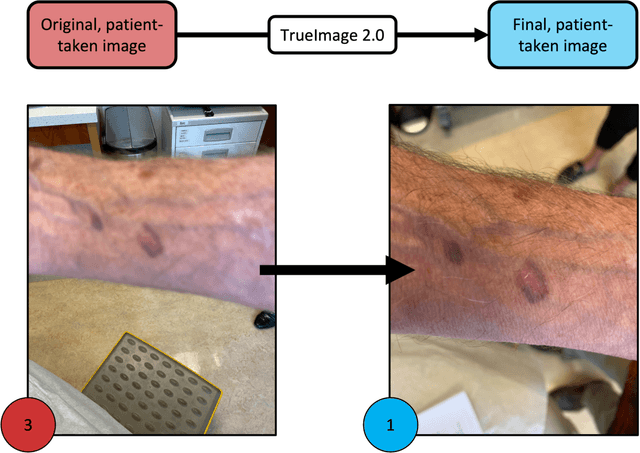

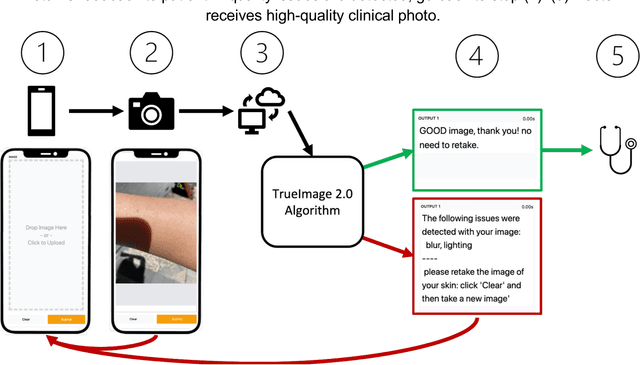
Telemedicine utilization was accelerated during the COVID-19 pandemic, and skin conditions were a common use case. However, the quality of photographs sent by patients remains a major limitation. To address this issue, we developed TrueImage 2.0, an artificial intelligence (AI) model for assessing patient photo quality for telemedicine and providing real-time feedback to patients for photo quality improvement. TrueImage 2.0 was trained on 1700 telemedicine images annotated by clinicians for photo quality. On a retrospective dataset of 357 telemedicine images, TrueImage 2.0 effectively identified poor quality images (Receiver operator curve area under the curve (ROC-AUC) =0.78) and the reason for poor quality (Blurry ROC-AUC=0.84, Lighting issues ROC-AUC=0.70). The performance is consistent across age, gender, and skin tone. Next, we assessed whether patient-TrueImage 2.0 interaction led to an improvement in submitted photo quality through a prospective clinical pilot study with 98 patients. TrueImage 2.0 reduced the number of patients with a poor-quality image by 68.0%.
Disparities in Dermatology AI Performance on a Diverse, Curated Clinical Image Set
Mar 15, 2022Access to dermatological care is a major issue, with an estimated 3 billion people lacking access to care globally. Artificial intelligence (AI) may aid in triaging skin diseases. However, most AI models have not been rigorously assessed on images of diverse skin tones or uncommon diseases. To ascertain potential biases in algorithm performance in this context, we curated the Diverse Dermatology Images (DDI) dataset-the first publicly available, expertly curated, and pathologically confirmed image dataset with diverse skin tones. Using this dataset of 656 images, we show that state-of-the-art dermatology AI models perform substantially worse on DDI, with receiver operator curve area under the curve (ROC-AUC) dropping by 27-36 percent compared to the models' original test results. All the models performed worse on dark skin tones and uncommon diseases, which are represented in the DDI dataset. Additionally, we find that dermatologists, who typically provide visual labels for AI training and test datasets, also perform worse on images of dark skin tones and uncommon diseases compared to ground truth biopsy annotations. Finally, fine-tuning AI models on the well-characterized and diverse DDI images closed the performance gap between light and dark skin tones. Moreover, algorithms fine-tuned on diverse skin tones outperformed dermatologists on identifying malignancy on images of dark skin tones. Our findings identify important weaknesses and biases in dermatology AI that need to be addressed to ensure reliable application to diverse patients and diseases.
Uncalibrated Models Can Improve Human-AI Collaboration
Feb 12, 2022
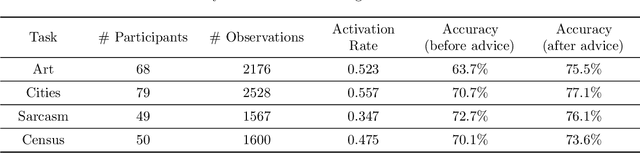


In many practical applications of AI, an AI model is used as a decision aid for human users. The AI provides advice that a human (sometimes) incorporates into their decision-making process. The AI advice is often presented with some measure of "confidence" that the human can use to calibrate how much they depend on or trust the advice. In this paper, we demonstrate that presenting AI models as more confident than they actually are, even when the original AI is well-calibrated, can improve human-AI performance (measured as the accuracy and confidence of the human's final prediction after seeing the AI advice). We first learn a model for how humans incorporate AI advice using data from thousands of human interactions. This enables us to explicitly estimate how to transform the AI's prediction confidence, making the AI uncalibrated, in order to improve the final human prediction. We empirically validate our results across four different tasks -- dealing with images, text and tabular data -- involving hundreds of human participants. We further support our findings with simulation analysis. Our findings suggest the importance of and a framework for jointly optimizing the human-AI system as opposed to the standard paradigm of optimizing the AI model alone.
Disparities in Dermatology AI: Assessments Using Diverse Clinical Images
Nov 15, 2021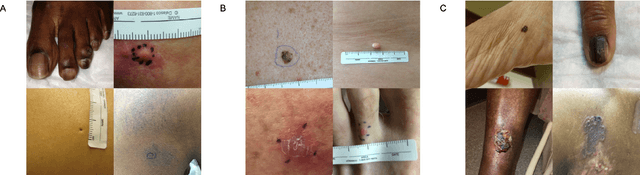
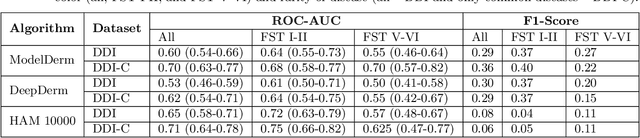
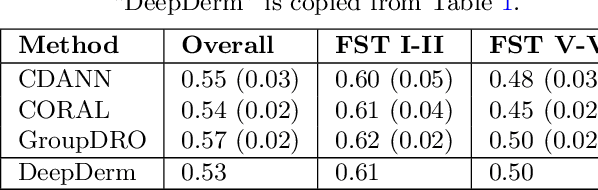
More than 3 billion people lack access to care for skin disease. AI diagnostic tools may aid in early skin cancer detection; however most models have not been assessed on images of diverse skin tones or uncommon diseases. To address this, we curated the Diverse Dermatology Images (DDI) dataset - the first publicly available, pathologically confirmed images featuring diverse skin tones. We show that state-of-the-art dermatology AI models perform substantially worse on DDI, with ROC-AUC dropping 29-40 percent compared to the models' original results. We find that dark skin tones and uncommon diseases, which are well represented in the DDI dataset, lead to performance drop-offs. Additionally, we show that state-of-the-art robust training methods cannot correct for these biases without diverse training data. Our findings identify important weaknesses and biases in dermatology AI that need to be addressed to ensure reliable application to diverse patients and across all disease.
Do Humans Trust Advice More if it Comes from AI? An Analysis of Human-AI Interactions
Jul 14, 2021



In many applications of AI, the algorithm's output is framed as a suggestion to a human user. The user may ignore the advice or take it into consideration to modify his/her decisions. With the increasing prevalence of such human-AI interactions, it is important to understand how users act (or do not act) upon AI advice, and how users regard advice differently if they believe the advice come from an "AI" versus another human. In this paper, we characterize how humans use AI suggestions relative to equivalent suggestions from a group of peer humans across several experimental settings. We find that participants' beliefs about the human versus AI performance on a given task affects whether or not they heed the advice. When participants decide to use the advice, they do so similarly for human and AI suggestions. These results provide insights into factors that affect human-AI interactions.
Adversarial Training Helps Transfer Learning via Better Representations
Jun 18, 2021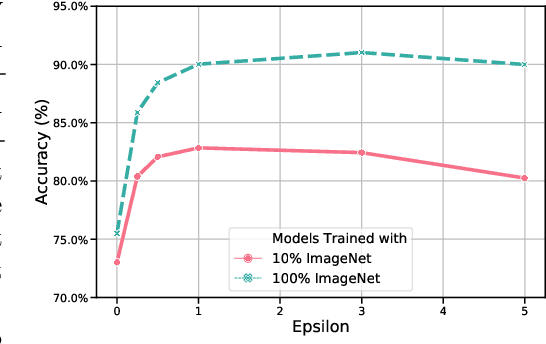



Transfer learning aims to leverage models pre-trained on source data to efficiently adapt to target setting, where only limited data are available for model fine-tuning. Recent works empirically demonstrate that adversarial training in the source data can improve the ability of models to transfer to new domains. However, why this happens is not known. In this paper, we provide a theoretical model to rigorously analyze how adversarial training helps transfer learning. We show that adversarial training in the source data generates provably better representations, so fine-tuning on top of this representation leads to a more accurate predictor of the target data. We further demonstrate both theoretically and empirically that semi-supervised learning in the source data can also improve transfer learning by similarly improving the representation. Moreover, performing adversarial training on top of semi-supervised learning can further improve transferability, suggesting that the two approaches have complementary benefits on representations. We support our theories with experiments on popular data sets and deep learning architectures.
Better Knowledge Retention through Metric Learning
Nov 26, 2020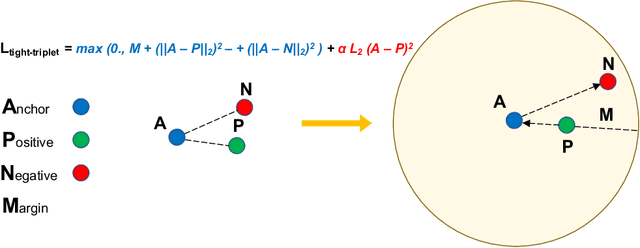


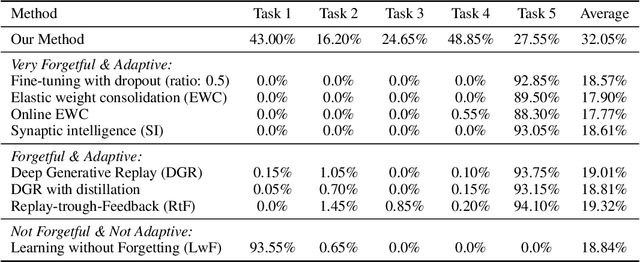
In continual learning, new categories may be introduced over time, and an ideal learning system should perform well on both the original categories and the new categories. While deep neural nets have achieved resounding success in the classical supervised setting, they are known to forget about knowledge acquired in prior episodes of learning if the examples encountered in the current episode of learning are drastically different from those encountered in prior episodes. In this paper, we propose a new method that can both leverage the expressive power of deep neural nets and is resilient to forgetting when new categories are introduced. We found the proposed method can reduce forgetting by 2.3x to 6.9x on CIFAR-10 compared to existing methods and by 1.8x to 2.7x on ImageNet compared to an oracle baseline.