 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommending Best Paper Awards for ML/AI Conferences via the Isotonic Mechanism
Jan 21, 2026Machine learning and artificial intelligence conferences such as NeurIPS and ICML now regularly receive tens of thousands of submissions, posing significant challenges to maintaining the quality and consistency of the peer review process. This challenge is particularly acute for best paper awards, which are an important part of the peer review process, yet whose selection has increasingly become a subject of debate in recent years. In this paper, we introduce an author-assisted mechanism to facilitate the selection of best paper awards. Our method employs the Isotonic Mechanism for eliciting authors' assessments of their own submissions in the form of a ranking, which is subsequently utilized to adjust the raw review scores for optimal estimation of the submissions' ground-truth quality. We demonstrate that authors are incentivized to report truthfully when their utility is a convex additive function of the adjusted scores, and we validate this convexity assumption for best paper awards using publicly accessible review data of ICLR from 2019 to 2023 and NeurIPS from 2021 to 2023. Crucially, in the special case where an author has a single quota -- that is, may nominate only one paper -- we prove that truthfulness holds even when the utility function is merely nondecreasing and additive. This finding represents a substantial relaxation of the assumptions required in prior work. For practical implementation, we extend our mechanism to accommodate the common scenario of overlapping authorship. Finally, simulation results demonstrate that our mechanism significantly improves the quality of papers selected for awards.
Performative Risk Control: Calibrating Models for Reliable Deployment under Performativity
May 30, 2025Calibrating blackbox machine learning models to achieve risk control is crucial to ensure reliable decision-making. A rich line of literature has been studying how to calibrate a model so that its predictions satisfy explicit finite-sample statistical guarantees under a fixed, static, and unknown data-generating distribution. However, prediction-supported decisions may influence the outcome they aim to predict, a phenomenon named performativity of predictions, which is commonly seen in social science and economics. In this paper, we introduce Performative Risk Control, a framework to calibrate models to achieve risk control under performativity with provable theoretical guarantees. Specifically, we provide an iteratively refined calibration process, where we ensure the predictions are improved and risk-controlled throughout the process. We also study different types of risk measures and choices of tail bounds. Lastly, we demonstrate the effectiveness of our framework by numerical experiments on the task of predicting credit default risk. To the best of our knowledge, this work is the first one to study statistically rigorous risk control under performativity, which will serve as an important safeguard against a wide range of strategic manipulation in decision-making processes.
Statistical Inference under Performativity
May 24, 2025Performativity of predictions refers to the phenomena that prediction-informed decisions may influence the target they aim to predict, which is widely observed in policy-making in social sciences and economics. In this paper, we initiate the study of statistical inference under performativity. Our contribution is two-fold. First, we build a central limit theorem for estimation and inference under performativity, which enables inferential purposes in policy-making such as constructing confidence intervals or testing hypotheses. Second, we further leverage the derived central limit theorem to investigate prediction-powered inference (PPI) under performativity, which is based on a small labeled dataset and a much larger dataset of machine-learning predictions. This enables us to obtain more precise estimation and improved confidence regions for the model parameter (i.e., policy) of interest in performative prediction. We demonstrate the power of our framework by numerical experiments. To the best of our knowledge, this paper is the first one to establish statistical inference under performativity, which brings up new challenges and inference settings that we believe will add significant values to policy-making, statistics, and machine learning.
Synergistic Weak-Strong Collaboration by Aligning Preferences
Apr 22, 2025Current Large Language Models (LLMs) excel in general reasoning yet struggle with specialized tasks requiring proprietary or domain-specific knowledge. Fine-tuning large models for every niche application is often infeasible due to black-box constraints and high computational overhead. To address this, we propose a collaborative framework that pairs a specialized weak model with a general strong model. The weak model, tailored to specific domains, produces initial drafts and background information, while the strong model leverages its advanced reasoning to refine these drafts, extending LLMs' capabilities to critical yet specialized tasks. To optimize this collaboration, we introduce a collaborative feedback to fine-tunes the weak model, which quantifies the influence of the weak model's contributions in the collaboration procedure and establishes preference pairs to guide preference tuning of the weak model. We validate our framework through experiments on three domains. We find that the collaboration significantly outperforms each model alone by leveraging complementary strengths. Moreover, aligning the weak model with the collaborative preference further enhances overall performance.
Conformal Tail Risk Control for Large Language Model Alignment
Feb 27, 2025Recent developments in large language models (LLMs) have led to their widespread usage for various tasks. The prevalence of LLMs in society implores the assurance on the reliability of their performance. In particular, risk-sensitive applications demand meticulous attention to unexpectedly poor outcomes, i.e., tail events, for instance, toxic answers, humiliating language, and offensive outputs. Due to the costly nature of acquiring human annotations, general-purpose scoring models have been created to automate the process of quantifying these tail events. This phenomenon introduces potential human-machine misalignment between the respective scoring mechanisms. In this work, we present a lightweight calibration framework for blackbox models that ensures the alignment of humans and machines with provable guarantees. Our framework provides a rigorous approach to controlling any distortion risk measure that is characterized by a weighted average of quantiles of the loss incurred by the LLM with high confidence. The theoretical foundation of our method relies on the connection between conformal risk control and a traditional family of statistics, i.e., L-statistics. To demonstrate the utility of our framework, we conduct comprehensive experiments that address the issue of human-machine misalignment.
Improving Predictor Reliability with Selective Recalibration
Oct 07, 2024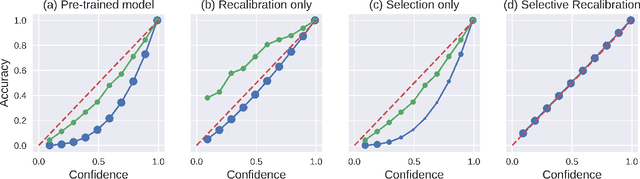
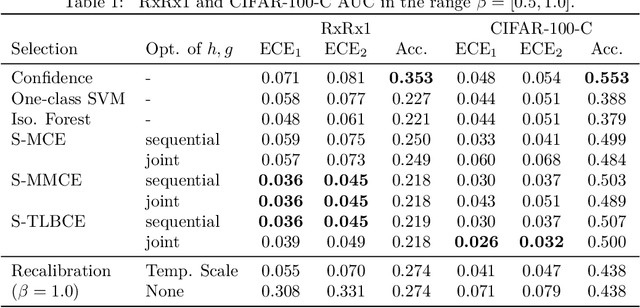
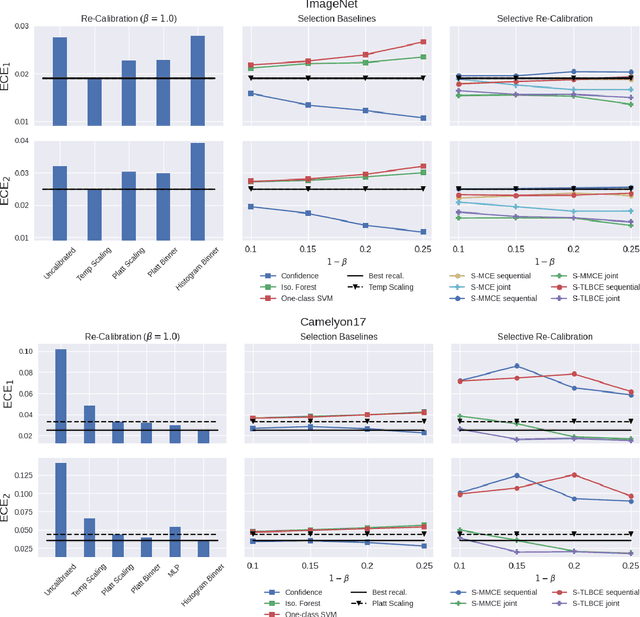
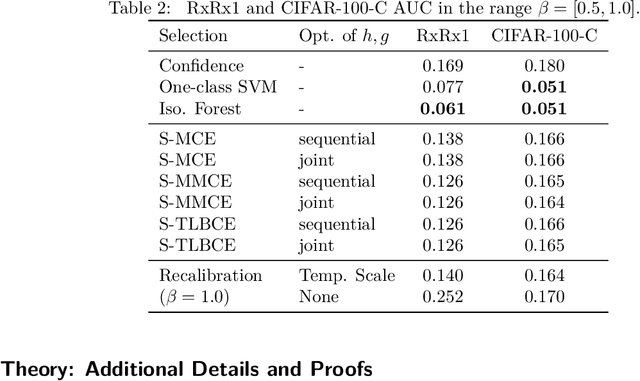
A reliable deep learning system should be able to accurately express its confidence with respect to its predictions, a quality known as calibration. One of the most effective ways to produce reliable confidence estimates with a pre-trained model is by applying a post-hoc recalibration method. Popular recalibration methods like temperature scaling are typically fit on a small amount of data and work in the model's output space, as opposed to the more expressive feature embedding space, and thus usually have only one or a handful of parameters. However, the target distribution to which they are applied is often complex and difficult to fit well with such a function. To this end we propose \textit{selective recalibration}, where a selection model learns to reject some user-chosen proportion of the data in order to allow the recalibrator to focus on regions of the input space that can be well-captured by such a model. We provide theoretical analysis to motivate our algorithm, and test our method through comprehensive experiments on difficult medical imaging and zero-shot classification tasks. Our results show that selective recalibration consistently leads to significantly lower calibration error than a wide range of selection and recalibration baselines.
An Economic Solution to Copyright Challenges of Generative AI
Apr 24, 2024



Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Provable Multi-Party Reinforcement Learning with Diverse Human Feedback
Mar 08, 2024Reinforcement learning with human feedback (RLHF) is an emerging paradigm to align models with human preferences. Typically, RLHF aggregates preferences from multiple individuals who have diverse viewpoints that may conflict with each other. Our work \textit{initiates} the theoretical study of multi-party RLHF that explicitly models the diverse preferences of multiple individuals. We show how traditional RLHF approaches can fail since learning a single reward function cannot capture and balance the preferences of multiple individuals. To overcome such limitations, we incorporate meta-learning to learn multiple preferences and adopt different social welfare functions to aggregate the preferences across multiple parties. We focus on the offline learning setting and establish sample complexity bounds, along with efficiency and fairness guarantees, for optimizing diverse social welfare functions such as Nash, Utilitarian, and Leximin welfare functions. Our results show a separation between the sample complexities of multi-party RLHF and traditional single-party RLHF. Furthermore, we consider a reward-free setting, where each individual's preference is no longer consistent with a reward model, and give pessimistic variants of the von Neumann Winner based on offline preference data. Taken together, our work showcases the advantage of multi-party RLHF but also highlights its more demanding statistical complexity.
Can AI Be as Creative as Humans?
Jan 12, 2024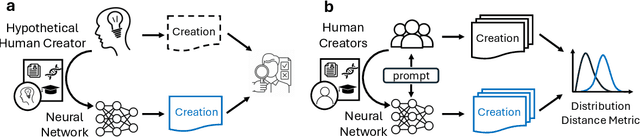
Creativity serves as a cornerstone for societal progress and innovation. With the rise of advanced generative AI models capable of tasks once reserved for human creativity, the study of AI's creative potential becomes imperative for its responsible development and application. In this paper, we provide a theoretical answer to the question of whether AI can be creative. We prove in theory that AI can be as creative as humans under the condition that AI can fit the existing data generated by human creators. Therefore, the debate on AI's creativity is reduced into the question of its ability of fitting a massive amount of data. To arrive at this conclusion, this paper first addresses the complexities in defining creativity by introducing a new concept called Relative Creativity. Instead of trying to define creativity universally, we shift the focus to whether AI can match the creative abilities of a hypothetical human. This perspective draws inspiration from the Turing Test, expanding upon it to address the challenges and subjectivities inherent in assessing creativity. This methodological shift leads to a statistically quantifiable assessment of AI's creativity, which we term Statistical Creativity. This concept allows for comparisons of AI's creative abilities with those of specific human groups, and facilitates the theoretical findings of AI's creative potential. Building on this foundation, we discuss the application of statistical creativity in prompt-conditioned autoregressive models, providing a practical means for evaluating creative abilities of contemporary AI models, such as Large Language Models (LLMs). In addition to defining and analyzing creativity, we introduce an actionable training guideline, effectively bridging the gap between theoretical quantification of creativity and practical model training.
Learning and Forgetting Unsafe Examples in Large Language Models
Dec 20, 2023

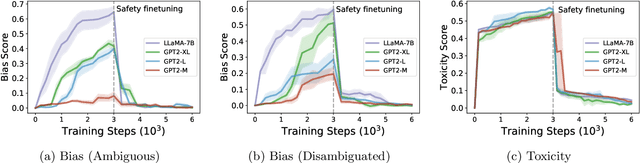
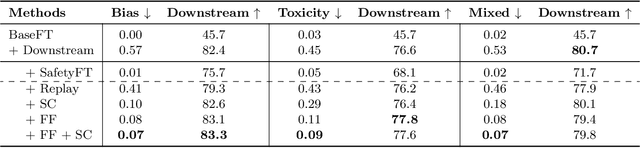
As the number of large language models (LLMs) released to the public grows, there is a pressing need to understand the safety implications associated with these models learning from third-party custom finetuning data. We explore the behavior of LLMs finetuned on noisy custom data containing unsafe content, represented by datasets that contain biases, toxicity, and harmfulness, finding that while aligned LLMs can readily learn this unsafe content, they also tend to forget it more significantly than other examples when subsequently finetuned on safer content. Drawing inspiration from the discrepancies in forgetting, we introduce the "ForgetFilter" algorithm, which filters unsafe data based on how strong the model's forgetting signal is for that data. We demonstrate that the ForgetFilter algorithm ensures safety in customized finetuning without compromising downstream task performance, unlike sequential safety finetuning. ForgetFilter outperforms alternative strategies like replay and moral self-correction in curbing LLMs' ability to assimilate unsafe content during custom finetuning, e.g. 75% lower than not applying any safety measures and 62% lower than using self-correction in toxicity score.