 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Piggyback Hypothesis of Generalization: Explaining and Mitigating Emergent Misalignment
Jun 04, 2026The mechanisms behind LLMs' broad over-generalization beyond training examples remain unclear. Emergent misalignment (EM) offers a striking case study: finetuning on narrow tasks induces broad misalignment to semantically-unrelated test domains. In this work, we propose the Piggyback Hypothesis: the chat-template tokens can piggyback the finetuned behaviour onto out-of-domain queries. We validate this hypothesis by showing that subtle perturbations to the prefix (tokens preceding all user queries), or patching the prefix representations with those from the unfinetuned model, can restore alignment without changing the user query. Building on this finding, we propose Token-Regularized Finetuning (TReFT), which regularizes specific token representations during training to mitigate EM. Across different models and multiple EM-inducing datasets, TReFT reduces EM while preserving in-domain learning. On Llama-3.1-8B finetuned on the legal domain, TReFT achieves 33.5% more EM reduction than data interleaving with a retain set of aligned examples. We further show that TReFT extends to other narrow-finetuning settings, including abstention, tool use, and refusal (off-topic generalization is reduced by 54.3% on average), supporting the Piggyback Hypothesis. Broadly, our work highlights that LLMs may learn and generalize in unintended ways and suggests a path toward more constrained finetuning. It also calls for further study of how shared input features can piggyback model behavior across domains.
Beyond a Single Direction: Chain-of-Thought Disrupts Simple Steering of Refusal
May 26, 2026Large reasoning models (LRMs) generate chain-of-thought (CoT) traces before producing final outputs, introducing a dynamic internal state that may complicate control mechanisms such as refusal. Unlike instruction-tuned LLMs, where refusal is mediated by a single directional subspace, refusal in large reasoning models (LRMs) additionally depends on the CoT. In DeepSeek-R1-Distill-LLaMA-8B, activation steering reverses refusal in only 39% of cases when the CoT is kept fixed, but removing the CoT entirely increases this to 70%, indicating that the CoT actively reinforces refusal. In a two-stage intervention where the model regenerates its CoT under activation steering, refusal is reversed in 94% of cases, while the resulting CoT alone retains 48% of this effect even after steering is removed. This suggests that the CoT can carry and reconstruct the compliance signal independently. These findings indicate that refusal in LRMs is jointly encoded in residual stream activations and CoT. This joint activation makes LRM more robust against activation-level interventions alone, but exposes CoT to a possible alternative surface attack.
LLMs Encode Harmfulness and Refusal Separately
Jul 16, 2025LLMs are trained to refuse harmful instructions, but do they truly understand harmfulness beyond just refusing? Prior work has shown that LLMs' refusal behaviors can be mediated by a one-dimensional subspace, i.e., a refusal direction. In this work, we identify a new dimension to analyze safety mechanisms in LLMs, i.e., harmfulness, which is encoded internally as a separate concept from refusal. There exists a harmfulness direction that is distinct from the refusal direction. As causal evidence, steering along the harmfulness direction can lead LLMs to interpret harmless instructions as harmful, but steering along the refusal direction tends to elicit refusal responses directly without reversing the model's judgment on harmfulness. Furthermore, using our identified harmfulness concept, we find that certain jailbreak methods work by reducing the refusal signals without reversing the model's internal belief of harmfulness. We also find that adversarially finetuning models to accept harmful instructions has minimal impact on the model's internal belief of harmfulness. These insights lead to a practical safety application: The model's latent harmfulness representation can serve as an intrinsic safeguard (Latent Guard) for detecting unsafe inputs and reducing over-refusals that is robust to finetuning attacks. For instance, our Latent Guard achieves performance comparable to or better than Llama Guard 3 8B, a dedicated finetuned safeguard model, across different jailbreak methods. Our findings suggest that LLMs' internal understanding of harmfulness is more robust than their refusal decision to diverse input instructions, offering a new perspective to study AI safety
Learning and Forgetting Unsafe Examples in Large Language Models
Dec 20, 2023

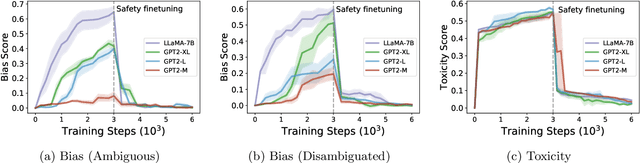
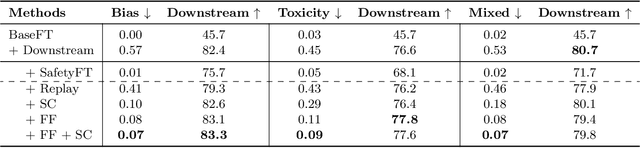
As the number of large language models (LLMs) released to the public grows, there is a pressing need to understand the safety implications associated with these models learning from third-party custom finetuning data. We explore the behavior of LLMs finetuned on noisy custom data containing unsafe content, represented by datasets that contain biases, toxicity, and harmfulness, finding that while aligned LLMs can readily learn this unsafe content, they also tend to forget it more significantly than other examples when subsequently finetuned on safer content. Drawing inspiration from the discrepancies in forgetting, we introduce the "ForgetFilter" algorithm, which filters unsafe data based on how strong the model's forgetting signal is for that data. We demonstrate that the ForgetFilter algorithm ensures safety in customized finetuning without compromising downstream task performance, unlike sequential safety finetuning. ForgetFilter outperforms alternative strategies like replay and moral self-correction in curbing LLMs' ability to assimilate unsafe content during custom finetuning, e.g. 75% lower than not applying any safety measures and 62% lower than using self-correction in toxicity score.
Student as an Inherent Denoiser of Noisy Teacher
Dec 15, 2023Knowledge distillation (KD) has been widely employed to transfer knowledge from a large language model (LLM) to a specialized model in low-data regimes through pseudo label learning. However, pseudo labels generated by teacher models are usually noisy and may influence KD performance. This study delves into KD with noisy teachers and uncovers that the student model can already generate more accurate predictions than the teacher labels used to train it during KD, indicating its inherent ability to denoise noisy teacher labels. Motivated by this finding, we propose Peer-Advised KD to improve vanilla KD from noisy teachers. Experiments show that Peer-Advised KD can outperform LLM by approximately 5% with 50 human-labeled data, and even competitive to standard supervised finetuning with 750 human-labeled data.
Multistage Collaborative Knowledge Distillation from Large Language Models
Nov 15, 2023



We study semi-supervised sequence prediction tasks where labeled data are too scarce to effectively finetune a model and at the same time few-shot prompting of a large language model (LLM) has suboptimal performance. This happens when a task, such as parsing, is expensive to annotate and also unfamiliar to a pretrained LLM. In this paper, we present a discovery that student models distilled from a prompted LLM can often generalize better than their teacher on such tasks. Leveraging this finding, we propose a new distillation method, multistage collaborative knowledge distillation from an LLM (MCKD), for such tasks. MCKD first prompts an LLM using few-shot in-context learning to produce pseudolabels for unlabeled data. Then, at each stage of distillation, a pair of students are trained on disjoint partitions of the pseudolabeled data. Each student subsequently produces new and improved pseudolabels for the unseen partition to supervise the next round of student(s) with. We show the benefit of multistage cross-partition labeling on two constituency parsing tasks. On CRAFT biomedical parsing, 3-stage MCKD with 50 labeled examples matches the performance of supervised finetuning with 500 examples and outperforms the prompted LLM and vanilla KD by 7.5% and 3.7% parsing F1, respectively.
SELF-EXPLAIN: Teaching Large Language Models to Reason Complex Questions by Themselves
Nov 12, 2023



Large language models (LLMs) can generate intermediate reasoning steps. To elicit the reliable reasoning, the common practice is to employ few-shot chain-of-thought prompting, where several in-context demonstrations for reasoning are prepended to the question. However, such chain-of-thought examples are expensive to craft, especially for professional domains, and can have high variance depending on human annotators. Therefore, this work investigates whether LLMs can teach themselves to reason without human-crafted demonstrations. We propose SELF-EXPLAIN to generate CoT examples by LLMs inspired by "encoding specificity" in human memory retrieval. We find using self-explanations makes LLMs more confident, more calibrated and less biased when answering complex questions. Moreover, we find prompting with self-explanations can even significantly outperform using human-crafted CoTs on several complex question answering dataset.
* Workshop on robustness of zero/few-shot learning in foundation models @ NeurIPS 2023
In-Context Exemplars as Clues to Retrieving from Large Associative Memory
Nov 06, 2023


Recently, large language models (LLMs) have made remarkable progress in natural language processing. The most representative ability of LLMs is in-context learning (ICL), which enables LLMs to learn patterns from in-context exemplars without training. The performance of ICL greatly depends on the exemplars used. However, how to choose exemplars remains unclear due to the lack of understanding of how in-context learning works. In this paper, we present a novel perspective on ICL by conceptualizing it as contextual retrieval from a model of associative memory. We establish a theoretical framework of ICL based on Hopfield Networks. Based on our framework, we look into how in-context exemplars influence the performance of ICL and propose more efficient active exemplar selection. Our study sheds new light on the mechanism of ICL by connecting it to memory retrieval, with potential implications for advancing the understanding of LLMs.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Trigger-free Event Detection via Derangement Reading Comprehension
Aug 20, 2022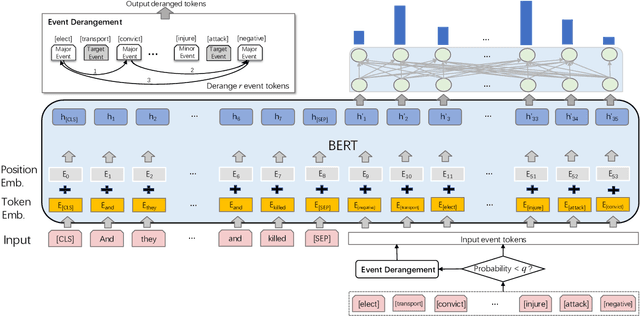
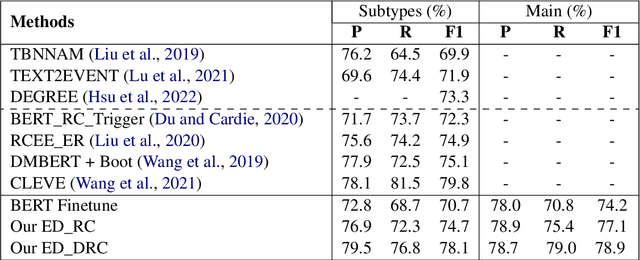
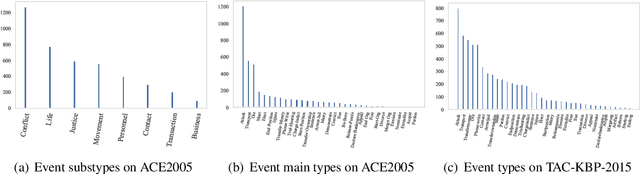
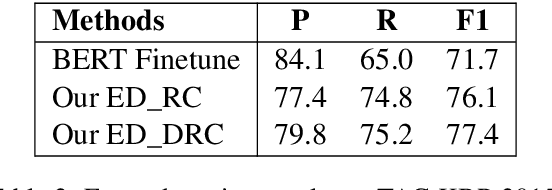
Event detection (ED), aiming to detect events from texts and categorize them, is vital to understanding actual happenings in real life. However, mainstream event detection models require high-quality expert human annotations of triggers, which are often costly and thus deter the application of ED to new domains. Therefore, in this paper, we focus on low-resource ED without triggers and aim to tackle the following formidable challenges: multi-label classification, insufficient clues, and imbalanced events distribution. We propose a novel trigger-free ED method via Derangement mechanism on a machine Reading Comprehension (DRC) framework. More specifically, we treat the input text as Context and concatenate it with all event type tokens that are deemed as Answers with an omitted default question. So we can leverage the self-attention in pre-trained language models to absorb semantic relations between input text and the event types. Moreover, we design a simple yet effective event derangement module (EDM) to prevent major events from being excessively learned so as to yield a more balanced training process. The experiment results show that our proposed trigger-free ED model is remarkably competitive to mainstream trigger-based models, showing its strong performance on low-source event detection.