 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan QPP Choose the Right Query Variant? Evaluating Query Variant Selection for RAG Pipelines
Apr 24, 2026Large Language Models (LLMs) have made query reformulation ubiquitous in modern retrieval and Retrieval-Augmented Generation (RAG) pipelines, enabling the generation of multiple semantically equivalent query variants. However, executing the full pipeline for every reformulation is computationally expensive, motivating selective execution: can we identify the best query variant before incurring downstream retrieval and generation costs? We investigate Query Performance Prediction (QPP) as a mechanism for variant selection across ad-hoc retrieval and end-to-end RAG. Unlike traditional QPP, which estimates query difficulty across topics, we study intra-topic discrimination - selecting the optimal reformulation among competing variants of the same information need. Through large-scale experiments on TREC-RAG using both sparse and dense retrievers, we evaluate pre- and post-retrieval predictors under correlation- and decision-based metrics. Our results reveal a systematic divergence between retrieval and generation objectives: variants that maximize ranking metrics such as nDCG often fail to produce the best generated answers, exposing a "utility gap" between retrieval relevance and generation fidelity. Nevertheless, QPP can reliably identify variants that improve end-to-end quality over the original query. Notably, lightweight pre-retrieval predictors frequently match or outperform more expensive post-retrieval methods, offering a latency-efficient approach to robust RAG.
KARL: Knowledge Agents via Reinforcement Learning
Mar 05, 2026We present a system for training enterprise search agents via reinforcement learning that achieves state-of-the-art performance across a diverse suite of hard-to-verify agentic search tasks. Our work makes four core contributions. First, we introduce KARLBench, a multi-capability evaluation suite spanning six distinct search regimes, including constraint-driven entity search, cross-document report synthesis, tabular numerical reasoning, exhaustive entity retrieval, procedural reasoning over technical documentation, and fact aggregation over internal enterprise notes. Second, we show that models trained across heterogeneous search behaviors generalize substantially better than those optimized for any single benchmark. Third, we develop an agentic synthesis pipeline that employs long-horizon reasoning and tool use to generate diverse, grounded, and high-quality training data, with iterative bootstrapping from increasingly capable models. Fourth, we propose a new post-training paradigm based on iterative large-batch off-policy RL that is sample efficient, robust to train-inference engine discrepancies, and naturally extends to multi-task training with out-of-distribution generalization. Compared to Claude 4.6 and GPT 5.2, KARL is Pareto-optimal on KARLBench across cost-quality and latency-quality trade-offs, including tasks that were out-of-distribution during training. With sufficient test-time compute, it surpasses the strongest closed models. These results show that tailored synthetic data in combination with multi-task reinforcement learning enables cost-efficient and high-performing knowledge agents for grounded reasoning.
FreshStack: Building Realistic Benchmarks for Evaluating Retrieval on Technical Documents
Apr 17, 2025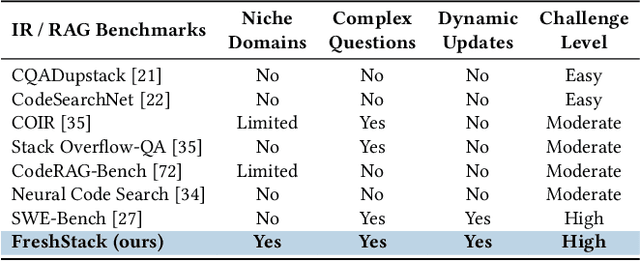
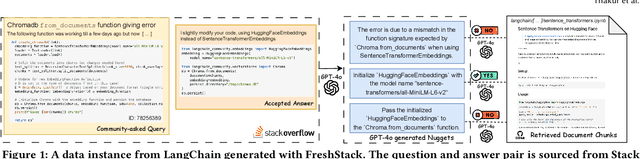
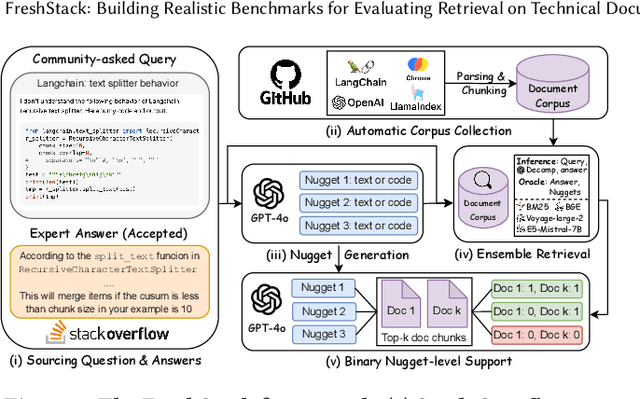

We introduce FreshStack, a reusable framework for automatically building information retrieval (IR) evaluation benchmarks from community-asked questions and answers. FreshStack conducts the following steps: (1) automatic corpus collection from code and technical documentation, (2) nugget generation from community-asked questions and answers, and (3) nugget-level support, retrieving documents using a fusion of retrieval techniques and hybrid architectures. We use FreshStack to build five datasets on fast-growing, recent, and niche topics to ensure the tasks are sufficiently challenging. On FreshStack, existing retrieval models, when applied out-of-the-box, significantly underperform oracle approaches on all five topics, denoting plenty of headroom to improve IR quality. In addition, we identify cases where rerankers do not clearly improve first-stage retrieval accuracy (two out of five topics). We hope that FreshStack will facilitate future work toward constructing realistic, scalable, and uncontaminated IR and RAG evaluation benchmarks. FreshStack datasets are available at: https://fresh-stack.github.io.
Drowning in Documents: Consequences of Scaling Reranker Inference
Nov 18, 2024



Rerankers, typically cross-encoders, are often used to re-score the documents retrieved by cheaper initial IR systems. This is because, though expensive, rerankers are assumed to be more effective. We challenge this assumption by measuring reranker performance for full retrieval, not just re-scoring first-stage retrieval. Our experiments reveal a surprising trend: the best existing rerankers provide diminishing returns when scoring progressively more documents and actually degrade quality beyond a certain limit. In fact, in this setting, rerankers can frequently assign high scores to documents with no lexical or semantic overlap with the query. We hope that our findings will spur future research to improve reranking.
Retrieval-Enhanced Machine Learning: Synthesis and Opportunities
Jul 17, 2024



In the field of language modeling, models augmented with retrieval components have emerged as a promising solution to address several challenges faced in the natural language processing (NLP) field, including knowledge grounding, interpretability, and scalability. Despite the primary focus on NLP, we posit that the paradigm of retrieval-enhancement can be extended to a broader spectrum of machine learning (ML) such as computer vision, time series prediction, and computational biology. Therefore, this work introduces a formal framework of this paradigm, Retrieval-Enhanced Machine Learning (REML), by synthesizing the literature in various domains in ML with consistent notations which is missing from the current literature. Also, we found that while a number of studies employ retrieval components to augment their models, there is a lack of integration with foundational Information Retrieval (IR) research. We bridge this gap between the seminal IR research and contemporary REML studies by investigating each component that comprises the REML framework. Ultimately, the goal of this work is to equip researchers across various disciplines with a comprehensive, formally structured framework of retrieval-enhanced models, thereby fostering interdisciplinary future research.
Multistage Collaborative Knowledge Distillation from Large Language Models
Nov 15, 2023



We study semi-supervised sequence prediction tasks where labeled data are too scarce to effectively finetune a model and at the same time few-shot prompting of a large language model (LLM) has suboptimal performance. This happens when a task, such as parsing, is expensive to annotate and also unfamiliar to a pretrained LLM. In this paper, we present a discovery that student models distilled from a prompted LLM can often generalize better than their teacher on such tasks. Leveraging this finding, we propose a new distillation method, multistage collaborative knowledge distillation from an LLM (MCKD), for such tasks. MCKD first prompts an LLM using few-shot in-context learning to produce pseudolabels for unlabeled data. Then, at each stage of distillation, a pair of students are trained on disjoint partitions of the pseudolabeled data. Each student subsequently produces new and improved pseudolabels for the unseen partition to supervise the next round of student(s) with. We show the benefit of multistage cross-partition labeling on two constituency parsing tasks. On CRAFT biomedical parsing, 3-stage MCKD with 50 labeled examples matches the performance of supervised finetuning with 500 examples and outperforms the prompted LLM and vanilla KD by 7.5% and 3.7% parsing F1, respectively.
PaRaDe: Passage Ranking using Demonstrations with Large Language Models
Oct 22, 2023



Recent studies show that large language models (LLMs) can be instructed to effectively perform zero-shot passage re-ranking, in which the results of a first stage retrieval method, such as BM25, are rated and reordered to improve relevance. In this work, we improve LLM-based re-ranking by algorithmically selecting few-shot demonstrations to include in the prompt. Our analysis investigates the conditions where demonstrations are most helpful, and shows that adding even one demonstration is significantly beneficial. We propose a novel demonstration selection strategy based on difficulty rather than the commonly used semantic similarity. Furthermore, we find that demonstrations helpful for ranking are also effective at question generation. We hope our work will spur more principled research into question generation and passage ranking.
KNN-LM Does Not Improve Open-ended Text Generation
May 24, 2023



In this paper, we study the generation quality of interpolation-based retrieval-augmented language models (LMs). These methods, best exemplified by the KNN-LM, interpolate the LM's predicted distribution of the next word with a distribution formed from the most relevant retrievals for a given prefix. While the KNN-LM and related methods yield impressive decreases in perplexity, we discover that they do not exhibit corresponding improvements in open-ended generation quality, as measured by both automatic evaluation metrics (e.g., MAUVE) and human evaluations. Digging deeper, we find that interpolating with a retrieval distribution actually increases perplexity compared to a baseline Transformer LM for the majority of tokens in the WikiText-103 test set, even though the overall perplexity is lower due to a smaller number of tokens for which perplexity dramatically decreases after interpolation. However, when decoding a long sequence at inference time, significant improvements on this smaller subset of tokens are washed out by slightly worse predictions on most tokens. Furthermore, we discover that the entropy of the retrieval distribution increases faster than that of the base LM as the generated sequence becomes longer, which indicates that retrieval is less reliable when using model-generated text as queries (i.e., is subject to exposure bias). We hope that our analysis spurs future work on improved decoding algorithms and interpolation strategies for retrieval-augmented language models.
You can't pick your neighbors, or can you? When and how to rely on retrieval in the $k$NN-LM
Oct 28, 2022



Retrieval-enhanced language models (LMs), which condition their predictions on text retrieved from large external datastores, have recently shown significant perplexity improvements compared to standard LMs. One such approach, the $k$NN-LM, interpolates any existing LM's predictions with the output of a $k$-nearest neighbors model and requires no additional training. In this paper, we explore the importance of lexical and semantic matching in the context of items retrieved by $k$NN-LM. We find two trends: (1) the presence of large overlapping $n$-grams between the datastore and evaluation set plays an important factor in strong performance, even when the datastore is derived from the training data; and (2) the $k$NN-LM is most beneficial when retrieved items have high semantic similarity with the query. Based on our analysis, we define a new formulation of the $k$NN-LM that uses retrieval quality to assign the interpolation coefficient. We empirically measure the effectiveness of our approach on two English language modeling datasets, Wikitext-103 and PG-19. Our re-formulation of the $k$NN-LM is beneficial in both cases, and leads to nearly 4% improvement in perplexity on the Wikitext-103 test set.
Compositional Semantic Parsing with Large Language Models
Sep 30, 2022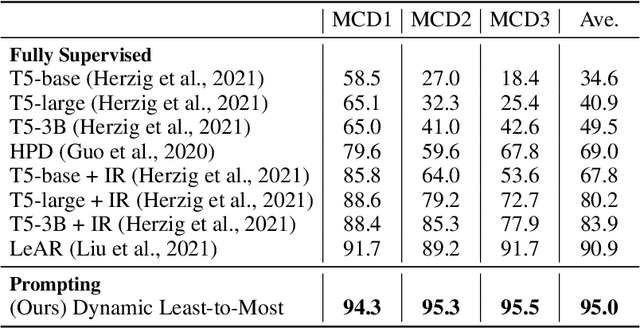
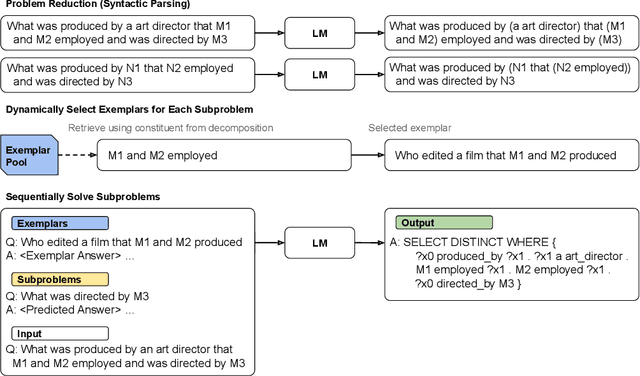
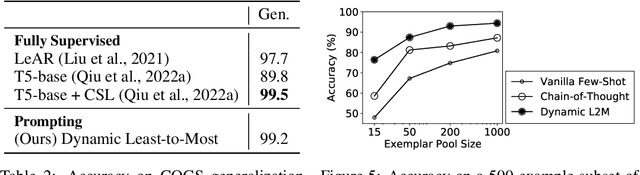
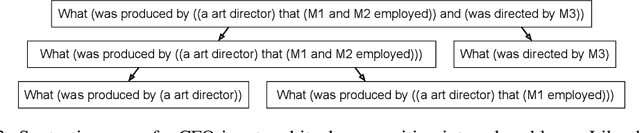
Humans can reason compositionally when presented with new tasks. Previous research shows that appropriate prompting techniques enable large language models (LLMs) to solve artificial compositional generalization tasks such as SCAN. In this work, we identify additional challenges in more realistic semantic parsing tasks with larger vocabulary and refine these prompting techniques to address them. Our best method is based on least-to-most prompting: it decomposes the problem using prompting-based syntactic parsing, then uses this decomposition to select appropriate exemplars and to sequentially generate the semantic parse. This method allows us to set a new state of the art for CFQ while requiring only 1% of the training data used by traditional approaches. Due to the general nature of our approach, we expect similar efforts will lead to new results in other tasks and domains, especially for knowledge-intensive applications.