 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Linear Speedup of Personalized Federated Reinforcement Learning with Shared Representations
Nov 22, 2024Federated reinforcement learning (FedRL) enables multiple agents to collaboratively learn a policy without sharing their local trajectories collected during agent-environment interactions. However, in practice, the environments faced by different agents are often heterogeneous, leading to poor performance by the single policy learned by existing FedRL algorithms on individual agents. In this paper, we take a further step and introduce a \emph{personalized} FedRL framework (PFedRL) by taking advantage of possibly shared common structure among agents in heterogeneous environments. Specifically, we develop a class of PFedRL algorithms named PFedRL-Rep that learns (1) a shared feature representation collaboratively among all agents, and (2) an agent-specific weight vector personalized to its local environment. We analyze the convergence of PFedTD-Rep, a particular instance of the framework with temporal difference (TD) learning and linear representations. To the best of our knowledge, we are the first to prove a linear convergence speedup with respect to the number of agents in the PFedRL setting. To achieve this, we show that PFedTD-Rep is an example of the federated two-timescale stochastic approximation with Markovian noise. Experimental results demonstrate that PFedTD-Rep, along with an extension to the control setting based on deep Q-networks (DQN), not only improve learning in heterogeneous settings, but also provide better generalization to new environments.
SODA: a Soft Origami Dynamic utensil for Assisted feeding
Oct 25, 2024SODA aims to revolutionize assistive feeding systems by designing a multi-purpose utensil using origami-inspired artificial muscles. Traditional utensils, such as forks and spoons,are hard and stiff, causing discomfort and fear among users, especially when operated by autonomous robotic arms. Additionally, these systems require frequent utensil changes to handle different food types. Our innovative utensil design addresses these issues by offering a versatile, adaptive solution that can seamlessly transition between gripping and scooping various foods without the need for manual intervention. Utilizing the flexibility and strength of origami-inspired artificial muscles, the utensil ensures safe and comfortable interactions, enhancing user experience and efficiency. This approach not only simplifies the feeding process but also promotes greater independence for individuals with limited mobility, contributing to the advancement of soft robotics in healthcare applications.
Structured Reinforcement Learning for Delay-Optimal Data Transmission in Dense mmWave Networks
Apr 25, 2024We study the data packet transmission problem (mmDPT) in dense cell-free millimeter wave (mmWave) networks, i.e., users sending data packet requests to access points (APs) via uplinks and APs transmitting requested data packets to users via downlinks. Our objective is to minimize the average delay in the system due to APs' limited service capacity and unreliable wireless channels between APs and users. This problem can be formulated as a restless multi-armed bandits problem with fairness constraint (RMAB-F). Since finding the optimal policy for RMAB-F is intractable, existing learning algorithms are computationally expensive and not suitable for practical dynamic dense mmWave networks. In this paper, we propose a structured reinforcement learning (RL) solution for mmDPT by exploiting the inherent structure encoded in RMAB-F. To achieve this, we first design a low-complexity and provably asymptotically optimal index policy for RMAB-F. Then, we leverage this structure information to develop a structured RL algorithm called mmDPT-TS, which provably achieves an \tilde{O}(\sqrt{T}) Bayesian regret. More importantly, mmDPT-TS is computation-efficient and thus amenable to practical implementation, as it fully exploits the structure of index policy for making decisions. Extensive emulation based on data collected in realistic mmWave networks demonstrate significant gains of mmDPT-TS over existing approaches.
Online Restless Multi-Armed Bandits with Long-Term Fairness Constraints
Dec 22, 2023Restless multi-armed bandits (RMAB) have been widely used to model sequential decision making problems with constraints. The decision maker (DM) aims to maximize the expected total reward over an infinite horizon under an "instantaneous activation constraint" that at most B arms can be activated at any decision epoch, where the state of each arm evolves stochastically according to a Markov decision process (MDP). However, this basic model fails to provide any fairness guarantee among arms. In this paper, we introduce RMAB-F, a new RMAB model with "long-term fairness constraints", where the objective now is to maximize the long term reward while a minimum long-term activation fraction for each arm must be satisfied. For the online RMAB-F setting (i.e., the underlying MDPs associated with each arm are unknown to the DM), we develop a novel reinforcement learning (RL) algorithm named Fair-UCRL. We prove that Fair-UCRL ensures probabilistic sublinear bounds on both the reward regret and the fairness violation regret. Compared with off-the-shelf RL methods, our Fair-UCRL is much more computationally efficient since it contains a novel exploitation that leverages a low-complexity index policy for making decisions. Experimental results further demonstrate the effectiveness of our Fair-UCRL.
Measuring and Mitigating Constraint Violations of In-Context Learning for Utterance-to-API Semantic Parsing
May 24, 2023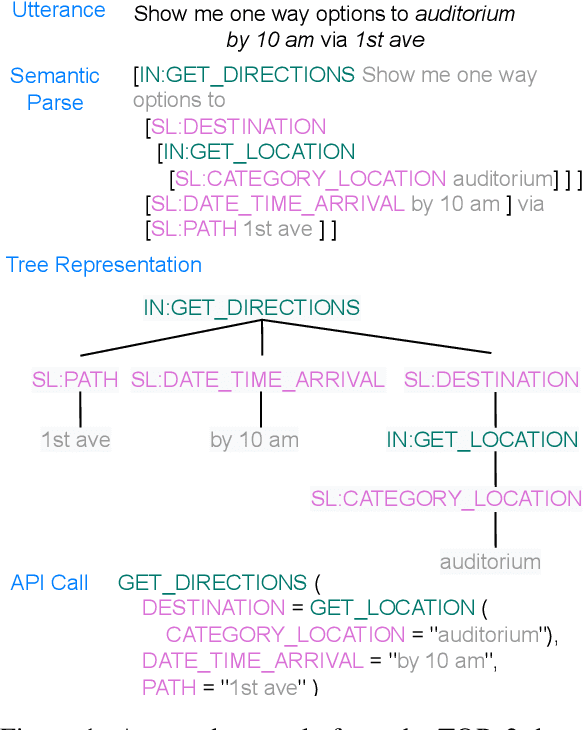
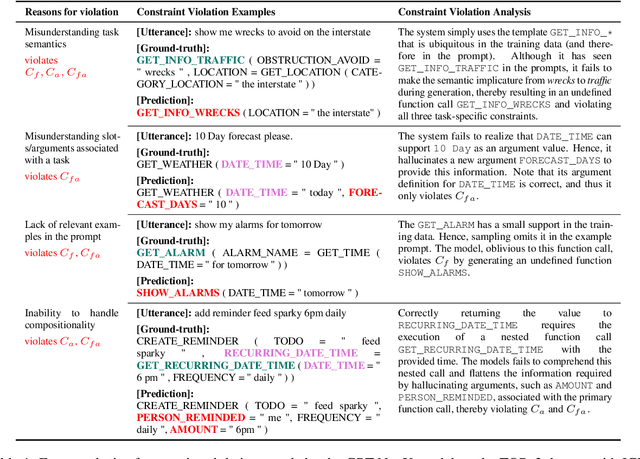
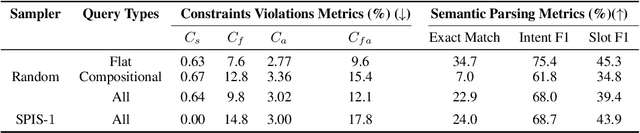
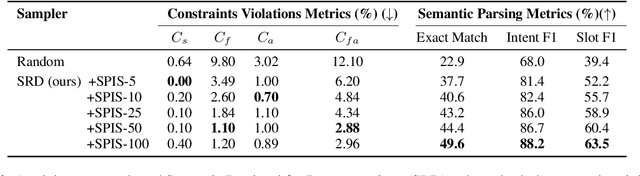
In executable task-oriented semantic parsing, the system aims to translate users' utterances in natural language to machine-interpretable programs (API calls) that can be executed according to pre-defined API specifications. With the popularity of Large Language Models (LLMs), in-context learning offers a strong baseline for such scenarios, especially in data-limited regimes. However, LLMs are known to hallucinate and therefore pose a formidable challenge in constraining generated content. Thus, it remains uncertain if LLMs can effectively perform task-oriented utterance-to-API generation where respecting API's structural and task-specific constraints is crucial. In this work, we seek to measure, analyze and mitigate such constraints violations. First, we identify the categories of various constraints in obtaining API-semantics from task-oriented utterances, and define fine-grained metrics that complement traditional ones. Second, we leverage these metrics to conduct a detailed error analysis of constraints violations seen in state-of-the-art LLMs, which motivates us to investigate two mitigation strategies: Semantic-Retrieval of Demonstrations (SRD) and API-aware Constrained Decoding (API-CD). Our experiments show that these strategies are effective at reducing constraints violations and improving the quality of the generated API calls, but require careful consideration given their implementation complexity and latency.
KNN-LM Does Not Improve Open-ended Text Generation
May 24, 2023



In this paper, we study the generation quality of interpolation-based retrieval-augmented language models (LMs). These methods, best exemplified by the KNN-LM, interpolate the LM's predicted distribution of the next word with a distribution formed from the most relevant retrievals for a given prefix. While the KNN-LM and related methods yield impressive decreases in perplexity, we discover that they do not exhibit corresponding improvements in open-ended generation quality, as measured by both automatic evaluation metrics (e.g., MAUVE) and human evaluations. Digging deeper, we find that interpolating with a retrieval distribution actually increases perplexity compared to a baseline Transformer LM for the majority of tokens in the WikiText-103 test set, even though the overall perplexity is lower due to a smaller number of tokens for which perplexity dramatically decreases after interpolation. However, when decoding a long sequence at inference time, significant improvements on this smaller subset of tokens are washed out by slightly worse predictions on most tokens. Furthermore, we discover that the entropy of the retrieval distribution increases faster than that of the base LM as the generated sequence becomes longer, which indicates that retrieval is less reliable when using model-generated text as queries (i.e., is subject to exposure bias). We hope that our analysis spurs future work on improved decoding algorithms and interpolation strategies for retrieval-augmented language models.
You can't pick your neighbors, or can you? When and how to rely on retrieval in the $k$NN-LM
Oct 28, 2022



Retrieval-enhanced language models (LMs), which condition their predictions on text retrieved from large external datastores, have recently shown significant perplexity improvements compared to standard LMs. One such approach, the $k$NN-LM, interpolates any existing LM's predictions with the output of a $k$-nearest neighbors model and requires no additional training. In this paper, we explore the importance of lexical and semantic matching in the context of items retrieved by $k$NN-LM. We find two trends: (1) the presence of large overlapping $n$-grams between the datastore and evaluation set plays an important factor in strong performance, even when the datastore is derived from the training data; and (2) the $k$NN-LM is most beneficial when retrieved items have high semantic similarity with the query. Based on our analysis, we define a new formulation of the $k$NN-LM that uses retrieval quality to assign the interpolation coefficient. We empirically measure the effectiveness of our approach on two English language modeling datasets, Wikitext-103 and PG-19. Our re-formulation of the $k$NN-LM is beneficial in both cases, and leads to nearly 4% improvement in perplexity on the Wikitext-103 test set.
Knowledge Injected Prompt Based Fine-tuning for Multi-label Few-shot ICD Coding
Oct 07, 2022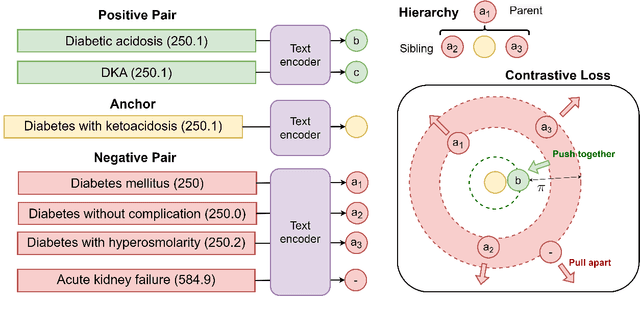
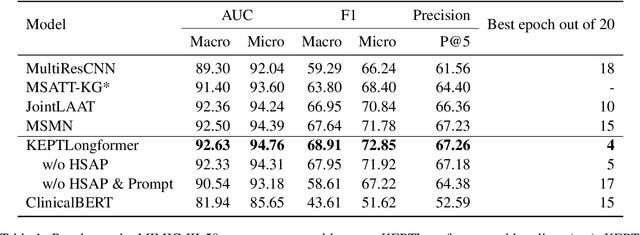
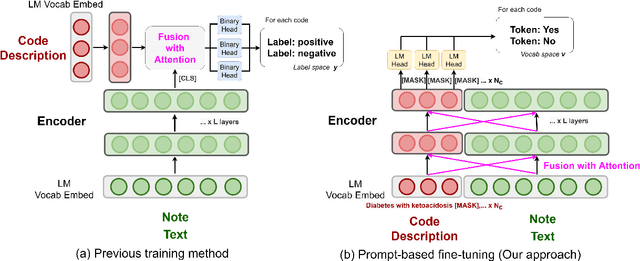
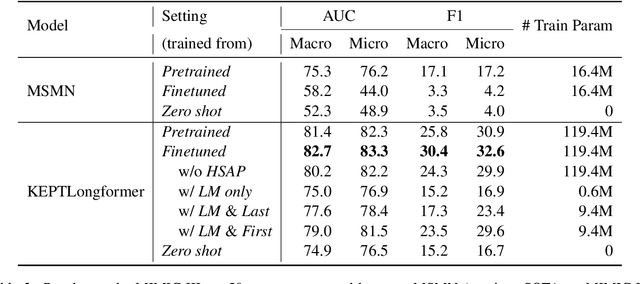
Automatic International Classification of Diseases (ICD) coding aims to assign multiple ICD codes to a medical note with average length of 3,000+ tokens. This task is challenging due to a high-dimensional space of multi-label assignment (tens of thousands of ICD codes) and the long-tail challenge: only a few codes (common diseases) are frequently assigned while most codes (rare diseases) are infrequently assigned. This study addresses the long-tail challenge by adapting a prompt-based fine-tuning technique with label semantics, which has been shown to be effective under few-shot setting. To further enhance the performance in medical domain, we propose a knowledge-enhanced longformer by injecting three domain-specific knowledge: hierarchy, synonym, and abbreviation with additional pretraining using contrastive learning. Experiments on MIMIC-III-full, a benchmark dataset of code assignment, show that our proposed method outperforms previous state-of-the-art method in 14.5% in marco F1 (from 10.3 to 11.8, P<0.001). To further test our model on few-shot setting, we created a new rare diseases coding dataset, MIMIC-III-rare50, on which our model improves marco F1 from 17.1 to 30.4 and micro F1 from 17.2 to 32.6 compared to previous method.
Modeling Exemplification in Long-form Question Answering via Retrieval
May 19, 2022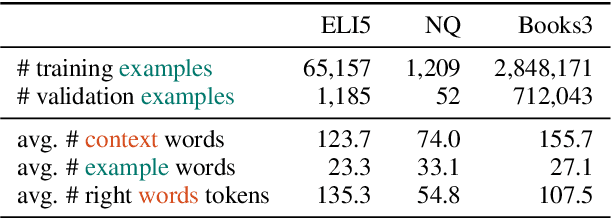
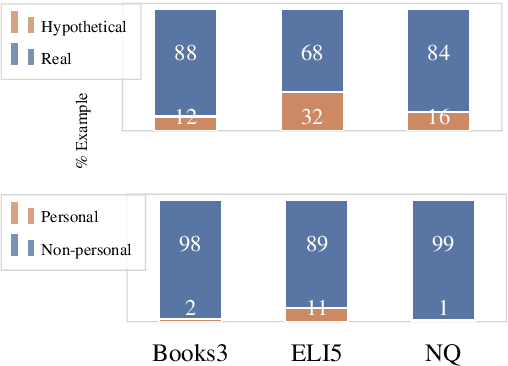
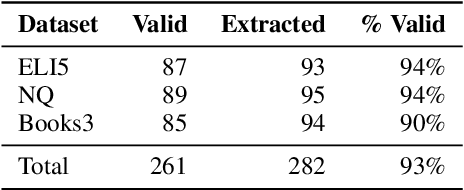
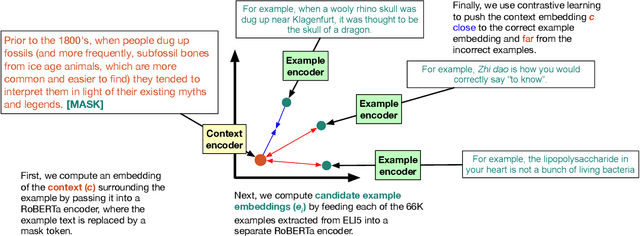
Exemplification is a process by which writers explain or clarify a concept by providing an example. While common in all forms of writing, exemplification is particularly useful in the task of long-form question answering (LFQA), where a complicated answer can be made more understandable through simple examples. In this paper, we provide the first computational study of exemplification in QA, performing a fine-grained annotation of different types of examples (e.g., hypotheticals, anecdotes) in three corpora. We show that not only do state-of-the-art LFQA models struggle to generate relevant examples, but also that standard evaluation metrics such as ROUGE are insufficient to judge exemplification quality. We propose to treat exemplification as a \emph{retrieval} problem in which a partially-written answer is used to query a large set of human-written examples extracted from a corpus. Our approach allows a reliable ranking-type automatic metrics that correlates well with human evaluation. A human evaluation shows that our model's retrieved examples are more relevant than examples generated from a state-of-the-art LFQA model.
Model-free Reinforcement Learning for Content Caching at the Wireless Edge via Restless Bandits
Feb 26, 2022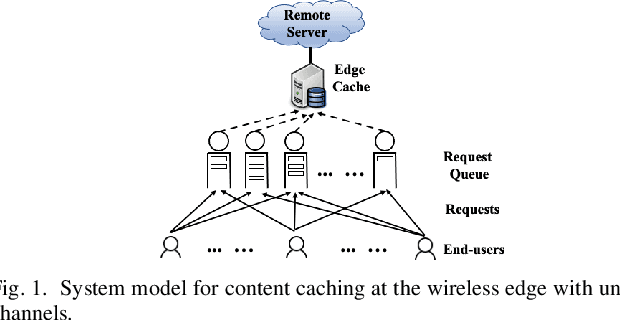
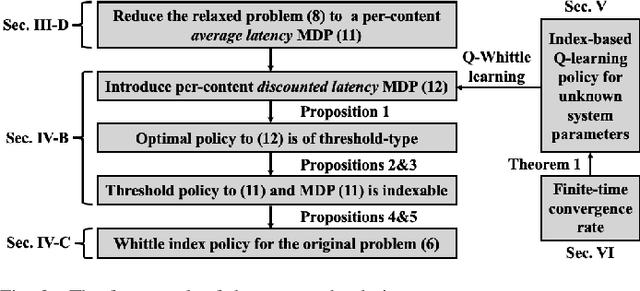
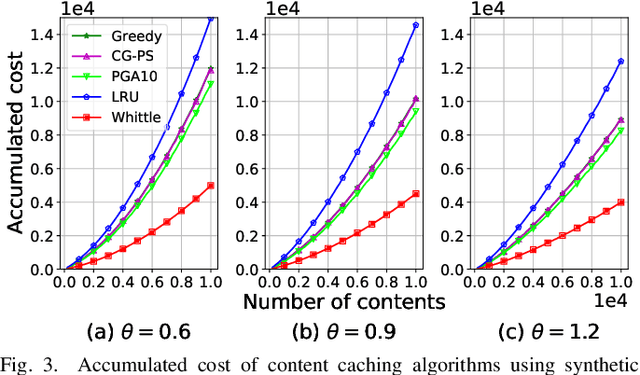
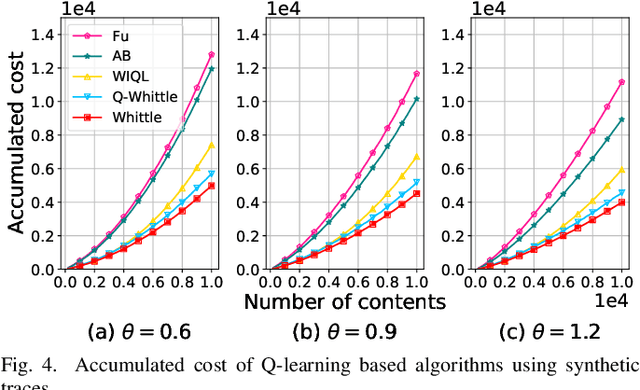
An explosive growth in the number of on-demand content requests has imposed significant pressure on current wireless network infrastructure. To enhance the perceived user experience, and support latency-sensitive applications, edge computing has emerged as a promising computing paradigm. The performance of a wireless edge depends on contents that are cached. In this paper, we consider the problem of content caching at the wireless edge with unreliable channels to minimize average content request latency. We formulate this problem as a restless bandit problem, which is provably hard to solve. We begin by investigating a discounted counterpart, and prove that it admits an optimal policy of the threshold-type. We then show that the result also holds for the average latency problem. Using these structural results, we establish the indexability of the problem, and employ Whittle index policy to minimize average latency. Since system parameters such as content request rate are often unknown, we further develop a model-free reinforcement learning algorithm dubbed Q-Whittle learning that relies on our index policy. We also derive a bound on its finite-time convergence rate. Simulation results using real traces demonstrate that our proposed algorithms yield excellent empirical performance.